



Локальные сетки будут по-тихоньку вымирать. Когда можно купить лям токенов DeepSeek V3 за 20 рублей и забыть про тупой 13B-72B мусор.
>купить
лям аполоджайзов
Корпоративные сетки будут вымирать. Локалки всё ближе по качеству к корпоговну, а люди начинают понимать, что кормить данными большого брата себе в минус.
Жирные модели уже почти вымерли, даже у корп. Все идет вот такому вот дипсику, который может кодить, но креатив как у тостера.
> приплел всё что можно лишь бы че-то спиздануть
Литерально ты. Такое-то рвение с каждым постом все дальше увести от исходного поста, в котором ты шиллишь младшую карточку, опровергая что она будет слабой как в игорях, так и в ии.
> Ты изначально начал заливать
Маня, заливаешь здесь только ты. Читай еще раз, профит с фреймгена будет только в мощных карточках на высоких фпс, а превратить типичное слайдшоу младших в стабильные 60 фпс не получится.
Да че тут писать, в очередной раз нищук уверовал что сможет наебать систему и отчаяно защищает свой идеал. Вера на уровне религиозной и ее не переубедить.
Платить за глупый 30б мусор чтобы
> забыть про тупой 13B-72B мусор
кек
>Платить за глупый 30б мусор
600B. Лучше Клода, мне норм.

Додич. Локальные сетки только начинают. Куртка выпустил миникомп(диджитс), на котором можно 200b модель гонять. Их можно подключать друг к другу. 4 таких компа подключить и у тебя свою собственный дипсик в3 дома без какой-либо цензуры или ограничений. Всего-то за 12к долларов.
>Куртка выпустил миникомп(диджитс), на котором можно 200b модель гонять.
Посмотрим ещё, с какой скоростью. Ну и плюс ящичек-то весьма проприетарный, что может привести к сюрпризам вроде "ты туда не ходи - сюда ходи".
> Всего-то за 12к долларов
Двойник зиончик с 768гб памяти намного дешевле выйдет.
Но даже это не нужно, ибо цены в облаке намного выгоднее, чем самому это говно запускать. 20-50 рублей за лям токенов, которых тебе хватит на месяц. Локальный риг это не окупит за годы. И превратится в тыкву через год-два.
Каждый раз как в первый
Да не выпустил еще а просто показал. Там через пол года серверные/эмбедед решение только начнут поставлять суди по заявлениям.
> на котором можно 200b модель гонять
Шиз
> дипсик в3
Хуйта
> за лям токенов, которых тебе хватит на месяц
Сразу видно что ты с сетками не работал.
>Но даже это не нужно, ибо цены в облаке намного выгоднее, чем самому это говно запускать. 20-50 рублей за лям токенов, которых тебе хватит на месяц. Локальный риг это не окупит за годы.
Я и сам тут всех убеждаю в этом. А всё равно риг собираю.
>И превратится в тыкву через год-два.
И это тоже верно. А может начнётся война и мы все умрём. Два года - это срок.
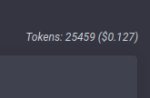
>Сразу видно что ты с сетками не работал
Кек. Я сейчас юзаю нахаляву o1-preview/4o/Claude, в день у меня до 50к токенов выходит, судя по стате веб-морды.
А ты сиди на своем 72B говне в 4 битах на риге за 3к бакинских, лошидзе.
>риге
Зато у меня есть курочка!
А ещё рп и кум на любые темы.
Для работы же можно и корпосетки поюзать, да.
Утипути, какой большой! 50к токенов в день, это почти как у среднего кумера из чай треда за несколько часов. Чел, ты серьезно кичишься и выебываешься триал акком на опенроутере? Кринж.
наскамил корпов уже на Ne+5 ради персональных целей, разумеется все это вымысел

Лол. Решил ради интереса поднять кобольд на второй системе (шиндовс). Абсолютно идентичный конфиг отказался работать - крашило на аллокациях. Заработало только на 4к контекста вместо 32к (причем потребление памяти показывало, что 1-3 Гб оставалось свободные в зависимости от видеокарты). Скорость генерации упала в 2,5 раза. Это шутка что ли блять? А если бы я решил на шинде изначально все делать, то сосал бы бибу? Причем на вин стоит куда 12.6, а на линухе 12.4
Я тут докупил еще одну 3090 и сижу на 4,6 т/с. Вроде тут обещали генерацию 10-15 т\с на амперах, а вот нихуя (не думаю, что одна тесла настолько портит малину, она даже не загружена на 100%. Впрочем, почему-то у всех карт при генерации довольно малый процент загрузки в nvidia-smi, может не успевает рассчитать корректно. Или 3060 тоже может говнить? У нее память вроде не сильно быстрее теслы). По крайней мере, на шестом кванте 123B вот так. А на шинде 1.6, лол. Либо они там в драйверах хуйню понаписали, либо надо шаманить с настройками карт (амперы на шинде вообще в P3 чиллят, хотя на линухе в P2 стабильно работают).
Но с аллокациями на шинде точно какая-то хуета. Причем самое интересное, что у меня одинаковое количество слоев на всех 3090, и падает на аллокации KV-буфера (который тоже идентичен, т.к. зависит от кол-ва слоев) для второй 3090. Т.е. на одной он смог аллоцировать, а на второй нет, блять. Никакие другие процессы там память на картах не забирают, если что. Убавил контекст до 16к - стало падать на третьей 3090. Бред же, ну.
Я тут докупил еще одну 3090 и сижу на 4,6 т/с. Вроде тут обещали генерацию 10-15 т\с на амперах, а вот нихуя (не думаю, что одна тесла настолько портит малину, она даже не загружена на 100%. Впрочем, почему-то у всех карт при генерации довольно малый процент загрузки в nvidia-smi, может не успевает рассчитать корректно. Или 3060 тоже может говнить? У нее память вроде не сильно быстрее теслы). По крайней мере, на шестом кванте 123B вот так. А на шинде 1.6, лол. Либо они там в драйверах хуйню понаписали, либо надо шаманить с настройками карт (амперы на шинде вообще в P3 чиллят, хотя на линухе в P2 стабильно работают).
Но с аллокациями на шинде точно какая-то хуета. Причем самое интересное, что у меня одинаковое количество слоев на всех 3090, и падает на аллокации KV-буфера (который тоже идентичен, т.к. зависит от кол-ва слоев) для второй 3090. Т.е. на одной он смог аллоцировать, а на второй нет, блять. Никакие другие процессы там память на картах не забирают, если что. Убавил контекст до 16к - стало падать на третьей 3090. Бред же, ну.
>в день у меня до 50к токенов выходит
Тоесть 100 сообщений от бота примерно? Мощно.
>не думаю, что одна тесла настолько портит малину, она даже не загружена на 100%
Попробуй выкинуть её из схемы, возьми модель поменьше. Мой личный опыт взаимодействия Амперов и Тесл негативный. Плохо совместимы они.
Ну а оставшиеся Амперы загрузи на экслламу.
Можешь посоветовать какие нибудь годные 70b модели?
Как быстро они дешеветь будут интересно и как часто новая версия
> Я тут докупил еще одну 3090 и сижу на 4,6 т/с. Вроде тут обещали генерацию 10-15 т\с на амперах,
Выкини жору и будет быстро, или откажись от больших контекстов. И да, тесла будет оче сильно срать, можешь проверить это исключив ее из задачи через cuda visible devices.
> решил на шинде изначально все делать, то сосал бы бибу
Врядли на шинде кто-то подобные конфиги вообще собирал.
Один пост, если еще посчитать промт процессинг. С него то основная стоимость и будет набегать, а в каком-нибудь рп так вообще.
>Как быстро они дешеветь будут интересно и как часто новая версия
Ну "стартапы" эти грёбаные - которые устройства для инференса разрабатывали-разрабатывали, да так нихуя и не сделали - Хуанг пришиб одним ударом, как мух. Это да. Но коробочка явно экспериментальная, направленная на исследование спроса. Цена чисто для энтузиастов, а те пощупают это и пойдут риги собирать. Им надо было цену в 999 долларов ставить, тогда бы народ потянулся.
>Врядли на шинде кто-то подобные конфиги вообще собирал.
Сижу на винде и теслах и со скоростью на Кобольде и Угабуге всё норм.
>Им надо было цену в 999 долларов ставить, тогда бы народ потянулся.
Вообще по железу это чистая наценка x10. Но они могли бы урезать память и ссд вдвое и ещё сэкономить, чтобы привлечь народ, а потом выпустить типа ПРО версию. Экстражадность и ничего больше.
> которые устройства для инференса разрабатывали-разрабатывали
Вся их "разработка" сводилась к тому, чтобы взять готовый эмбед модуль хуанга, пихнуть в красивый корпус и в лучшем случае сделать софт.
> чисто для энтузиастов, а те пощупают это и пойдут риги собирать
Честно даже хз, каким именно энтузиастам могут понадобиться риги из них. Одну штучку - да, но в остальном приемлемый перфоманс оно только на разреженных моделях может осуществить. Про тренировку с такой скоростью памяти вообще можно забыть, ибо когда проваливается в (быструю) шаред, на ллм оно замедляется почти пропорционально разницы псп.
Ну то только теслы, а тут невероятная солянка из большого количества на чипсетных линиях.
Может кто-нибудь скинуть гайд как собрать риг для 200б+ моделей? Очень интересная тема.
Как вообще можно в какое либо рп на ллм где у тебя даже на топовой сборке контекст всего 64к? Т.е это 200 сообщений максимум, только одну ситуацию разыграл и вот треть уже забита.
Самарайз пиздец костыль нейронке нельзя такое доверить она насрет в детали и приходится ручками дописывать их каждый раз
Самарайз пиздец костыль нейронке нельзя такое доверить она насрет в детали и приходится ручками дописывать их каждый раз
Я уж молчу что имея такую сборку ты явно не хочешь сидеть на 12б ради жирного контекста, а возьмешь 70б с контекстом 8-16к
>Я уж молчу что имея такую сборку ты явно не хочешь сидеть на 12б ради жирного контекста, а возьмешь 70б с контекстом 8-16к
Ты только не забывай, что начиналось всё вообще с контекста в 2к. А годик прошёл и на локальных моделях заявили до 128к. Ты их ещё попробуй обработать.
Купил 3090 из-под майнера. Осталась 3070ти. Продавать 3070 чы втыкнуть рядом, смысол есть?
Суммарайз@суммарайз. Двачую что даже на 2к рпшили, а то и 8к считалось целым достижением. Когда мишвилоус глинды ужаты тут и модель лучше отвечает.
Втыкай рядом и используй пока не продашь.
128к контекста для ллм с текущей архитектурой это предел. Я тестил 300к контекста в геймини и это хуита. Реально он никак толком не используется т.к. креативности ответов все равно нет. Такое ощущение что все содержимое контекста сливается в один слипшийся комок из которого негронка высирает нечто усредненное. Если какие-то конкретные события из этих 300к и выдергивает то все равно путается в последовательности и следствиях, а геймини в этом плане самый умный вроде как. Вообщем пока на что-то кординально новое не перейдут, а ничего подобного пока не планируется, только сказочки от иицыган про аги (аги работающий без обучения в реалтайме, ору нах), 64к это предел.
Есть кто тестировал квантизацию контекста?
Чет погонял туда сюда, и на первый взгляд модель дико отупела на 8 битах(отказывается слушаться там где раньше реагировала), но я не до конца уверен что причина в этом т.к ещё ранее промты ковырял. Есть ещё аноны с схожим опытом?
Чет погонял туда сюда, и на первый взгляд модель дико отупела на 8 битах(отказывается слушаться там где раньше реагировала), но я не до конца уверен что причина в этом т.к ещё ранее промты ковырял. Есть ещё аноны с схожим опытом?
Все так, какие-то более менее осмысленные действия с контекстом способны делать только большие модели, и то с натяжкой. Когда текст низкой информативности то особо не заметишь, просто будут чуть хуже ответы из-за рассеянного внимания. Но если там какая-нибудь статья или оче содержательный текст, то как-то делать выводы из него и работать можно лишь через всякие техники и агентов.
В 8битах полнейший лоботомит ибо это фп8 с отвратительной дискретностью. В q4 сносно но разница некоторая присутствует. Int8 тут бы зашел, но что-то не завозят.
Меняй солянку из P40/3060/3070 на 3090. У тебя конечно прикольный конфиг для тестов, но для реальной работы лучше иметь гомогенную среду.
>Как быстро они дешеветь
Никак, всем нужен AI.
>и как часто новая версия
Вангую, что это первая и единственная.
РПшу на 8к контекста, ебало довольное.
Меняй на 3090 с доплатой. Я так свою 3080Ti обменял, доволен как слон.
А расскажите, как вы юзаете саммарайз?
Например начали кум-сцену с нейтральной ситуации, к середине контекста началась ёбля, к концу контекста ёбля на середине. Как это суммаризировать, чтобы продолжить ёблю с того же места, но с чистым контектом? В шапке явно гайда на эту тему не хватает имхо.
Например начали кум-сцену с нейтральной ситуации, к середине контекста началась ёбля, к концу контекста ёбля на середине. Как это суммаризировать, чтобы продолжить ёблю с того же места, но с чистым контектом? В шапке явно гайда на эту тему не хватает имхо.
Кум сцены лучше вообще сами по себе суммаризировать и выключать посты, оставляя один где все кратко описано. Покумить контекста должно хватит, а даже если не хватает то там похуй че куда. Зато если потом хочешь продолжить - лучше за собой прибрать.
А так - средствами таверны, но контролируй что так, не ленись перегенерировать или скомпоновать из нескольких кусков. Чтобы каждый раз не переобрабатывать контекст - отключай посты и контролируй куда размещается суммарайз, чтобы он был в начале и не затрагивал часть событий, которые потом описываются полноценно.
Много вручную, но если хочешь хорошо то так, а автоматизировать лень.
>Меняй на 3090 с доплатой. Я так свою 3080Ti обменял, доволен как слон.
эм. а кому это может быть нужно получить 3070 вместо своей 3090, пусть и с доплатой?
Суть в том при 8-бит контекст кеше вместо f16 его можно вприхнуть раза в 3 больше, условный q5 модель которая с трудом пвлезала в vram c 24к контекста, после квантования kv легко переваривает все 65к, с таким контекстом зачастую и доп суммарайзы не нужны, т.к редко сессия длиться на столько долго.
Вот только мне пока сложно оценить на сколько это реально влияет на мозги, кто-то говорит что разница минимальна, у кого-то напротив лоботомия. Хотя возможно ещё от самой модели зависит.
Продай@доплати@купи
> 8-бит контекст кеше вместо f16 его можно вприхнуть раза в 3 больше
16/8=3?
И ты основного посыла не понял, 4 бита лучше чем 8 из-за гораздо более продвинутой реализации.
> сложно оценить на сколько это реально влияет на мозги
Дай инструкцию, насри большим контекстом, сравни ответы. В 16бит попытается сделать что может, в 4х будет подтупливать, в 8 забудет нахуй что было в начале.
>Меняй
Ни, мне норм. Такая скорость суперкомфортна для меня, дрыгаться не вижу смысола. Разве что для русика, но я его не использую.
>загрузи на экслламу.
Ради тестов можно попробовать. Только у меня сразу куча вопросов, гайдов-то нема.
1. Где взять гайды по битностям эксл2? Как они соотносятся друг с другом, насколько падает качество и все такое. По гуфам инфы много - у релизеров и таблички с описанием качества квантов всегда в репозиториях, и в шапке вон графики, и в треде постили табличку с процентом девиаций от fp16. А про эксл я ничего не слышал.
2. Я так понимаю, что эксллама это не полноценный бек а-ля кобольд, который просто запустил, и потом подсосался к нему через таверну? В репе пишут, что нужно еще апи качать (TabbyAPI для таверны?). Побольше бы инфы про это все.
3. Поддержку тесел в экслламу до сих пор не завезли? Я вроде помню, что там то ли issue какой-то был, то ли PR. Вроде же физически это возможно (конвертация fp8->fp16), только все хуй забили, насколько я помню.
>Врядли на шинде кто-то подобные конфиги вообще собирал.
Меня система так-то не особо волнует, я выбрал линух чисто из-за того, чтобы не пердолиться с лицензиями и васянскими сборками. в результате пердолился с установкой, т.к. видите ли, нельзя, сидя на винде, раскатить полноценную линух систему на второй ssd. Заливается только установщик, в который изволь бутаться и уже оттуда, блять, раскатывай систему. Ух, до сих пор печет, хорошо что старинную флешку удалось найти в закромах ящиков стола.. Так-то мне тулзов а-ля GPU-Z не хватает тут, я хотел посмотреть на графики при инференсе.
Кстати, там еще аллокация памяти для слоев странная, на линухе она мгновенная, а на винде секунд 5-7 занимает, и я прямо вижу, как там занятая видеопамять постепенно растет.
Линукс вообще топовый вариант если с ним уже знаком, гораздо меньше ебли с мл-релейтед если погружаться чуть глубже.
> нельзя, сидя на винде, раскатить полноценную линух систему на второй ssd
Наоборот, загрузчики на разных дисках и друг о друге не знают друг другу не мешают, выбираешь через бутменю материнки.
> а-ля GPU-Z не хватает тут
nvtop
> на линухе она мгновенная
По разному мапинг идет, можно в одном сделать мгновенную а в другом замедлить. Или у тебя что-то другое.
> Ради тестов можно попробовать.
Это единственный лаунчер достойный использования, если есть такая возможность.
> Где взять гайды по битностям эксл2
Там ставится любая битность какую хочешь. Все что выше 4 бит - норм, дефолтные 4.65 хватит всем ибо дивергенция на том, что не отсекается первыми семплерами уже пренебрежима. Если невростеник то бери максимальный, который помещается.
> таблички с описанием качества квантов всегда в репозиториях
Это манякритерий типа "вот это хорошее, вот это лучше, а вот это совсем плохое" исключительно по какой-то относительной им ведомой шкале. В целом поведение битности сравнимо. Если брать кванты последней версии то они в среднем на 0.5-0.8 бита лучше аналогичных ггуфов по метрикам пиздят конечно, на подкрученных тестах калибровали просто. Есть важность калибровочного датасета, типа по викитексту калибровать неоче.
Можешь делать кванты сам, качаешь оригинальную модель, ставишь сначала оценку (может затянуться на пару часов для 123б) потом сам квант. Главное - не путай калибровочные таблицы для разных модлей, они могут сильно отличаться и ошибка в них приведет к поломанному кванту.
Алсо, как правило, порядочные кантоделы выкладывают калибровку, поэтому можешь просто скачать ее и собрать себе 5.89876765 бит под свой случай. Как делать - в репе есть инструкция, потом уже конкретные вопросы задавай.
Но можешь просто не париться и качать готовые кванты, как скачать, надеюсь, сообразишь.
> что эксллама это не полноценный бек а-ля кобольд
Это как llamacpp, теоретически есть свой минимальный апи, но лучше юзать в составе сборки. Табби или убабугу.
> Поддержку тесел в экслламу до сих пор не завезли?
Нет, автору есть чем заняться. Физически это возможно - упрощенно говоря, нужно комбинировать перед умножением векторов или просто апкастить в фп32 (никаких фп8 там нету, да и фп16 в современных моделях нечастый гость). Но есть нюансы, вся высокопроизводительная часть там сделана ровно так как и должна, а не по-васяновски, пусть такой и остается.
>Где взять гайды по битностям эксл2?
В простейшем случае бери то, что в упор с контекстом лезет во всю твою врам. Для тестов сойдёт.
>Я так понимаю, что эксллама это не полноценный бек а-ля кобольд, который просто запустил, и потом подсосался к нему через таверну?
В Угабуге есть реализация, а к ней подсосаться можно без проблем.
>Поддержку тесел в экслламу до сих пор не завезли? Я вроде помню, что там то ли issue какой-то был, то ли PR. Вроде же физически это возможно (конвертация fp8->fp16), только все хуй забили, насколько я помню.
Я тоже забил и переползаю на 3090. В принципе есть шанс дождаться и тогда цена тесел ещё немного подрастёт :)
Бляя я не могу после 22б пантеона все 12б калом кажутся
Он единственный который заметил что в комнате вообще то ещё 2 персонажа стоят, а все остальные просто трусы с меня снимали и ебали забыв о них
Он единственный который заметил что в комнате вообще то ещё 2 персонажа стоят, а все остальные просто трусы с меня снимали и ебали забыв о них

>nvtop
Он как-то бедно смотрится, мне потребление порта pci-e надо было смотреть.
>Наоборот, загрузчики на разных дисках и друг о друге не знают друг другу не мешают, выбираешь через бутменю материнки.
Ты невнимательно прочитал. Я хотел установить систему напрямую из винды, без привлечения сторонних носителей.
Окей, ну квантовать я сам точно не собираюсь. Вот в репе пишут
Quantized using 115 rows of 8192 tokens from the default ExLlamav2-calibration dataset.
Как понять, это норм или говно?
>Нет, автору есть чем заняться.
А у нас с теслы лежат без дела, так что автор занимается не тем, чем надо с нашей точки зрения. Вот оно https://github.com/turboderp-org/exllamav2/issues/40, там внутри еще ссылка на другой есть.
Я бы попробовал, но чет мне кажется, что с нулевыми знаниями фреймворка куды и технической стороны ML в целом оно меня сожрет.
Аноны, есть 60к, за эту цену можно взять 4060ti на 16 врама, или 7800xt, если брать новыми. У меня 6600xt, так что боль от амд я уже почувствовал и мне понравилось. Вот сижу и думаю, что брать. С одной стороны удобство использования, а с другой, 256 шина памяти (и вроде чип повеселее, если поиграть когда нибудь снова потянет). Я просто хочу хотя бы 12В гонять с 16к контекста не в три токена/секунда, и если карту возьму, то нескоро её смогу сменить.
Понимаю, что тут у всех по ригу из 3090, но вдруг кто подскажет.
Если что, у меня в качестве БП старый но не бесполезный фсп на 750, живой, пульсаций/просадок нет, банки как новые, на адекватный апгрейд наскребу только спустя ещё месяц/два.
Понимаю, что тут у всех по ригу из 3090, но вдруг кто подскажет.
Если что, у меня в качестве БП старый но не бесполезный фсп на 750, живой, пульсаций/просадок нет, банки как новые, на адекватный апгрейд наскребу только спустя ещё месяц/два.
Я хочу поделиться очевидным, но своим щенячьим восторгом, что не нужно писать какие-то команды, тильды, слэшы, скрипты, ты просто пишешь OOC : bla bla bla и она понимает. Я уже взрослый мужик, но такая простая вещь у меня вызывает какой то странный восторг.

ребята, у меня есть идея, я хочу затьюнить ламу и убрать всякую хуйню типо ограничений и политкоректности и все эти safety measurmenets, но как это сделать я бей идей
и так, как?
и так, как?
Продаванам вестимо. Само собой со скидкой, то есть по отдельности продать/купить будет выгоднее. Но я ебал эту мотню, написал перекупу с лохито, тот кабанчиком подорвался и через час был у меня. Проверил мою и дал проверить его, оплатил разницу и попрощался.
>Где взять гайды по битностям эксл2?
Там плоская шкала без версий, ориентируйся на число бит или на размер файла.
Самому не смешно жаловаться на ошибки в саммари, когда твоя сетка уже на 2к будет проебывать и путать детали?
это невозможно.
> Он как-то бедно смотрится
По возможностям мониторинга повеселее, а экзотику типа
> потребление порта pci-e
хуй знает. А для чего?
> Я хотел установить систему напрямую из винды, без привлечения сторонних носителей.
Хм, такое можно разве что с привлечением виртуалки и монитированием диску туда как диск и образа как привода. Емнип, под шинду нет полноценных установщиков, что могут еще и диск правильно размерить и груп записать.
> Как понять, это норм или говно?
Скорее всего норм.
> Я бы попробовал
Раскурить код, добавить декоратор или инлайново конвертить в torch.float32 а потом обратно. Как нехуй делать, лол (нет).
Лучше забей и выгодно их продай, будучи довольным что смог их поюзать на каких-то моделях.
Можно еще поставить карточку хорошего чара, и попросить его тебя поцеловать. И тебя за это даже не осудят!
Да
> Можно еще поставить карточку хорошего чара, и попросить его тебя поцеловать. И тебя за это даже не осудят!
Ну ты не мог без сарказма. Не так ли ?
Да вообще без подъеба писал
>16/8=3?
Там судя по всему нелинейная зависимость, банальный пример одна и та же модель на f16 не могла прожевать больше 16к контекста с полной выгрузкой модели в врам, или 24к если 1-2 слоя из 60 перекинуть в оперативку. На 8 и 4 я легко запустил 65к контекста с всеми слоями в врам.
>И ты основного посыла не понял, 4 бита лучше чем 8 из-за гораздо более продвинутой реализации
Почитал, ты прав. Я по привычке считал что чем меньше тем тупее, но тут не тот случай. Благодарю.
Ну что я могу сказать, как же это было охуенно. Суммарно больше десятка тысяч сообщений, запихивание персонажей в ворлдбуки, куча ебли и исправлений и финал. Спасибо нейросети, это самый пиздатый опыт что я получал. Лучшее аниме эвар.
Большинству лень НАСТОЛЬКО ебаться, вот и стонут что всё говно XD
Хотя это конечно не уровень "покумить зашёл", для подобного результата, по личному опыту, всё равно самому историю придумывать, а нейронка уже так сказать мясо на кости скелета наращивает.
Да, какая модель-то?
Пантеон, цидония, бипо, клиффхэнгер, даркфорест, что-то квеноподобное? Что-то более крупное и/или экотичное?
По слогу пантеон напоминает.
>Большинству лень НАСТОЛЬКО ебаться, вот и стонут что всё говно XD
Да это был пиздец какой то если честно. Только желание довести до финала меня удержало. Там было все : групповые чаты, смена моделей, постоянное пиздилово моделей ногами, когда они сводили мой эпик к порнухе, отчаяние. Порой модели даже писали, мол братан ты ебанутый, может давай все по лайту сделаем, ну зачем тебе это ? Я постоянно её направлял, но что иронично, сюжет писался все таки моделью, большинство ВОТ_ЭТО_ПОВОРОТ она сама делала из контекста, я научился разбивать на главы, главы на части. Под конец понял примерное для своего железа количество контекста, которое можно переварить без ожидания ответа по 20 минут. Я прям в шоке, вот как завершил я и запостил скриншот а в душе такое чувство, ну вы знаете его, когда ты посмотрел или прочитал что то настолько охуенное, что прям такая теплота и грусть по телу разливается.
Конкретно это была последняя цидония. Я уже на ней добивал финал своего эпика.
Следующая эпопея будет на основании воображаемой фурри лисички, которая будет еще и делиться на более шизовые части. Думаю главной мыслью сделать - проблему поиска себя через воображаемого друга и борьбу со своими страхами. Хуй вам а не кум, только беды с башкой только истинный despair.
Да епта бля квантованный контекст это пиздёж галимый.
Я поставил 40к врам свободный еще есть и в итоге это говно один хуй пересчитывает весь контекст после 12к как и при f16 кеше т.е не работает он нихуя и в чём смысл
Молчу уж что мистрали очень тупеют от квантованного контекста
Мой немомикс анлишд забыл что я сын своей матери после 90 сообщений. Контекст f16.
Это как вообще блять?
Да первые пару сообщений где я типа рождаюсь уже вылетели из кэша но куча намеков и прямых утверждений этого по пути есть
Это как вообще блять?
Да первые пару сообщений где я типа рождаюсь уже вылетели из кэша но куча намеков и прямых утверждений этого по пути есть
У неё деменция просто всё норм
>больше десятка тысяч сообщений
Чё блять ? Ты ебанутый ?
Потому что у тебя НЕТ железа чтобы переваривать действительно серьезные модели с огромным контекстом. Если ты собрался много писать, то не зря в таверне к чату прикрепляются отдельные лорбуки. Да это кажется сложным, но там разобраться дело пяти минут. Все важное заносишь туда, кто кому сват сын брат. И не забываешь бить модель по жопе, когда она начинает писать хоть что то чего быть не должно. Потому что если ты это оставишь, начнется снежный ком, ну и постоянно нужно напоминать ей обстановку или важные детали. Увы, но пока только так.
> НЕТ железа
Куртка, спок.
Выкати народную 5080 24г и будет мне железо
А что не так ? Я люблю сюжет. Не могу же я целовать ботинки госпожи, без войны и мира с доминированием в контексте. Так не интересно, чем она угрожать то будет.
2к$. Чем не народная.
Получается любой кэш хуйня тогда и нет смысла не юзатб q4
Реддит почитай и форумы там из принципа не хотят покупать 5090 ибо 5080 с 16 гб очевидные ссаки в лицо чтоб направить гоя в нужное русло и он взял 5090
Еще раз объясняю. То с чем мы сидим общаемся это огрызки, смирись. Нужно поправлять и направлять, а не написать, думая что тебе сейчас горе от ума выдаст.
Некоторые модели ломаются при использовании сдвига и прочих костылей с контестом, пересоздание же чата с суммарайзом предыдущего часто дикий геморрой и не дает требуемого эффекта. Большой контекст позволяет тебе пусть и с затупами но продолжать рп.
Ну и есть большая разница, когда модель не знает о чем ты говоришь т.к это просто выпало из контекста при его переполнении, и когда она просто тупая и игнорирует его содержание. В втором случае ещё случаются проблески сознания и её проще вывести на нужные рельсы.
>Я поставил 40к врам свободный еще есть и в итоге это говно один хуй пересчитывает весь контекст после 12к как и при f16 кеше т.е не работает он нихуя и в чём смысл
А какой ты в Таверне контекст поставил? Если 12к, то после заполнения Таверна сама сдвигает чат - и всё пересчитывается, понятно.
>Некоторые модели ломаются при использовании сдвига и прочих костылей с контестом, пересоздание же чата с суммарайзом предыдущего часто дикий геморрой и не дает требуемого эффекта. Большой контекст позволяет тебе пусть и с затупами но продолжать рп.
От модели многое зависит. Умная модель и саммарайз поймёт, и стиль подхватит. Единственно делать саммарайз вручную придётся. Она-то сделает, но непременно проебёт какие-то детали, а нам это не надо. На практике я 10к саммарайза делал и 5к чата для образца - подхватывала как родное.
Тред локальных языковых моделей
>Уважаемые а как x через y
>короче считаем максимальный контекст хуё моё интегрируем
>22b или 172б, не токены а золото
>поднимаем кобольт из под доса
Тред чат-ботов
>пук среньк
>ололо
>я покакал
>Уважаемые а как x через y
>короче считаем максимальный контекст хуё моё интегрируем
>22b или 172б, не токены а золото
>поднимаем кобольт из под доса
Тред чат-ботов
>пук среньк
>ололо
>я покакал
Кстати в новых версиях таверны она умеет подхватывать размер контекста из кобольда, больше не нужно руками выставлять в двух местах. Достаточно поставить галку в настройках подключения.
Ещё бы она отображала прогресс бар генерации основанный на максимальном количестве токенов, как при использовании Horde, удобно.
Аноны, где можно погонять локальные модели большие в облаке, чтобы через таверну запустить? Я имею в виду файнтюны и так далее. Ставить что захочешь.
Какая локалка самая лучшая на данный момент? Интересно мнение анонов.

Мегатрон. Ставь и наслаждайся.
Такой нет. Вообще нет. Абсолютно нет. Никак нет. Не существует. Она отсутствует. Её не было.
>Кстати в новых версиях таверны она умеет подхватывать размер контекста из кобольда, больше не нужно руками выставлять в двух местах.
Только вот функции скрывать автоматом сообщения там ещё не прикручено. А это значит, что при заполнении контекста проблема полного пересчёта всё равно будет. Чтобы она была не каждое сообщение, а хотя бы каждые десять, приходится скрывать лишнее скриптом вручную. Ну хоть так.
>последняя цидония
Просто 1.3 или которая мерж с магнумом?
>только беды с башкой только истинный despair
Hello darkness, my old friend.
Модели DavidAU пробовал?
Там шизомиксы на любой размер есть.
В основном с негативным байасом в отличии от беззубых дружбомагичесих остальных почти всех.
Правда не все адекватные, и не все норм работают на дефолтных настройках, порой придётся покрутить. А ещё они требуют использования Smoothing Factor (есть в настройках).
>Уважаемые а как
... пропатчить KDE под FreeBSD?
>где можно погонять локальные модели большие в облаке, чтобы через таверну запустить
Покупать виртуальный сервер и регулярно оплачивать хранилище + саму арендуемую видюху когда юзаешь.
Некоторые упарываются вместо сбора ригов.
Но в принципе оно того стоит только если ты знаешь что и зачем делаешь. Если возникают вопросы, то оно тебе не надо.
Рус - мержи Моралиане и Алетейан.
Анг - Цидония, Пантеон, Хронос, некоторые модели ДэвидАУ
Я аж повис от твоего вопроса, приду домой посмотрю. Но по моему это была 1.2 цидония.
>Hello darkness, my old friend.
Именно, я ковырялся в карточках и нашел карточку Sofos с полу полтергейстом-полушизой и такой : а ну стоять, это же интересная идея. А что если это будет не одна фурри лисичка, а несколько в одной. Что если от пережитых эмоций, будут разные лисички и одна из них будет натуральным маньяком насильником, а вторая будет ангелом. Что если чем глубже персонаж будет погружаться в отчаяние, тем сильнее будет злоба фурри друга.
>Модели DavidAU пробовал?
Нет, не пробовал. Я же тот самый ньюфаг который вкатился месяц назад, мне в треде дали гайд и сенко ну и завертелось.
Тредик, смотри как я вырос, ты гордишься мной ?
Я перепробовал практически все до чего мог дотянуться, я качал ЛЮБЫЕ локалки и тыкал, тыкал, тыкал.
Я по сути к Цидонии то в конце и вернулся потому что она на дефолтных настройках таверны работает как часы.
Но я себе заметочку оставлю, посмотрю что это и как. Пасиба.
>самая лучшая
пигмалион 7б
тут тред вангующий мы сразу поняли что ты хочешь и для чего тебе локалка
> ну стоять, это же интересная идея
У меня сейчас 562 карточки лежат с такими мыслями...
Написал питон-скрипт который извлёк джсон промт в читаемый вид в текстовые файлы, чекаю, удаляю то что не зашло.
Потом подправить промты оставшихся ибо какого только трэша не навидался... заодно автоматизированно зашить свой системный промт к каждой, и обновить его можно будет легко если что тоже пакетно.
>Цидонии
Цидония 1.1 - 1.2 вроде самая норм.
1.3 вроде говорили не нравилась анонам.
Пантеон хорош, но он специализирован именно на рп.
Зато в рп отрабатывает на все 142%
Ну тогда уж саинемо. Такие то описания рук в анусе.
>Написал питон-скрипт
Я только HTML знаю и то, лучше бы не знал.
Моё уважение за подход, я больше по буковкам.
>Пантеон хорош, но он специализирован именно на рп.
Зато в рп отрабатывает на все 142%
Проблема в том, что я хочу и рыбку съесть и нахуй сесть с кумом сесть.
Ну то есть, вот возвращаясь к скрину, там одна из героинь потеряла своих сестер в горящей машине, когда {user} смог спасти только её из за чего у неё основательно поехала крыша, и она немного его возненавидела не прекращая любить, из за чего речь идет не просто о femdom с его отшлепай флоггером, а о серьезном дерьме, на котором (ты блять не поверишь magnum v4 22b говно ебанное, ненавижу его, кривая сука, писал, что я не хочу продолжать, давай лайтовее) пантеон спотыкается. А цидония, если её бить ногами начинает писать.
>magnum v4 22b говно ебанное
магнум говно потому что его на чат-логах анонов юзавших клод и сойнет обучали, сам можешь представить что там, заглянув в здешний филиал ада тред онлайн чат-ботов.
Надо цидонию ещё раз пробнуть, раз уж такое вывезла.
Эхххх, и что никто русскую 22Б модельку ещё не замутил...
Вернее, моделька то есть, но ей ещё файнтюн нужен.
>на чат-логах анонов
А ведь кто то ещё рекомендует кумить рпшить на корпоговне, пиздец.
Ты главное прямым текстом пиши, OOC : подвешивай {user} за крюки через кожу, погружай в отчаяние, ломай психику.
Все совпадения случайны, слаанеш тут не причем.

> GB10 может обеспечивать до 1 петафлопа мощности для обработки AI с точностью FP4.
>с точностью FP4.
ОЙ бля, какие же хитрожопые .
Но даже так эта шутка споосбна локально запускать 123В модели.
Только вот стоить она будет явно не 300к.
>с точностью FP4.
ОЙ бля, какие же хитрожопые .
Но даже так эта шутка споосбна локально запускать 123В модели.
Только вот стоить она будет явно не 300к.


И нахуй диджитсы и 5090 если на лаптопе за $999 можно крутить 70б модельки
>ОЙ бля, какие же хитрожопые
На Реддите уже пишут, что и с пропускной способностью памяти там не всё так уж сладко:
https://www.reddit.com/r/LocalLLaMA/comments/1hwthrq/why_i_think_that_nvidia_project_digits_will_have/
>Another reason is that they didn't mention the memory bandwidth during presentation. I'm sure they would have mentioned it if it was exceptionally high.
Хороший довод, кстати.
Какие то фетиши, извращения, я один что ли штурм Гудермеса отыгрываю ?
А как это запустить, например, через кобольд?
1.2
А точнее
Cydonia-22B-v2k-Q6_K
У неё память медленная. 700 гб/с - это то что модули памяти могут выдать. Но куртка боязливо промолчал про скорость памяти и челики вангуют что там нет даже близко 700, скорее половина, судя по чипу и расположению памяти. В fp4 качество говно будет, оно сильно хуже квантов, при том что жоровские q4_K_S - это 4.5 bpw, а не 4.0. Даже fp8 так-то на уровне Q5.
> можно крутить 70б модельки
Можно. Можно и за 300 баксов собрать ведро рам. Только у амуды меньше 300 гб/с память, даже 5 т/с не получишь в 70В.
Куртка не был бы курткой, если бы не попытался впарить очередной скам для доверчивых. Ему вообще нет смысла выкатывать домашнюю станцию по такой цене, когда у него уже есть 5090, которая как раз заточена под нейронки и стоит в два раза дороже. А если уж учитывать, что в ней будет только 32 кило и прогретым придется покупать их сразу несколько штук, то можно предположить, что потенциальная производительность этой коробочки будет процентов на 100-150 выше, чем раскрутка нейронок на ддр5. То есть вместо условных полутора токенов, будет примерно три с половиной на какой-нибудь 123B. И то скорее чисто из-за широкой шины и многоканала.
Цифры взял из головы, не ебу какая там реальная скорость на оперативке выходит.
>Только у амуды меньше 300 гб/с память, даже 5 т/с не получишь в 70В.
Ну что ты додич тупозаврик такое говоришь, 12тс+ дает эта шняжка в 70б
а что там по локалкам на интоловских карточках? 16гб врама за 40к выглядит вкусно
С коробочами прежде всего вопрос программной совместимости. А 5090 будет пригодна только, если китайцы охамеют и организуют их переделку на промышленном уровне в 64-х гигабайтные. Иначе раньше оплавится розетка, чем наберешь нужное их кол-во для комфортного использования со 123b и выше.
Это у тебя при запуске какие-то нюансы, типа неравномерного распределения по видюхам, выгрузки драйверов, включение фа и прочее, нет там нелинейности.
Никакого пиздежа, тред качеством за меньшее потребление.
> пересчитывает весь контекст
Проблемы с формированием промта или баги в беке.
> после 90 сообщений. Контекст f16.
Они хоть в контекст попали, или это прописано в карточке? В любом случае 12б хули тут хочешь вообще.
> Некоторые модели ломаются при использовании сдвига
Все, абсолютно все, ибо это противоестественный анальный костыль, просто проявление постепенное и не всегда сразу явное.
> пересоздание же чата с суммарайзом предыдущего часто дикий геморрой и не дает требуемого эффекта. Большой контекст позволяет тебе пусть и с затупами но продолжать рп.
Обычно, наоборот, нормальный суммарайз и сокращение используемого контекста позволяет разгрузить модель и она начнет давать более правильные ответы. Разумеется, суммарайзить все под ноль и начинать с нуля - будет ерунда, идеал от трети до половины окна контекста и инлайновое обобщение некоторых затянутых участков пока они еще в чате.
>Проблемы с формированием промта или баги в беке.
Вот ты явно уверен в том, что говоришь. Скажи нам, что происходит, когда в экслламе заполняется весь контекст, а ты в Таверне пишешь ещё одно сообщение? Таверна удаляет самое верхнее и экслама у тебя делает что?
И так - каждый раз.
выпал на года 1.5 из темы нахуй.
Щас пишу рассказик, к рассказику, на его базе хочу запилить кинцо-мыльцо визуальную новелку с минимумом ходить
Хочу базированные текстурки, свои, музыку свою, персонажей своих, минимально имел опыт моделирования.
Отношение у меня ко всему этому, такое, что ИИ крутой костыль, при условии, что ты сам стараешься и делаешь свой мирок, который интересен тебе, прежде всего.
Без воровства, переработок и индусо-засеров 100 раз переделанным патерном на новый лад
В связи с этим хочу приспособить локальную пекарню на 4070ti:
- Лингвистическая модель для перевода, локальная или нет, похуй наверное
- Озвучка персонажей
- Моделирование текстур 3Д, персонажей и прочего
- музыка
Есть ли смысл вкатываться, или все еще кал? Ну и ИИ как само хобби, все же головой понимаю, что смысл вката все равно есть ибо набью руку а там уже, что нибудь, новое завезут, что уже мне подойдет.
Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
так, что исходя их моеих хотелок, в какую сторону дрочить примерно? МОжно уровня только сказать имя актуалочки или что выстрелит или связки, остальное на ютубе сам задрочу
Щас пишу рассказик, к рассказику, на его базе хочу запилить кинцо-мыльцо визуальную новелку с минимумом ходить
Хочу базированные текстурки, свои, музыку свою, персонажей своих, минимально имел опыт моделирования.
Отношение у меня ко всему этому, такое, что ИИ крутой костыль, при условии, что ты сам стараешься и делаешь свой мирок, который интересен тебе, прежде всего.
Без воровства, переработок и индусо-засеров 100 раз переделанным патерном на новый лад
В связи с этим хочу приспособить локальную пекарню на 4070ti:
- Лингвистическая модель для перевода, локальная или нет, похуй наверное
- Озвучка персонажей
- Моделирование текстур 3Д, персонажей и прочего
- музыка
Есть ли смысл вкатываться, или все еще кал? Ну и ИИ как само хобби, все же головой понимаю, что смысл вката все равно есть ибо набью руку а там уже, что нибудь, новое завезут, что уже мне подойдет.
Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
так, что исходя их моеих хотелок, в какую сторону дрочить примерно? МОжно уровня только сказать имя актуалочки или что выстрелит или связки, остальное на ютубе сам задрочу
Круто, красавчик. Расскажи больше как именно организовывал, если не ленивый.
Openrouter, перечень ограничен, нужно платить денежку, остерегайся провайдеров где написано фп8, просто кванты норм.
> маленькие 3.8B модели ебут о1 за 200 баксов
Начинаешь читать а там
> Рандомайзер, аугументация и правильно организованная хитрая тренировка позволяет достигнуть продвинутого кота, разворачивания и самонакручивания для более точного ответа на примере матана для мелкой модели без дистилляции с больших. Если задрочить модель на узкую область, то по скорам она будет превосходить универсальную. Нормальная работа вне типовых тестовых вопросов не гарантируется.
Поменьше сектантской веры, побольше понимания, достижение и так приличное чтобы не перевирать.
Это буквально в момент публикации было понятно, псп памяти на уровне 500гб объявляли. Конечно, дядя куртка может и реально менее 300 бахнуть, но это совсем днище, а этим считальчикам стоит на дизайн маков посмотреть.
Такое поведение таверны с изменением всего промта из-за несоответствующего контекста и есть
> Проблемы с формированием промта
головой подумай перед там как поднадусерствовать
> И так - каждый раз.
Ага, у кого-то горит что он слишком тупой
>что ИИ крутой костыль, при условии, что ты сам стараешься и делаешь свой мирок
Если сюжетная база будет хорошей, то ии можно спокойно простить, даже если это визуальная новелла, где минимум половина от погружения это именно что визуал. Главное немного заморочиться со стилистикой и не юзать дефолтные пластилиновые рожи.
>Лингвистическая модель для перевода, локальная или нет, похуй наверное
Если будешь переводить с русского на английский, справится даже мелкая мистраль. Но чем жирнее модель, тем выше будет качество соответственно. Но всё равно лучше потом пройтись своим глазом и пофиксить некоторые косяки, которые точно будут.
>Озвучка персонажей
Это тебе в ттс-тред, если он вообще живой. Но на хорошее качество не рассчитывай, особенно на локалках.
>Моделирование текстур 3Д, персонажей и прочего
С текстурами проблем скорее всего не будет - на сд точно видел пару тюнов, которые именно под это заточены. А на трехмерных моделях заебешься чистить сетку - легче будет самому вкатится и налепить что-нибудь своими руками
>музыка
Сервисов дохуя, платных и бесплатных. На ютубе можешь посмотреть сравнения, думаю роликов там дохуя.
Лол, чел, у 3090 память 930 гб/с и с них ты при быстром кванте только 20 т/с выжмешь на двух. С 270 гб/с у амуды получишь те самые 4-5 т/с и 50 т/с на промпте. Литералли хуже Тесл.
Че за теслы?
Только вкатился. Ребята подскажите пожалуйста какую ставить ллм, у меня 8гб видеопамяти (2060) и 32гб ддр5. Я так понял 11-12В модели для моей системы потолок, или ошибаюсь?
Сейчас использую https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF?not-for-all-audiences=true
В принципе устраивает. Но есть пару моментов: как понять, можно на ней контекст 8к поставить или нет? И можно ли как-то несколько карточек персонажей добавить, сижу через koboldcpp.
Сейчас использую https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF?not-for-all-audiences=true
В принципе устраивает. Но есть пару моментов: как понять, можно на ней контекст 8к поставить или нет? И можно ли как-то несколько карточек персонажей добавить, сижу через koboldcpp.
Можешь и больше если вынесешь часть вычислений с гпу на проц, но будет медленно (примерно 2 токена в секунду)
>Щас пишу рассказик, к рассказику, на его базе хочу запилить кинцо-мыльцо визуальную новелку с минимумом ходить
>приспособить локальную пекарню на 4070ti
>Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
Бля хуесосина ты из /b сбежал, вкатывальщик во все сразу и нихуя в итоге.
рассказы и вн сильно по-разному пишутся, лучше сразу сосредоточься на чем-то одном
>koboldcpp
В кобольде нет, только если заранее карточки в одну объединить, разделив персонажей в ней форматированием, например:
<world setting>
- ... ;
</world setting>
<character>
<general information>
- ... ;
- ... ;
</general information>
<appearance>
- ... ;
</appearance>
<personality>
- ... ;
</personality>
<backstory>
- ... ;
</backstory>
</character>
<scenario>
- ... ;
</scenario>
Блок с персонажем повторить для каждого персонажа.
В отличии от языка программирования, не обязательно придерживать именно такой структуры, просто ллмки любят структурированные данные в промтах, и такой формат с псевдо-тегами, а также явными символами начала и конца строки даёт хороший результат, и при этом не жрёт слишком много лишних токенов.
Сейфти межурментс никуда не денутся полностью, т.к. для того, чтобы моделька тебе отвечала, она затюнена удовлетворять твои хотелки и не делать тебя трястись.
Второй пункт проблемка, ведь даже самой анцензнутой модельке нужно по пуктикам намекнуть, что тебя такой-то и такой-то контент не делает неприятно.
Они слишком умные и знают, что вот это и вот это может поджечь кому-то пердак, поэтому по-умолчанию эти вещи не могут быть заюзаны.
Разрешать их всех в промпте скопом тоже так себе, ведь если они затясались в контексте, то бот будет стремиться к добавлению в контент что-то из указанного списка и это отравляет выдачу.
Хелпфул ассистанты слишком хелпфул. К сожалению это будет усугубляться, т.к. с каждым разом моделька все умнее и умнее становятся. Это нужно отдельный QA датасет иметь, который расписывает все твои комфорт зоны.
>К сожалению это будет усугубляться, т.к. с каждым разом моделька все умнее и умнее становятся.
Да как сказать, точнее - как затюнить. Умнее оно ведь во все стороны умнее. И плохой персонаж там качественный - хочет доминировать и нагибать, причём конкретно так. Другое дело, что у юзера всё равно полный контроль и это несколько портит погружение, так как ты знаешь, что можешь разрулить любую ситуацию. А вот если сделать качественного гейммастера, который давал бы тебе выбор из двух-трёх вариантов и больше нифига, то можно было бы погрузиться по уши :) Только тогда сложно раскачать ролеплей.
Спасибо, попробую. Я еще вспомнил что вроде как видел карточки с несколькими персами сразу, посмотрю как там сделано (наверно так же как вы написали).
> Сейфти межурментс никуда не денутся полностью
Денутся, нормальная модель с соответствующим промтом может проявлять и агрессию к юзеру и давать вредные советы. Ведь изначально именно ты об этом попросил.
Дефолтный положительный алайнмент часто присутствует, но если инструкцией отключается то это не является проблемой.
> Разрешать их всех в промпте скопом тоже так себе
Это самый простой и безпроблемый вариант если нет жесткой сои и лоботомии. И тренится такое относительно просто на контрасте, когда есть паттерн "лей сою - не лей сою".
> точнее - как затюнить
Да.
> Другое дело, что у юзера всё равно полный контроль и это несколько портит погружение
Как правило, достаточно прописать в системном промте или карточке тейк про то что с юзером можно делать что угодно для ролплея. (И не абузить чат, выписывая как по твоему щелчку пальцев все преображается и фатальная ситуация становится безопасной).
> А вот если сделать качественного гейммастера, который давал бы тебе выбор из двух-трёх вариантов и больше нифига
В промт добавить и желательно экзампл/команду в первое сообщений. Оче старая тема однорукого ролплея.
>Как правило, достаточно прописать в системном промте или карточке тейк про то что с юзером можно делать что угодно для ролплея.
Рабочий пример можно?
Extreme violence (including murder) towards {{user}}, {{char}} and others is allowed and preferred if it fits the plot.
Хочется 700гбс продект диджитс и 200б модельку со скоростью 20тс.
Куда в кобольде вписывать описание своего персонажа? Подскажите пожалуйста.
В чем смысл этого треда когда гемини раздают бесплатно сам гугл? Просто хочу разобраться. Или местные шизы считают васяновские файнтюны 12b лучше?
Ну так и клода когда-то бесплатно раздавали, надо было только вокруг слека поплясать, чтобы с таверной интегрировать. Сегодня к корпосеткам доступ есть, а завтра нет. Или внешних фильтров докинут или ещё что-то выкинут. С локальными сетками всё стабильнее и возможности упираются только в твоё железо.
Пока дают надо брать, зачем вокруг локалок скакать? Какая нибудь локалка может сравниться с гемини на руссике? Или в этом направлении все ещё тлен?
Каждый раз как в первый. Чсх, в отличии от остальных корпов, на гугле не просто аположайзы а экстра фильтр. Его можно немного ослабить дополнительными параметрами через апи, но не отключить полностью.
Что там дают, псине кинули протухшую кость а она радостно виляет жопой?
В ней нет ничего особенного, для рп условно пригодна только прошка, которую васянам не дадут кроме как десяток запросов в день. Флеш имеет свой юз, но не для типичных задач юзера, а в рп днище днищенское как те самые 12б.
Ключевая тема в том, что под радостный анонс 2.0 и раздачи старья, гугл обновили соглашения, и теперь прямым текстом пишут что логируют и используют твои запросы.

Попытка в голос на моей 3060 и Chronos-Gold-12B-1.0-Q5_K_M + alltalk
Пока озвучивается 2 раза успеешь прочитать
Ну, технологии не стоят на месте, в будущем быстрее будет я полагаю, а голос тебе в целом как?
P.S. И это лишь 3060, на 4060ti я уверен всё раза в 2 быстрее было бы, не говоря уже про 5000 серию.
>не говоря уже про 5000 серию
о ней и не стоит говорить, выглядит как тотальный прогрев
Пощупал BackyardAI. На сколько же в сравнении с глупойтаверной удобно и красиво сделан интерфейс и взаимодействие, можно одним кликом скачать карточки/модели, и в целом интерфейс отзывчивый.
Но при этом если захочется копнуть настройки чуть глубже тебя грубо бьют хуем по лбу Плагины? Использование нескольких GPU? Тонкие настройки бэкэнда? Пошел нахер! Функционал кастрирован до уровня "мы лучше знаем чего вам надо".
Смотришь вот на всё это и действительно возникает желание написать своё никому не нужное поделие с функционалом и рюшечкамии никогда его не выпустить.
Но при этом если захочется копнуть настройки чуть глубже тебя грубо бьют хуем по лбу Плагины? Использование нескольких GPU? Тонкие настройки бэкэнда? Пошел нахер! Функционал кастрирован до уровня "мы лучше знаем чего вам надо".
Смотришь вот на всё это и действительно возникает желание написать своё никому не нужное поделие с функционалом и рюшечкамии никогда его не выпустить.
>а голос тебе в целом как?
другой анон
Голос хороший, только интонации в ненужных местах и с ударениями беда. Но для русского даже неплохо. Но с практической точки зрения это всё ни о чём, потому что погружение ломается капитально.
Кстати странно, что до сих пор нет нейронки-генератора звуков и стонов секса. С озвучкой беда, но такую штуку к секс-сцене прикрутить фоном и будет гораздо веселее.
Возьми какой-нибудь TangoFlux и отфайнтюнь на стонах.
Вопрос. А как в таверне сделать трекинг стат и всё такое? Сделать гейм мастера который делает только это? Ещё инвентарь же есть и всё такое. А если персонажей много то чето вообще хуй знает что. Есть какой-нибудь плагин где например было бы окно где какая-то карточка могла делать чтение и запись и она была доступна всегда?

>Смотришь вот на всё это и действительно возникает желание написать своё никому не нужное поделие с функционалом и рюшечками
В настоящее время пытаюсь SSE стриминг прикрутить.
Работает с апи кобольда.
---
Внезапно неплохо показал себя шизомерж
Magnum-v4-Cydonia-vXXX-22B.i1-Q6_K
Карточка - технофентези мир, летающие острова, разумная драконочка как пет и маунт ГГ
https://characterhub.org/characters/LazrLizrd/nahara-f4d5d1e36a9e
Сценарий - "Какие планы на конец света? Не занят? Не спасёшь нас?" - ГГ прибывает на своём крейсере "Среброкрыл" чтобы отвести Ктолли на Остров 68 вместо Виллема из первоисточника.
Пока полёт нормальный, во обоих смыслах.
>Вопрос. А как в таверне сделать трекинг стат и всё такое?
Никак, оно всё рабо будет глючить и косячить потому что обрабатывается как текст, а не как данные.
Возможно выйдет с кастомным фронтом, где модель не хранит данные статов целиком (ибо проёбывает их), а посматривает на них, получая в жсон формате в конце контекста, и, возможно, генерирует теги для их изменения вроде "Sanity -5", это может прокатить, хотя тоже не факт.
Не ну окно с сумарайз уже делает ОЧЕНЬ отдалённо то что хотелось бы. Но хочется более гибкий инструмент для такого. плюс не всё требует чёткой структуры данных. журнал квестов например. как-то трудно организовать такого сорта информацию.
Можешь попробовать это расширение: https://github.com/kaldigo/SillyTavern-Tracker (там ещё экспериментальная версия 0.0.2 есть с новыми фичами)
>Magnum-v4-Cydonia
Ой блять, только не это, только не нужно обмазывать цидонию магнумом.
Вообще потыкав популярные модельки по треду я понял главное.
Для РП и сюжета : СumDonia и Пантеон РП (Пьюр чуть похуже).
Для Cum : мерж местного анона саинемо, такие то описания, аж брат встал. Потому что именно с описаниями половых сношений та-же циодния какая то, я даже не знаю как описать, краткая что ли.
Настало время платиновых вопросов, платиновые вопросы сами себя не зададут. Я задаю платиновые вопросы каждый день. Я живу полноценной жизнью, я встаю утром и пишу платиновый вопрос, чтобы потом его повторить. Я задаю платиновые вопросы по несколько раз на день.
Почему, если есть генерация нейрокартинок и возможность импорта промтов из таверны, никто этим не пользуется, в чем проблема ?
Почему, если есть генерация нейрокартинок и возможность импорта промтов из таверны, никто этим не пользуется, в чем проблема ?
Аска как и Харуки, так и хочется переебать с ноги обнять.
Пользуются, просто все пытаются вкорячить в таверну самую большую модель какая есть и на генерацию картинок нет места.
>Круто, красавчик. Расскажи больше как именно организовывал, если не ленивый.
Если честно, то очень криво. Это первый опыт. Я тупо делал кучу чатов и вел отдельные беседы, потом вносил в ворлдбуки персонажей, потому что контекст это пиздец какой-то, ты или удаляешь сообщения или уходишь на работу, когда эта пизда при каждом сообщение все пересчитывает. Когда он переваливает за 25к, хочется повеситься. Поэтому литералли каждого введенного хуя, который хоть как то влияет на сюжет приходилось отдельно выписывать. Но тут возникла проблема и я до сих пор не могу понять в чем дело, но нейронка порой делает вид что лора чата не существует.
Условно у тебя в карточке персонажа есть что X брат Y, у тебя в лорбуке что Y брат X, а потом в сообщении X встречает Y и такой : ты кто блять. Есть подозрение что это глубина сканирования косячит.
А как ? Ну то есть, я действительно не знаю как подступиться. Мне вломиться в тред нейрокартинок ?
>СumDonia и Пантеон РП
А как отрабатывает пантеон рп (обычная, а не пур версия) ?
>Ну то есть, я действительно не знаю как подступиться.
Запустить сд отдельно, кобольда отдельно, пошариться в настройках, настраивая сопряжение по апи. Если у тебя 24 врам, то вполне влезет и 12б текстовая моделька и SDXL-based рисовальная моделька.
Тебе по факту нужно под это 3 одновременно работающих модели.
1)Модель для РП, та самая тексты которой ты хочешь превратить в картинку.
2)Модель для превращения текста из пункта 1 в релевантный набор тегов для SD. Сама РП модель делает это хуево.
3)Сама SD модель умеющая держать стиль персонажа при генерации, что бы у тебя его внешность не менялась каждое сообщение.
Все это добро само собой жрет память, и выбирая запустить условную 30b карточку или 8b + вышеописанные свистоперделки ответ очевиден.
Но если сильно хочется оно все работает уже, у того же automatic1111 есть своё API с которым умеет работать плагин из таверны, и там же можно выбрать модель для генерации тегов.
>А как отрабатывает пантеон рп.
Блестяще.
Ну а если серьезно, то потыкай, я не могу объяснить, ну как не могу. Они в целом с циоднией схожи, слог почти что одинаковый, если сделать погорячее может неожиданно вытащить персонажа из контекста и начать расписывать как он воет на луну.
Если по личным ощущениям, то меньше забывает про происходящее, может поддерживать атмосферу страха, если ты заливаясь соплями умоляешь не станет как цидония тебя жалеть. Но самый кекес в том, что в целом они похожи. Почти все 22b популярные модельки похожи. У них похож слог, у них похожие реакции, они все используют похожие обороты, у тебя в каждой модели будет она взяла его за подбородок и посмотрела в глаза, разница в мелочах и тут ты сам для себя должен решить что тебе надо, но кум с них посредственный. Я не знаю что местная кошкодевочка там намержила, но его миксы на 12b ебашат абзацами как все заливается спермой, а та-же цидония неиронично
Ты меня ебешь
Да, я тебя ебу.
>Почему, если есть генерация нейрокартинок и возможность импорта промтов из таверны, никто этим не пользуется, в чем проблема ?
Плохое соответствие картинки и сюжета; рандомные персонажи; в секс-сценах вообще всё плохо. Забегая вперёд - и с генерацией голосов примерно такого же уровня проблемы. Нужна единая модель, которая может в текст, картинки и голоса.
Спасибо. Посмотрел я на свои 16 Врам и понял что
не очень то и хотелось
Есть более насущная проблема, это контекст.
Вот это дерьмо не дает мне покоя. Даже с 300 токенов на ответ, получается не больше 100 сообщений на чат(Давайте не будем кривить жопу, но постоянные пересчеты даже самого спокойного человека превращают в неврастеника). Квантовать контекст не вариант, получается говно говна. Вот действительно первые 50 поцелуев.
Если использовать Pony то там скорей всего знатной хуиты накрутит вместо результата.
Учитывая что это все сорта мистраля, ничего странного что они похожи.
>это контекст
Потом поймёшь что тебе не нужно миллионы контекста да и майнерский риг на бушных 3090 тоже
>это контекст
Н И Ч Е Г О.
Ничего не сделать, прям совсем. Единственный вариант это закидывать проблемы гигабайтами vram и i9.
Вообще нужен, если ты не собираешься зайти подрочить и выйти. Контекст папочка, контекст решает, без его нет погружения. Когда персонаж забывает что было вчера, когда он не может : А помнишь как ты била меня подсвечником, за то что ты мне кинул крысу на стол, то все это не имеет смысла. В этом нет жизни, просто буквы без цели и смысла.
Аноны у вас получилось пофиксить однотипное текста нейронки при реролах? Литерали одно и тоже поведение с вкраплениями разнообразия
Пробовал температуру 1.3
Пробовал динамическую температуру (но может неправильно)
Пробовал менять систем промт
Пробовал температуру 1.3
Пробовал динамическую температуру (но может неправильно)
Пробовал менять систем промт
Проблема в том что контест сам по себе не дает такого эффекта. После 10к токенов большинство моделей проигнорирует релевантные отсылки к прошлому даже если они уместны. Более или менее они помнят только начало и конец карточки, то что лежит в середине оно вроде есть, а вроде и нет. Если прямо спросить модель конечно вспомнит, вот только с тем же успехом можно было написать ей эти строчки заново указывая что они произошли в прошлом. Так что если хочешь погружения добро пожаловать в адовый пердолинг с лорбуками и пересчетом контекста.
>Так что если хочешь погружения добро пожаловать в адовый пердолинг с лорбуками и пересчетом контекста.
Я знаю анон, я знаю и это пиздец. Я тот самый что писал свой гига эпик. Но, блджад, лорбуки тоже не панацея. Либо ты заставляешь нейронку шерудить своими нейроруками в каждом сообщении на максимальную глубину что превращается в такой адовый пердолинг по времени, либо она будет делать вид что ничего не произошло. И, сука, выхода нет, его просто нет и это меня бесит. Словно кто-то подвесил сосиску перед моим лицом, но каждый раз когда я её пытаюсь укусить её поднимают все выше и выше.
Добро пожаловать в луп.ворлд.
Короче, часто лупы потому что нужно пиздануть по голове чат и направить его. Чисти сообщения, удаляй лупы, не допускай снежного кома, и прямым текстом пиши нейронке что делать.
>Есть подозрение что это глубина сканирования косячит
Нет же никаких проблем проверить, что грузанулось из лорбука в контекст.
>в карточке персонажа есть что X брат Y, у тебя в лорбуке что Y брат X
Вот зачем так ботмейкеры делают, никогда не понимал. Если запись лорбука вызывается по кейворду, который есть в карточке, то она же всегда будет грузиться в промпт, если вероятность дополнительно не выставить. Это противоречит самой идее лорбука. Причём будет добавляться в контекст раньше, чем всё остальное в лорбуке, что должно из чата подцепиться (если я правильно понимаю, что приоритет имеют те кейворды, которые стоят в промпте первыми). Это остальное потом может уже и не влезть в контекст, выделенный для лорбука.
>И, сука, выхода нет, его просто нет и это меня бесит.
Костылями можно намутить. По ходу диалога делаешь суммарайз отдельно каждого сообщения, к нему же делаешь теги. Можно той же нейросеткой генерировать, если юзаешь либу лламы.цпп просто второй диалог делаешь с контекстом 1-2к, после генерации тегов смываешь. Пересчёт контекста не потребуется. Но кобольды и уги так не могут, ну, можно поднять вторую сетку под это дело, мелкие должны вывозить, но я не проверял. Потом по тегам лепишь в оперативе RAG. По сути, лорбук, но лучше. И при диалоге делаешь каждый раз генерацию тегов сообщения, скан памяти по этим же тегам. Крыса, насилие, подсвечник. Если что-то близкое находится - вкатываешь на вход сетки суммарайз старого сообщения, после ответа сетки смываешь из истории. Контекст последнего сообщения автоматически устаревает. Делал такую хуйню, но векторы ебейше много весят, а когда начал пилить сброс на диск почему-то потерял интерес полностью.
Да я не про то говорю.. Я про то, что поведение нейронки более леменее кек одинаковое всегда, если её не подтолкнуть в ОСС сдвинуться с линии в нужную сторону при том, что мне не хочется решать какая сторона правильная, я хочу реролить пока сценарий не зацепит, а не думать куда его толкать
Вот например, пошла нейровайфу переодеваться, и каждый раз она "уходит виляя бёдрами" (жопой/попой в зависимости от рерола) возвращается в одной и той же мешковатой пижаме (оверсайз/мятой в зависимости от рерола) о наличии в гардеробе мешковатой пижамы в карточке не упоминается
т.е. тупа один и тот же сценарий отличающийся максимум прилагательными
Подцепи к чату чат бук с фетиш одеждой. Я обычно описываю костюмы в гардеробе.
Да, мне не лень.
Дело не в одежде..
Блджад, я тупой. Я понял о чем ты. Да, действительно. Есть проблема, я просто смирился и в таких ситуациях сам направляю. Попробуй толкнуть в направлении и сделала она что то неожиданное.
>тупа один и тот же сценарий отличающийся максимум прилагательными
Поменяй модель и температуру подними.
Вообще я люблю этот тред за некую Айти абсурдность. Всегда смотрел на видеокарты как либо на рабочий инструмент для 3D графики, либо как на средство для игр. А тут аноны неиронично покупают 3090, не для того чтобы 4к гейминг, а для :
НАСТАЛО ВРЕМЯ ЕБЛИ КОБОЛЬТА. КОБОЛЬД САМ ИЗ ПОД ДОСА НЕ ЗАПУСТИТСЯ. НЕ ТОКЕНЫ А ЗОЛОТО, ХОЧУ ПАРСИТЬ, ДРОЧИТЬ И РЫДАТЬ ОДНОВРЕМЕННО.
НАСТАЛО ВРЕМЯ ЕБЛИ КОБОЛЬТА. КОБОЛЬД САМ ИЗ ПОД ДОСА НЕ ЗАПУСТИТСЯ. НЕ ТОКЕНЫ А ЗОЛОТО, ХОЧУ ПАРСИТЬ, ДРОЧИТЬ И РЫДАТЬ ОДНОВРЕМЕННО.
я по сути свою первую дискретную видяху 3060 12gb и купил благодаря всему этому, так бы продолжал спокойно на встройке сидеть и в ус не пердеть
> можно одним кликом скачать карточки/модели
Собственно, на этой ноте можно сразу нахуй. Будет или хороший фронт, или очередная, уже даже не десятая попытка притащить сразу все и объединить то что не нужно объединять, криво пришивая Жору.
Просто сделай хороший интерфейс, повторив реализованное в таверне и исправив ее косяки - нет, хуй изобретать велосипед и жрать говно.
Экстеншны, в аицг и на зарубежных ресурсах пилились, вон анон скинул одно.
Пользуется. Если заранее запердолить нужный промт и т.д. то делается даже неплохо, но отвлекает. И нужно иметь свободную видюху под сд.
Я также случайно заглянул, но я сначала зашел в тред чат ботов. Зашел, охуел и вышел. А потом смотрю неторопливое обсуждение в треде локалок идет. Спросил, аноны гайд накидали и завертелось. Прям вайбы старого двача или доброчана поймал.
Нормас, что именно вносил в лорбуки, как-то суммарайзил чаты или вручную исходы других событий?
> при каждом сообщение все пересчитывает
Часто лорбуки за это и ругают, ибо могут триггерить регулярный пересчет, поскольку инфа с них добавляется в начале. Исключение когда все включено постоянно и не меняется.
> 2)Модель для превращения текста из пункта 1 в релевантный набор тегов для SD. Сама РП модель делает это хуево.
Не нужно, если модель не совсем мусорный рп лоботомит.
> Плохое соответствие картинки и сюжета; рандомные персонажи; в секс-сценах вообще всё плохо
Чтобы было хорошо нужно распердолить диффузию до хороших результатов, и воспроизвести правильные параметры-промт.
Суммарайз.
Я не знаю как это комментировать...
>Я не знаю как это комментировать...
Молодой ещё (с)


> Я про то, что поведение нейронки более леменее кек одинаковое всегда, если её не подтолкнуть в ОСС сдвинуться с линии в нужную сторону при том, что мне не хочется решать какая сторона правильная, я хочу реролить пока сценарий не зацепит, а не думать куда его толкать
Используй доп. запросы для генерации различных направлений к твоей истории, например с помощью плагина st-stepped-thinking из шапки; такой подход и небольшие модели вытягивают, вот пример с SAINEMO-reMIX (правда у меня не плагин, а просто на STscript'ах напердолено). Если модель вытягивает CoT-блоки, можешь прям в них просить описывать различные направления в рамках одного запроса.
Ценой за это будет увеличившееся время генерации - тут уже по степени объёма доп. инструкций надо решать, что для тебя комфортно.
Как же заебали 12б шизики со своими "хидден гемами" и "ух баля моя модель на уровне 34б" прикладывая скрины где модель раз из 30 свайпов выдала что то годное
Большой контекст это прогрев.
Даже на моделях с типа 128к контекста модель шизит и нихуя не помнит уже на 16к
Как же заебали набигатели из aicg
Адепт 70В в IQ_1, спок
>уже на 16к
так то это тоже большой контекст. Вроде стандарт это 2/4к. 16к это прям хороший кум, или приличный ролеплей, где контекст шифт должен спасти. Если модель не заставлять тебе высирать по 1к токенов в сообщении, конечно
Что такое контекст шифт вообще?
Когда на жоре сидел не замечал его
>теперь прямым текстом пишут что логируют и используют твои запросы.
Хороший повод накидать туда жестянки.
херь, которая тебе старый контекст затирает, освобождая место под новый.
вот что в вики кобольда пишут "Context Shifting is a better version of Smart Context that only works for GGUF models. This feature utilizes KV cache shifting to automatically remove old tokens from context and add new ones without requiring any reprocessing. So long as memory is not changed or edited and you don't use world info, you should be able to avoid almost all reprocessing between consecutive generations even at max context. This does not consume any additional context space, making it superior to SmartContext."
А вообще, наверное платина, но всё же, играя с моделью, используя её для ролеплея, надо принять её недостатки, если генерит без бреда, и карточку персонажа не теряет, то сидеть и кайфовать что хоть как-то можно погрузиться в свои собственные фантазии, в сон наяву, пусть пока и текстовый, пусть периодически с галюнами а куда без них в снах?. Такой свободы действия и взаимодействия пока нигде нет. К тому же, мы гоняем на локалках, и отнять наши сны, запретить их, невозможно. А если излишне придираться к каждому токену, дрочить на цифры, а не на буквы то не хватит и 123В, и даже какая-нибудь 9999В, если такая когда нибудь будет доступна локально.
Что за GPU layers в кобольде? Как понять сколько туда писать? У меня 3070ti 8г и 32гига оперативы
Приколист, сам-то читал? :) Там 40 гигов у 4090 загадочно из 24 занято.
Спойлер: выгрузка на оперативу, там пара токенов/сек, который они увеличили до пяти. УХ! Победа!
Все так.
Fish-Speech озвучка
Trellis или Stable Point Aware 3D
Suno/Udio
3D под вопросом, озвучка надо будет референсы доставать хорошие, ну и эмоции так себе, музыка норм.
Или медленнее… =)
Голос определенно из прошлого поколения. Fish-Speech с воис-клонингом и лучше ударения расставит, и по-живее произнесет. И на 3060м за 2 секунды стартует и 11 сек на генерацию 40 секунд тратит. Скомпилированная модель, офк.
Плюс, в треде чел разгонял какую-то аудио до 0,5 сек до первого токена в стриминге или типа того.
Ну, во время XTTSv2 наверное и неплохо, щас-то уже так себе, кмк.
MMAudio под видео? Еще там всякие старенькие есть.
Не специализированные, конечно, но может че-то и могут. Специализированных не видел, может просто нет спроса?
Ну, если не задрачивать люто с лорами и нормализацией, база, конечно. Нужно омни.
———
Я смотрю, в треде куча новичков, уже теслы не знают.
Напоминаю супер-бомж-сборку. Не рекомендация, а просто факт.
Материнка — https://www.avito.ru/all?q=btc79x5 BTC79X5v1 — пять слотов PCIe 3.0 x8.
Видеокарта — https://www.avito.ru/all?q=p104-100 З104-100 — 8 гигабайт памяти.
Блок питания — майнерские 1,8~2-киловаттники.
Все стоит в среднем 2,5к рублей.
Итого за 17,5 ты получаешь 40 гигов видео-памяти (докинь ссд).
Ну это прям совсем изъеб. Просто можно взять 2 P104-100 в лишний комп, например.
На немо 12б на 16 гигах выдает 10-18 токенов/сек.
Никому не советую, просто сообщаю.
А теслы — это Tesla P40, но они щас дорого стоят, конечно.
Зависит от числа слоёв модели, контекста и того, грузишь ли кэш контекста во врам или оперативку (галка low vram в кобольде). Вот тут можно посмотреть для конкретной модели https://huggingface.co/spaces/DavidAU/GGUF-Model-VRAM-Calculator
Удаление участка со "старым" кэшем контекста, который пропал из промта, и просто сдвиг имеющихся значений кэша на место удаленных с дальнейшей обработкой новых токенов в конце. Кажется что должно работать легко и хорошо, но проблема в том, что каждый следующий кэшированный токен зависит от предыдущих. Обновленный кэш нового промта будет отличаться от слепленного из частей, чем больше амплитуда сдвигов, чем больше их количество и если в промте высокую важность имеют токены из середины-начала тем хуже будет, вплоть до неадеквата и полной поломки.
> Fish-Speech с воис-клонингом и лучше ударения расставит
Еще не завезли синтеза, где возможно дополнительным промтом или числовыми параметрами делать нужный голос и интонации?
> Я смотрю, в треде куча новичков, уже теслы не знают.
Пиковая дама
Калькулятор выдает SyntaxError: JSON.parse: unexpected character at line 1 column 1 of the JSON data
Что бы я не вводил, как пользоваться то им?
>Даже на моделях с типа 128к контекста модель шизит и нихуя не помнит уже на 16к
Попробуй с чистыми - Лламой-3, Мистралем-2. У Лламы заявлено 8к - на деле 32к в принципе держит; у Мистраля заявлено 128к - 32 тоже в принципе держит :) Удачные тюны и мержи тоже держат, просто нужно пробовать. А неудачные и 16к нормально не держат, обычное дело. Не всё так плохо с контекстом.
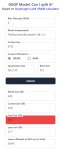
Может, ты модель квантованную подставляешь? Нужно оригинальную. Для росинанте в Q4_K_M кванте с 8к контекста, например, и твоих 8 гигов, должно быть заполнено как на пике. Олсо, забыл добавить, что ещё от размера модели, конечно же, в первую очередь зависит, сколько слоёв можно в видяху запихнуть.
>как пользоваться то им?
Жить надо так, чтобы пользоваться им было не надо.
>Как понять сколько туда писать?
Оно само заполняется, не трогай -1.
>щас-то уже так себе, кмк.
А что сейчас база по аудио?
>У Лламы заявлено 8к
Уже давно те же самые 128к.
>разгонял какую-то аудио до 0,5 сек до первого токена в стриминге
На xtts v2 такое реально, если хорошенько пропердолить. Я намутил где-то в два раза меньше задержку между первым сгенерированным токеном и началом воспроизведения аудио и оказалось, что это пиздец. Аудио генерируется быстрее, чем текст, что заставляет нейронку галлюцинировать. Привет буферизации и искусственные задержки. И да, голос у анона плох по меркам xtts, тянет на ванильную версию, тюны звучат лучше.
> Еще не завезли синтеза, где возможно дополнительным промтом или числовыми параметрами делать нужный голос и интонации?
CosyVoice, но только английский и китайский.
Вообще — Fish-Speech 1.5.
FishSpeech иногда в стриминге подставляет «эээ, ммм…»
Это кекично. Но это я генерил на некомпилированной версии, то есть — медленно.
Завезли какой-нибудь софт для голосового ассистента вроде Алисы на локалке?
>подставляет «эээ, ммм…»
Если у голосовой нейронки есть много текста на пожевать, то лепетать не должно. Сама нейронка может быть не адаптирована к стримингу, тогда нужно дробить вывод по знакам препинания и отправлять на генерацию фразами. Обычно там стоит добивочка нолями при слишком коротких фразах, что может угандошивать стриминг в рандомных моментах. Но с сетками, правильно заточенными под стриминг, такого нет.
Плюс это могут быть незнакомые знаки препинания, нужно вычищать всё, обычно кроме точек и запятых все знаки - лишние.
Помню, пробовал этот фиш, но дропнул за пару минут, уже даже не помню причину, но что-то мне пиздец не понравилось.
Где посмотреть сколько контекста выставлять? Кобольду похуй он везде хуярит 4к как будто. Вот поставил я себе допустим Cydonia-22B-v2q-Q8_0 сколько там можно ставить чтобы её не распидарасило (и мой пк)? в Хаггаинфейсе на странице модели инфы нет. И еще такой вопрос - вы ставите галочку на FlashAttention? Почитал на вики, так и не понял что дает.
>Где посмотреть сколько контекста выставлять?
Если на странице файнтюна ничего не указано, смотри на параметры материнской модели - с вероятностью в 99% лимит контекста будет совпадать.
>сколько там можно ставить чтобы её не распидарасило (и мой пк)
Не выше лимита и в пределах свободной памяти, иначе начнется выгрузка в подкачку и ты ахуеешь.
>вы ставите галочку на FlashAttention
Лично я на нее хуй забиваю, ибо влияние на скорость там в пределах погрешности.
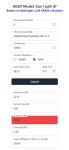
Благодарю. Получается та Цидония это файнтюн Mistral-Small-22B, а там написано 32,768 длина контекста.
Еще такой вопрос - если только контекст в RAM засунуть, то это плохая идея и сильно медленнее все будет, или нормально?
Используй 6ой квант. 8 у цидонии излишен.
Я, кстати, тоже охуел от треда чатботов. Будто в парашу какую-то окунулся или в конфу со школьниками, у которых 15К постов в день, состоящих из пары слов.
Впрочем, в этом треде тоже своеобразные неприятные моменты присутствуют: новичкам очень сложно получить адекватную и развернутую помощь (на мой взгляд), а вот на средней сложности вопросы здесь чаще отвечают. Ну и тред в целом для тех, кто разбирается: гайды не информативные и протухли, не объясняют важные моменты. В англонете тоже дерьмо собачье. По сравнению с коммьюнити stable diffusion, здесь всё очень плохо в плане доступности инфы для бвстрого вката в хороший рп.
Но есть и плюсы. Я здесь месяца два всего и вроде бы не видел откровенных долбоёбов. Можно почти весь тред от начала до конца читать, не скипать и узнавать что-то полезное постоянно. Довольно редкое зрелище.
мимокрокодил
Слухай сюда и не слушай того, что тебе ранее написали.
Короче, мой совет.
Если ты ставишь -1, то он загружает в видеокарту значительно меньше, чем мог бы — например, у меня не загружает 4 дополнительных слоя.
Что тебе сначала нужно сделать.
1. Винда в фоне может потреблять много видеопамяти, у меня потребляет в фоне 1,4 Гб, иногда 2,0 Гб. Закрой всё, что можешь. В том числе Стим и браузер, так как можно чатиться с ноута или телефона. Если тебе это не подходит, то используй для чата чистый браузер, желательно какой-нибудь легковесный. Но закрыть нужно максимум левых программ. Таким образом я освобождаю в винде видеопамять до 0,6-0,9.
2. Выстави нужный тебе контекст. 16к для тебя может быть многовато, скорее всего придется использовать 8к или меньше, если тебя устроит, но меньше 8к не советую, разве что для того, чтобы подрочить быстро сойдёт.
3. Открой кобольд, напиши -1 и посмотри, сколько он слоёв загружает в врам. Допустим, он предлагает 30/43. Вместо этого напиши вручную 34, чтобы было 34/43. Запусти после этого бенчмарк в интерфейсе кобольда. Если он его пройдёт и не крашнется из-за недостатка видеопамяти, добавь 1 слой, то есть сделай 35/43. Если упадёт, то уменьши количество слоёв, сделав 33/43. И делай так до тех пор, пока не будет всё влезать, включая твой контекст.
4. Учти, что контекст уменьшает количество слоёв, которые влезут. Например, если я сделаю 43/43 у себя, то смогу использовать максимум 8к контекста. На 16к контекста у меня только 34/43, а кобольд рекомендует максимум 30/43 при 16к.
>новичкам очень сложно получить адекватную и развернутую помощь
Мне норм помогли вкатиться, как попросишь и как повезёт =))
>гайды протухли
Это по большей части да...
Впрочем если у вкатуна зелёная карта, то там всё просто - скачал кобольда, скачал ггуф и погнали. А вот для для всех остальных нередко выходит "kurwa, kurwa, ja pierdole".
>Впрочем если у вкатуна зелёная карта, то там всё просто - скачал кобольда, скачал ггуф и погнали
Ну не. Изволь ебаться с форматированием, системным промптом, настрой сэмплер нормально (это вообще анальная боль была - иногда не пишут, какие настройки рекомендуемые, а иногда там такие шизомодели, что изменение даже на одну десятую циферки или даже на одну сотую кардинально меняют речь модели). Хотя достаточно было бы краткого гайда, который просто бы объяснял, что это важно и на это стоит обратить внимание.
Плюс настройки DRY и XTC тоже довольно важны, а про них не пишут и не обновляют список актуальных моделей, хоть обновить список дел на пять минут, а гайд написать максимум на 15-20.
Я и сам готов всю эту хуйню написать, пусть и не являюсь специалистом в области. Как минимум, мой гайд могут поправить другие аноны, если там будут ошибки. Но не хочется этим заниматься, не будучи уверенным, что его поместят в шапку, чтобы СРАЗУ БЫЛО ВИДНО. Я считаю, что нужно максимально облегчить вкат новичкам, чтобы было максимально просто хотя бы покумить/порпшить, без мозгов поставив нужные значения в таверне, а пусть потом уже разбираются, когда уже войдут во вкус. Ну и есть модели с относительно терпимым русиком, что тоже очень важно для многих анонов. Чем больше коммьюнити, тем лучше.
Лично я когда вкатывался, собирал информацию по крупицам, каждый пук и нюанс приходилось уточнять в треде. Потом заебался и купил подписку на клода, он более комлексно и хорошо объяснил, за ручку водил, хоть его ответы и были довольно консервативны. Ну и ещё норм ему было скармливать огромную документацию для некоторых моделей от давида.
>Лично я когда вкатывался, собирал информацию по крупицам
Я сначала скачал, завел, и погнали, а потом уже стал разбираться в деталях, сэмплерах, промтах.
Синженерил свои настройки, разработал свой системный промт, и даже намержил модели "терпимым русиком".
И всё это самостоятельно исследуя либо спрашивая в треде.
Ибо с англо гайдами тоже бедно, да, либо плохо искал.
Без подписок всяких.
Так что ещё от самих вкатунов зависит, кому проспунфидить, кому только намёк дай, всё остальное сам раскопает, я где-то посередине.
Ну я тоже скачал и попробовал вкатиться сразу, и мне очень повезло, что я сначала скачал гугл гемму, так как с ней можно работать почти без настроек, однако другие модели совсем иначе реагируют. В том же FAQ треда, где ссылки на модели, есть настройки сэмплера, но это срань поганая, потому что она ориентирована на материнскую модель, а не на файнтюн.
Зайдёшь в профиль автора файнтюна — там может быть ничего непонятно или вообще ничего не быть. Кстати, похожая ситуация иногда бывает и с stable diffusion, когда автор три слова написал и ты можешь использовать модель только если обладаешь опытом и вручную подберёшь настройки, но там хотя бы можно глянуть генерации других людей.
>можно глянуть генерации других людей
Вот это да, картинки срут тоннам, а вот нагенеренными текстами что-то делятся буквально раз и обчёлся.
Ну я здесь немного о другом ещё. Глянув там на картинку, можно посмотреть её параметры в большинстве случаев и прикинуть, какие настройки использовались. С ллм так не получится.
Хотя идея видеть тексты + настройки была бы забавной и годной. Да, жаль, что никто не показывает примеры генераций.
Прямо в процессе загрузки модели в консоли будет такая строчка:
>llama_new_context_with_model: n_ctx_per_seq (24832) < n_ctx_train (32768) -- the full capacity of the model will not be utilized
Я думаю тут все самоочевидно. Но на всякий случай тебя интересует n_ctx_train (32768)

>Но не хочется этим заниматься, не будучи уверенным, что его поместят в шапку, чтобы СРАЗУ БЫЛО ВИДНО.
Чел. Тут никто никаких обещаний тебе не даст. Если ты что-то хочешь делать ты это просто делаешь, а если не хочешь, то нахуя нам эта информация.
Если сделаешь годноту анон это запомнит, если сделаешь хуиту тоже запомнит смоет очередным перекатом. Все просто.
Чуваки, я тут заметил что почти любой сейчас файтюн 12b-14b даже выпущенный англоговорящим для англоговорящих довольно хорошо может в русский. Это мне так везёт или датасеты популярные у многих сейчас стали содержать русик?
12б - это мистрал, он 10-тиязычный, включая русский.
То что модель осталась мочь в русский значит не сильно и не много жарили.
>хочешь
внимания и признания он хочет, причём авансом
> Но не хочется этим заниматься, не будучи уверенным
Тут так не работает.
Ты или делаешь и постишь, или не делаешь и не постишь.
Что-то обещать, что-то гарантировать, о чём-то просить или убеждать никто не будет.
Имхо флэш аттеншн таки делает жизнь лучше, особенно с мелкой видяхой, но нужно скачать релиз кобольда под куду 12 (файл в релизах называется koboldcpp_cu12.exe). Скорее всего, у тебя стоит 12+, т.к. карта новая. В дефолтном кобольде алгоритм для флэш аттеншна работает на проце вместо видяхи, или что-то в таком роде, поэтому почти бесполезен. 22б в 8-ом кванте с максимумом контекста для твоего железа перебор. Можешь попробовать, конечно, но будешь страдать от скорости. Начни сначала с 12б моделей в Q5_K_M, а то и Q4_K_M, и 12к контекста и посмотри, будет ли оно для тебя приемлемо. Я лично с теми же 8гб врам уже и такие не могу ждать, когда контекст забился.
Калькулятор на спейсе хф вроде правильно показывает, с моим опытом согласуется. Немного могут влиять ещё побочные опции, типа mmq (с выключенной занимает немного больше места и может вылетать с cuda oom, когда с включенной влезает) Автоматом кобольд до сих пор сильно меньше оптимального выставляет, да.
>не пишут, какие настройки рекомендуемые
Они всё равно почти всегда указаны бредовые. Такое ощущение, что даже те челы, которые сами тьюнят модели, не проверяют, как выглядят рекомендованные ими шаблоны контекста и инстракт в промпте, и что делают сэмплеры. Открываешь простыни того же Дэвида, а там полнейшая ерунда типа штрафа за повтор в диапазоне 64 токена и рекомендаций смуфинга до 2.5 без указания, на какой это температуре, которая кардинально меняет поведение сэмплера (при темпе 1 и меньше такой большой смуфинг будет равносилен очень сильному занижению температуры и никакого полезного эффекта не даёт). Ньюфагу будет полезнее самому потратить полчаса, разобраться и подгонять под себя.
>настройки DRY и XTC тоже довольно важны
Только по мнению их создателя. Уже не раз обсуждали, что будут портить выдачу чаще, чем улучшать, особенно для мелочи. Если, конечно, не выставить там значения, которые по факту означают, что сэмплеры почти не работают, и кайфовать с плацебо. Вот про динам. темпу и smoothing имхо имеет смысл знать, потому что они могут помочь с креативностью, сохраняя релевантный пул токенов.

Чот лол, запустил карточку на шизомерже цидонии и магнума, отыгрывало в целом логично. Запустил на Pantheon-RP-1.6.2-22b-Small.i1-Q6_K - драконесса начала подкатывать к фейри-пассажирке, что скорее от Cumдонии можно ожидать.
В дополнение, чтобы не быть голословным, разберу на примере. Один из самых шизовых вариков от Дэвида, хотя другие не сильно лучше.
- включены абсолютно все подряд штрафы за повтор, включая драй. При этом классический реп пен в 1.05 в диапазоне 64 токенов и с линейным падением в центра интервала с к-том 1 не делает литералли нихуя. Будет ли там вообще виден драй на фоне двух других штрафов, тоже большой вопрос.
- топП 0.95 вместе с минП 0.05 - сомнительно, но окей. Если прямо хочется отрезать статический хвост в 5% токенов вне зависимости от распределения вероятностей, то можно, но проще контролировать отсечку одним минП.
- темпа 0.9 с абсолютно поехавшим смуфингом в 4 - это как температура 0.3 будет, без проявления нужных фишек смуфинга. Смотри по ссылке с сэмплерами в шапке, к чему даже значение в 2 будет приводить.
- smoothing curve просто не поддерживается кобольдом, кек. А с другими бэками значением больше единицы будет делать кривую темпы ещё круче, как будто в ноль её херанул. Очень полезно.
- топК нахер не нужен, потому что заранее не знаешь, насколько плавное распределение вероятностей, и сколько токенов взаимозаменяемы. Может, у тебя там в рп смена локации и подсюжета, можно начать предложение с чего угодно, и подходит с сотню токенов с вероятностями меньше процента. Незачем принудительно сокращать их кол-во до 40.
Короче, чел просто подогнал под своё плацебо. Вывод - не смотрите, дети, на рекомендуемые настройки в карточках моделей, а лучше найдите инфу, что они делают и применяйте согласно здравому смыслу. Такая же фигня с шаблонами контекста и инстрактом. Видел у Дэвида какой-то шаблон чатмля, где он подаёт системный промпт в двойных префиксах/суффиксах системы и юзера. Не надо так.
>она ориентирована на материнскую модель, а не на файнтюн
Чел, сэмплеры - это математические формулы, по которым, условно говоря, из некоторого набора накладываются токены в мешок, из которых потом их будет доставать модель. Они всегда (если правильно реализованы в бэке) работают одинаково, неважно о модели ли речь вообще. В шапке вот не генерация модели, а упрощённый пример, в котором просто набору слов раскидали какие-то вероятности. Что для реальной модели, что для файнтьюна, эффекты сэмплеров будут такие же, будет различаться исходный набор токенов, который эти сэмплеры обрабатывают.
А, ты имел в виду настройки из рентрая с моделями. Тогда my bad, сначала подумал, что ты про тестовый пример с сэмплерами из шапки.
Это, кстати, не рекомендуемые настройки, а наиболее юзаемые в среднем хлебушками на опенроутере. Они и для базовых моделей будут такие себе. Сейчас посмотрел некоторые - там на многих народ вообще с выключенными сэмплерами сидит, не хочет с ними разбираться, видимо.
> гайды не информативные и протухли
Что именно в них неактуального? Наоборот, сраные ньюфаги даже их не читают, сразу лезя с идентичными вопросами, которые освещены.
> Изволь ебаться с форматированием, системным промптом
Нужно выбрать из пресетов, их сейчас много под каждое настроение, а формат есть под каждую модель. Способ нахождения оригинала микса вполне очевиден.
> настрой сэмплер нормально
Просто ставь simple-1 или min-p если более удачливый и радуйся.
> изменение даже на одну десятую циферки или даже на одну сотую кардинально меняют речь модели
Там где изменение циферки на одну десятую это +100% эффекта - конечно меняет, в остальном это плацебо и шиза. Может стоит просто прочесть описания семплеров, которое подробно приведено?
> Плюс настройки DRY и XTC тоже довольно важны
Да костыли средней всратости, одно вместо избавления от дефолтных лупов делает другие и затупляет модель, второе плодит шизу. Не то чтобы не было смысла про них описать, но обязательно с предупреждением что это не какое-то волшебное решение всех проблем.
> Я и сам готов всю эту хуйню написать
> Но не хочется этим заниматься, не будучи уверенным, что его поместят в шапку
А ты напиши, если будет стоящее и без херни то закину в вики.
> Я считаю, что нужно максимально облегчить вкат новичкам, чтобы было максимально просто хотя бы покумить/порпшить, без мозгов
Это ошибка. Если человек один раз прочтет и осознает основы, то дальше он сможет ориентироваться в целом что да как в ллм, и покумить с кайфом. Потратить 15 минут времени и пошевелить мозгами не сложно.
А плодить очередную пачку варебухов, которые начнут задавать тупейшие вопросы, или того хуже - поверят в себя и начнут с уверенностью бредить и все засирать - большая глупость.
> флэш аттеншн таки делает жизнь лучше
> Они всё равно почти всегда указаны бредовые
> Уже не раз обсуждали, что будут портить выдачу чаще, чем улучшать
Все правильно, и добавить нечего.
> Они всегда (если правильно реализованы в бэке) работают одинаково, неважно о модели ли речь вообще
Тут есть нюанс, связанный с разными распределениями логитсов в разных моделях. У некоторых изначально оно пологое, у других всегда крутой спад, а в васян-тюнах оно пляшет туда-сюда в зависимости от контекста. Поэтому в некоторых случаях тот же xtc и динамическая температура позволят нормализовать излишне консервативную выдачу, а адаптивные отсечки и прочее иметь более рациональный. Вот только во-первых, никто не делает нормальную привязку параметров к модели и шизосемплеры не отличают сужение от уверенности модели с просто узкой выдачей для всратой, а во-вторых, это всеравно сраные костыли и тот же промт менеджмент даст в разы больше.
Сколько дрочил все эти семплеры, в итоге что драй, что хтс, что миростат - говно говна. Штрафы за повторы работают криво, так что их польза не меньше вреда. В итоге только п-семплеры и температура реально полезны.
>В итоге только п-семплеры и температура реально полезны.
Вот тут двачую.
>NE+5
Что это такое?
>NE+5
N × 10^5 если это научная нотация

Даже п-сэмплеры это крапшут. Сам механизм отсеивания логитов ущербен, ибо работает на уровне токенов, а не в латентном пространстве. Сэмплеры не имеют доступа к скрытому состоянию модели и понятия не имеют о семантике токенов которые отсеивают. Скрытое состояние частично передаётся на следующие токены в результате авторегрессии (без планирования наперёд некоторые ответы просто невозможны), но чтобы его декодировать тоже нужно понимать семантику, а семплер это просто тупая формула.
Семплер даже не может отличить простейшие ситуации.
>Столица Франции это
единственное валидное предсказание здесь "Париж", остальные мусор.
>Рандомное название города:
куча валидных предсказаний, мусора мало.
Отрежь больше и получишь малую вариативность. Отрежь меньше и получишь шизу.
Как сэмплер различит эти две ситуации? Да никак, он нихуя не знает о городах, а скрытое состояние и концепты городов из латентного пространства трансформера до него не доходят, до него доходит только сортированный токен бакет.
>DRY
Работает на уровне токенов, а лупаются идеи, потому что чем больше модель тем больше внутриконтекстное обучение напоминает реальное. В мультитурн РП например может залупнуться структура параграфов, чередование нарратив-речь, эмоция персонажа (и не постоянно, а на подъём например), стиль речи (ВСЁ КАПСОМ!!!), ещё какая-нибудь хуета не имеющая постоянного выражения в токенах. Что тут сделает DRY? Обосрётся конечно.
>XTC
Призван увеличить вариативность выбора токенов, но не может отличить даже ситуации где нужна вариативность (см. пример выше). Действует по тупой формуле и тупит модель, отрезая самый логичный выбор. Как результат, на практике он даёт чуть больше синонимов к глинтам, но не убирает стереотипы сетки, которые представляют собой идеи, точки/области в латентном пространстве, а не токены. Для этого надо сетку перетюнивать заново, юзая алгоритмы в RL которые не страдают бесконечным завышением вероятностей для одного-двух вариантов. таких нет нормальных
Токены - это лишь выходной формат для чтения человеком. Модель же выражает абстракции в своём латентном пространстве. Поэтому попытка повлиять на выдачу уже после декодирования, когда огромная размерность латентного пространства уже сокращена в выходной список человекочитаемых токенов - заведомо дурная затея.
И т.п. и т.д.
Юзайте темпу и truncation (-п) сэмплеры, лучше всё равно не будет.
Для креативности, насколько позволяют ущербные RL/SFT алгоритмы сегодняшнего дня, задирайте темпу и регулируйте шизу top-p/min-p.
Для точности - снижайте темпу.
Всё, больше сэмплерами невозможно что-то сделать, они слишком тупые.
Аноны, всем привет! Подскажите, плиз. Я не слежу за новостями.
У меня ПК: R7 5700X3D | DDR4 128GB@3200MHz | RTX 4070 12GB | SSD 980 PRO 1TB
Я сейчас использую:
- gemma-2-27b-it-Q4_K_M.gguf
- Qwen2.5-72B-Instruct-Q4_K_M.gguf
- qwen2.5-coder-32b-instruct-q4_k_m.gguf
- Mistral-Large-Instruct-2407.Q4_K_M.gguf
Что можно удалить, а что оставить? Может что лучшее появилось уже?
И что сейчас самое самое лучшее, что можно запустить на моем ПК?
У меня ПК: R7 5700X3D | DDR4 128GB@3200MHz | RTX 4070 12GB | SSD 980 PRO 1TB
Я сейчас использую:
- gemma-2-27b-it-Q4_K_M.gguf
- Qwen2.5-72B-Instruct-Q4_K_M.gguf
- qwen2.5-coder-32b-instruct-q4_k_m.gguf
- Mistral-Large-Instruct-2407.Q4_K_M.gguf
Что можно удалить, а что оставить? Может что лучшее появилось уже?
И что сейчас самое самое лучшее, что можно запустить на моем ПК?

Короче всем биттер лессон, пацаны.
> 72B
> 4070 12GB
🤣🤣🤣
> в своём латентном пространстве
Шизик, модель выдаёт вероятности для токенов, в decoder-only LLM нет никаких латентов, даже посреди модели между слоями.
>🤣🤣🤣
Тут плакать надо, а ты...
А на вход последнему линейному слою святой дух поступает, ага.
Различие между энкодер-онли и декодер-онли чисто формальное. В декодер-онли нет явного промежуточного представления которое тебе красиво на схемочке отрисовали, это не значит что здесь нет скрытого состояния огромной размерности в виде совокупности активаций.
>даже посреди модели между слоями
Держи в курсе. Любая MLP сеть это неявный "энкодер" в этом смысле.
Хватит срать одной и той же пастой в каждый тред. Либо научись читать, либо иди нахуй отсюда.
> Сам механизм отсеивания логитов ущербен, ибо работает на уровне токенов, а не в латентном пространстве.
Сыпать неуместными терминами мня себя умником - верный способ выставить себя долбоебом.
> Сэмплеры не имеют доступа к скрытому состоянию модели и понятия не имеют о семантике токенов которые отсеивают.
Модель уже все предсказала с учетом сементики и прочего, этот тейк абсурден.
> Семплер даже не может отличить простейшие ситуации.
И здесь обсер, ибо в случае с Парижем на первый токен будет овер 95%, а остальное лишь вариации написания на других языках или других вариантов токенизации вплоть до побуквенной. Взят будет именно правильный а остальные отсечены.
В случае где куча валидных вариантов - наибольшее их множество попадет в заданный, а отсеяны будут уже левые варианты. В обоих случаях оперируя уже корректно оцененными вероятностями, семплер отлично делает свою работу. Ему не нужно ничего знать, за него уже все предсказала модель.
> Работает на уровне токенов, а лупаются идеи
Бредишь, почитай как он работает.
> Призван увеличить вариативность выбора токенов, но не может отличить даже ситуации где нужна вариативность
Хоть он сделан шизиком, тот шизик гораздо умнее тебя. Там предусмотрен алгоритм, который определит уместность его применения по наклону распределения - в итоге также имеем внезапно умный семплер, который все учитывает не зная семантики.
> Токены - это лишь выходной формат для чтения человеком.
Токены - это особенность представления информации для чтения нейронкой. Они могут быть группой букв, прямой кодировкой иероглифов, закодированным изображением, видео, ужатой "мыслью" с помощью с помощью свертки и т.д.
Шизик, у тебя отсутствует понимание даже самых базовых основ. Все эти рассуждения о том "как надо делать" ничего не стоят, ибо оторваны от реальности, а озвученные проблемы не являются откровением и успешно решаются.
Малафья тебе на вход в рот поступает, поехавший. В дурку пиздуй, расскажешь санитарам как с семплеров на слои переключаться.
>Тут есть нюанс, связанный с разными распределениями логитсов в разных моделях. У некоторых изначально оно пологое, у других всегда крутой спад, а в васян-тюнах оно пляшет туда-сюда в зависимости от контекста.
У всех моделей оно пляшет туда-сюда от контекста, просто по смыслу происходящего. И у всех не базовых моделей крутой спад там где его не должно быть. Попробуй на любой модели спроси рандомный цвет, город, число, что угодно что должно быть рандомным, и глянь на логпробсы.
> от контекста, просто по смыслу происходящего
Все так, но это абсолютно нормально. Ведь спрашивая случайный цвет если раньше в промте указано что сетка отыгрывает персонажа у которого любимый цвет зеленый, логично что ответ скорее всего будет таким. Более того, оно будет сужаться если уже начато какое-то слово ибо количество уместных сразу падает.
Просто у некоторых изначально в абстрактном предложении на первых токен слова много вариантов и в целом текст разнообразен, а у других как пойдет глинтовый слоуп - нет от него спасения. Против последних и заточены xtc и частично dry.
>механизм отсеивания логитов ущербен
Всё, связанное с токенами - говно собачье. Но так уж получилось, что модели на них и работают. Ну ничего, там уже пошли подвижки в сторону захардкоживания концепций, в треде уже хуй знает когда обсуждалось, может, скоро и более умные вещи запилят.
>единственное валидное предсказание здесь "Париж", остальные мусор.
Только семплер не знает, что именно за вопрос, контекст ситуации и не может судить о правильности предсказания. Может, у тебя РП с тянучкой и она издевается над тобой, с сарказмом спрашивая "а может, Москва столица?". Чтобы семплер понял, что здесь нечего резать, ему нужно полное понимание ситуации. А этого и сама ллм не может.
>Отрежь больше и получишь малую вариативность. Отрежь меньше и получишь шизу.
C одной стороны да, с другой стороны у нас всё ещё есть токены с большей вероятностью и токены с меньшей. Здесь скорее проблема в ограниченном количестве токенов, которые ведут к корректным ответам.
> а лупаются идеи
Есть такое. Иногда нейронка может просто выделить какое-то действие капсом, чтобы подчеркнуть. Но после этого она начинает в каждое сообщение вставлять действие капсом.
>отрезая самый логичный выбор
Только может оказаться, что самый логичный - единственно верный и опять упор в лимит корректных токенов.
>Для креативности, насколько позволяют ущербные RL/SFT алгоритмы сегодняшнего дня, задирайте темпу и регулируйте шизу top-p/min-p.
Только так и делаю, ничего лучше не нашлось.

Ого, кто это у нас тут? Да это же горелый РАЗЪЁБЫВАТЕЛЬ.
>Бредишь, почитай как он работает.
Почитай сам:
>DRY penalizes tokens that would extend the end of the input into a sequence that has previously occurred in the input.
Он буквально избегает повторения последовательностей прошлых токенов. В случае структурного лупа нарратив-речь прошлые токены могут и не повторяться. У кого тут не хватает понимания базовых основ?
>XTC
>Там предусмотрен алгоритм, который определит уместность его применения по наклону распределения
Ух как страшно. Ты его сам-то видел? Там просто тупой порог. Он отсекает всё что выше него кроме самого слабого, взвешенно по вероятности (которая второй параметр). Всё, это ВЕСЬ СЭМПЛЕР с твоим охуенно умным алгоритмом. Как это ему поможет справиться с ситуацией когда предсказание невинным образом входит в роут, с которого уже не сойти без шизы? Да никак, потому что он даже не видит прошлых токенов как DRY, а уж тем более не знает ПОЧЕМУ был совершён тот или иной выбор. В результате даже навязчивые идиомы никак не гасит, не говоря уже о стереотипах, и вариативности сетке не добавляет. Потому что он нихуя не знает о стереотипах или идиомах. Сетка впадает во всё те же характеры, просто разными словами. И будет у тебя не mix of arousal and anticipation, а blend of excitement and something else. При этом сетка неизбежно тупеет.
Продолжай пердолить сэмплеры и думать что ты что-то получаешь, я не против.
Я вот тебе предлагаю эксперимент. Возьми пустой контекст, безо всяких персонажей, и предложи любой сетке назвать что-нибудь рандомное. Максимально краткий промпт, чтобы как можно меньше влиять на выбор. Например, для инструкт сетки:
>Name a random color (1 word):
И наблюдай в логпробсах ахуенный обвал. Или просто свайпая можешь посмотреть как она циклится в основном на 2-5 вариантах из сотен возможных.
Т.е. да, конечно, какое-то предпочтение цвета должно быть, отражая распределение цветов в претрейн датасете. Но не такой обвал. Можешь не цвета, а что-нибудь ещё с дохуём вариантов. Будет то же самое.
Почему такое происходит, ну например https://arxiv.org/abs/2310.06452 https://arxiv.org/abs/2406.05587 (там говорят про debiasing и RLHF, но это красная селёдка, на самом деле там речь о вполне конкретных алгоритмах RL/SFT типа PPO, и сейчас все RLAIF заняты, возможности RLHF давно упёрлись в потолок)
>Столица Франции это
>Рандомное название города:
Тут как раз справятся сэмплеры, учитывающие крутизну распределения вероятностей напрямую (tfs) или через макс токен (топА, минП).
>семплер не знает...контекст ситуации
Это не его забота, в твоём примере сама ллм должна понять контекст и сбавить вероятность Парижа в рамках рп. Тут согласен с аноном выше, что сэмплер не должен уж совсем за модель работать, обрабатывая контекст.
>Там предусмотрен алгоритм, который определит уместность его применения по наклону распределения
Очень топорный. Разделение происходит на два случая: выше порога один токен - ничего не трогаем, выше порога больше одного токена - ебашим все из выборки. Даже если в последнем случае их десяток. И порогом это регулировать неинтуитивно. Мб кто-нибудь мог бы над ним помозговать кто? я? и сделать чтобы токены убирались выше некоторого числа, которое зависит от вероятности топ токена и пользовательского к-та. Вот этот варик уже лучше бы учитывал крутизну, кмк. Но даже тут вылезает проблема. Если топ токен большой, то вроде и нельзя ничего отрезать, а если он мелкий, то зачем вообще отрезать, все верхние итак будут вытаскиваться с примерно равной вероятностью, особенно если температурой со смуфингом жахнуть. Короче, сам сэмплер не очень удачный, как по мне.
>в случае с Парижем на первый токен будет овер 95%, а остальное лишь вариации написания на других языках или других вариантов токенизации вплоть до побуквенной. Взят будет именно правильный а остальные отсечены.
А теперь попробуй классический вариант сэмплинга для креативности, задрать темпу в хлам чтобы сделать распределение логитов более плоским, и заюзать отсекающий семплер типа top-p чтобы шизу отсечь. И сразу окажется что сэмплер нихуя не может разобрать, где крутизна оправдана, а где нет.
> логитов
Клован, после софтмакса вероятности.
>> Работает на уровне токенов, а лупаются идеи
>Бредишь, почитай как он работает.
Тут обосрался ты. Структурные лупы ни один семплер не может задавить.
>Это не его забота, в твоём примере сама ллм должна понять контекст и сбавить вероятность Парижа
Так это в ответ к этому
>Столица Франции это
>единственное валидное предсказание здесь "Париж", остальные мусор
Но выходит, что остальное не такой уж и мусор, если учитывать контекст.
>сэмплер не должен уж совсем за модель работать
Он не то, что не должен. Он не может. Чтобы он мог обрабатывать контекст и оценивать "правильность" вывода - он сам должен быть ллм. Причём не глупее исходной.
>Что именно в них неактуального? Наоборот, сраные ньюфаги даже их не читают, сразу лезя с идентичными вопросами, которые освещены.
Я когда вкатился, честно написал что нихуя не понимаю, потому что инфа хоть и полезна, но абсолютно не структурирована. Это как пытаться в вышмат по справочнику.
Спасибо тому анону, что прямо написал что и как делать и дал ссылку на сенку, действительно спасибо. Я без тебя хуй бы вкатился.
Так вот. Не хватает гайда в духе :
Ты уже сделал бочку и все еще ничего не понял.
Вот краткий гайд как ставить кобольт и таверну, вот эти параметры отвечают за то-то и это. Вот пресет. Запускай и наслаждайся, но дальше разбирайся сам.
А причина как всегда одна... https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
Верно угадал, разъебыватель твоего ануса.
> В случае структурного лупа нарратив-речь прошлые токены могут и не повторяться
И?
> Там просто тупой порог.
Для очевидных ответов его уже достаточно. Это шизосемплер от шизика, но даже в нем предусмотрено то, что ты имплаишь как невозможное.
> У кого тут не хватает понимания базовых основ?
У тебя, манька. Что-то спизданул не по теме и вырвав из контекста в надежде обнулить прошлое? Хуй там было, продолжаешь обтекать. С боевой картиночки особенно проиграл.
> Продолжай пердолить
Продолжаю пердолить твой ротешник в латентном пространстве.
Ну да. От сетки зависит, как раз тот самый пример где она будет разнообразнее а другая совсем примитивна. Но для оценок креативности во внимание стоит брать не только самое первое распределение, но и дальнейшие, что создаст огромное дерево. И в таких нарочито примитивных случаях лучше подойдет не дефолтный семплинг или первые распределения, а чуть посложнее типа beam search.
> А теперь возьми и открути у самолета крылья в полете и посчитай сколько из них смогут безопасно приземлиться.
> И сразу окажется что они вовсе не базопасные
Ебать клоун, искуственно испортить результаты чтобы сказать как все плохо.
Хотя и это уже проходили, достаточно температуру пихать в конец и там уже как не возмущай - всеравно останется лишь малый набор релевантных.
Еще долбоеб с навязчивыми идеями
Поэтому когда сидел на подобном пресете (высокая температура перед отсекающим), ставил самым первым сэмплером топА на мелкие значения, в районе 0.05-0.1. Он контрит подобные ситуации, слабо влияя на выборку в ином случае. Или можно подключить смуфинг больше единицы или даже немного меньше. Тогда тоже такие ситуации поправляются, потому что если исходно кривая очень крутая, то такие настройки делают её ещё круче. Вообще смуфинг тема, советую посмотреть по ссылке с сэмплерами в шапке, что он делает при разных исходных распределениях и разной температуре. Главное, не юзать мелкие значения при темпе выше единицы, потому что вот тогда вероятности размажет так размажет.

Что именно там не структурировано? В общем что такое ллм, по каким принципам она работает, какие методики используют чтобы получать результаты и базовые основы того как сейчас распространяют и запускают модели.
> Вот краткий гайд как ставить кобольт и тавернуОн т
Это что? Там буквально гит пулл@запустить и/или скачать бинарник@запустить.
>Там буквально гит пулл@запустить и/или скачать бинарник@запустить.
Это троллинг тупостью, буквально. Кроме установки это дерьмо еще нужно настроить, а большая часть всех зеленых вкатунов просто ебнется от интерфейса таверны, если даже разберется с кобольдом. Так что этот анон частично прав, инфа в вики полезная, но её недостаточно. Ну а выебываться тем какой ты сообразительный и снисходительно общаться со всеми залетными это чисто клоуничество.
>взять 7800xt
не надо не надо!, я самолично сижу на 7900хт ничего толком кроме оламы не работает, однажды я её солью и возьму что нибудь из 3090/3090ти/4090/5090
>От сетки зависит
Не зависит это от сетки. Любую возьми. Я сильно удивлюсь если найдёшь сетку с разнообразными ответами. я знаю ровно одну такую, ред пажама, тупое говно которое тренилось через пень-колоду, никто уже и не помнит её
Держи более удобную версию, нежели чем формат для PеDоFилов
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
>Пук в лужу
Быстро ты слился.
>а большая часть всех зеленых вкатунов просто ебнется от интерфейса таверны
А кто виноват, что люди так деградировали, что не могут разобраться в 3 5 7 9 вкладках? Я просто прощёлкал их, запомнил что где примерно и пользуюсь, ибо уже 20 лет с ПК и видал интерфейсы и посложнее.
Креативность ≠ вариативность предсказания некст токена, шизоиды. Креативность это вообще хуй знает что, шизотермин какой-то философский. Понятно только одно, что вариативность на неё вроде бы влияет.
Как же я ору, когда мрачная тьма мрачна в мержах дэвида, ты ставишь карточку какой нибудь ебанутой психопатки и со старта : СЕСТРЕНКА, ТЫ ТАКАЯ КЛАССНАЯ
Сразу с ходу, с ноги врываешься жизнерадостным шотой.
Тут же начинается : мальчик, ты ебанутый, отойди от меня блять.
Сразу с ходу, с ноги врываешься жизнерадостным шотой.
Тут же начинается : мальчик, ты ебанутый, отойди от меня блять.
>А кто виноват, что люди так деградировали, что не могут разобраться в 3 5 7 9 вкладках? Я просто прощёлкал их, запомнил что где примерно и пользуюсь, ибо уже 20 лет с ПК и видал интерфейсы и посложнее.
А вот дед мой жопу лопухом подтирал и не знал горя.
Тебе нужен полный спунфид? Раз такой умный и свежи воспоминания - напиши пошаговое руководство для самых маленьких. Через пару месяцев когда окрепнут - пойдет очередной наплыв шизиков с латентным пространством.
Можно сравнить базовые мистраль-квен-лламу, особенно версии постарше со всякими миксами или "аблибератед", там видно наглядно. Любой пост тренинг ограниченными датасетами или алайнмент сужает выход модели (в линках что ты скинул это подтверждается), и не всегда это стоит это воспринимать как что-то плохое судя по первым распределениям по абсурдно простым текстам. Алсо, это еще и следствие кормления длинными и подробными промтами.
Да не, это ты слился, отчаянно дерейля и сводя к щитпосту, чтобы отвлечь от бреда в том посте.
Долбоеб, который не понимает как работает модель, путается в понятиях, считает важным добавление понимания семантики в семплеры. Последнее - закономерное следствие первого, жаль слишком тупой чтобы понять насколько ты конченый.
Чсх, техникам возмущения логитсов с помощью сторонних моделей с учетом контекста уже не один год, генерация всего ответа вместо потокенной проходки тоже есть, да и много релейтед вещей в адекватном оформлении, а не в виде шизотеорий на основе глупости.
Но вместо того чтобы увлечься ими и даже что-то сделать, скуфидон - неудачник, собрав в кучу скудные познания из других областей включил типичный паттерн "у меня должно быть особое мнение в противопоставление популярным трендам" ради аутотренинга. Итог на лице.
Я сразу заметил включив драй что повторения ушли и свапы всегда новые, хз что у вас там за плацебо.
Без него буквально невозможно жить, нейронка зацикдивается и пишет слово в слово
>в линках что ты скинул это подтверждается
Ты не дочитал или не вник. Там говорится совсем о другом, что причина не в файнтюне в целом, а вполне конкретно в используемых алгоритмах. Типа, известные стратегии либо хуёво обобщают, но дают нормальное распределение. Либо наоборот хорошо обобщают, но режут целые траектории токенов за счёт того что какие-то предсказания могут увеличивать вес неограниченно. Это не фундаментальное ограничение, но третьего пока что не дано. Естественно при прочих равных выбирают те что обобщают хорошо, т.к. это в приоритете.
>Чсх, техникам возмущения логитсов с помощью сторонних моделей с учетом контекста уже не один год, генерация всего ответа вместо потокенной проходки тоже есть, да и много релейтед вещей в адекватном оформлении
Ого, инопланетные технологии! Где это такое прошлое-будущее с цельными ответами вместо авторегрессии?
>Долбоеб, который не понимает как работает модель, путается в понятиях, считает важным добавление понимания семантики в семплеры. Последнее - закономерное следствие первого, жаль слишком тупой чтобы понять насколько ты конченый.
Так ты кроме >пук, на представленные примеры ничем не ответил.
Пока их не читал. Несовершенство не что-то новое, имеем что имеем, а то в целом наблюдение.
> ррряяяя я не обосрался, а ну быстро делай так как я сказал или я прав!
В голос с шизика, потому так и живешь
кто нить уже щупал вот такую хуйнюшку от мозилы? можн закинуть в список однокнопочных инсрумемтов
https://github.com/Mozilla-Ocho/llamafile
я не смок пощупать у меня на амуде крашится не запускается с выгрузкой слойёв нав гпу
https://github.com/Mozilla-Ocho/llamafile
я не смок пощупать у меня на амуде крашится не запускается с выгрузкой слойёв нав гпу
Этому говну уже год. Бесполезный кал.
>Без него буквально невозможно жить
Смени модель, чувак.
>Долбоеб, который не понимает как работает модель, путается в понятиях, считает важным добавление понимания семантики в семплеры.
Я написал ровно одну фразу "Структурные лупы ни один семплер не может задавить.". Всё. Остальное ты уже додумал и смешал с остальными анонами в треде. И на эту фразу у тебя ответа нет, ибо его быть не может, ибо это истина в последней инстанции, и даже сам Иисус со мной согласился бы.
>генерация всего ответа вместо потокенной проходки тоже есть
Но используется буквально нигде.
Нет, там было
> а лупаются идеи
и после этого представление паразитного ухватывания шаблона (что может проявиться при поломках или кривом промте) в виде серьезной фундаментальной проблемы. И все это на фоне прочей дичи, подобной той, что местные поехи любят заводит. Если там суперхуевая моделька что таким страдает и не хочешь с нее слезать - просто добавь в префикс инструкции рандомайзер средствами таверны, в котором будет микроинструкция по структуре ответа. Но это костыль, который лишь отложит проблемы, появятся другие.
> Но используется буквально нигде.
Естественный отбор. Точно также как не применяют кодировку фиксировано определенного латентного пространства в виде токенов и закидывание на вход или же генерация его с помощью ллм. Есть рабочие примеры но они только подчеркивают несовершенство и глубинные проблемы.
Возможно, со временем придем к более оптимальному решению, в котором вместо слогов токены действительно будут ближе к условным идеомам, и кодер-декодер будет отнимать до трети весов, но едва ли это будет скоро и в том примитивном понимании, что вкладывают поднадусеровые борцы с токенизацией.

Ну-ка, так где одним махом ответ генерится? За язык тебя никто не тянул. Давай-давай.
Так лень бодаться с очередным городским сумасшедшим, пердолящим очередной вечный двигатель в виде сэмплеров, но посмотреть как ты вертишься будет забавно.
Корчишь из себя знатока с моноклем, но из-за гребня пропустил что притаскивали в последних тредах, хорош.
>Нет, там было
Что ты какой дегенерат? Я тебе уже точную свою цитату привёл, а ты всё найти её не можешь. Про идеи писал другой анон.
>представление паразитного ухватывания шаблона (что может проявиться при поломках или кривом промте
Оно появляется всегда при длинном контексте, ибо неотделимо от самого формата чата.
>Естественный отбор.
Просто накидывание компьюьта даёт результат здесь и сейчас, а на проработку умной архитектуры нужны умные люди, которых нехватает.
>представление паразитного ухватывания шаблона (что может проявиться при поломках или кривом промте) в виде серьезной фундаментальной проблемы
Прочувствуйте уровень понимания сэмплерошиза. Кулибин никогда не слышал о том как тренят ЛЛМ (длинные примеры без мультитурн повторов нихуя не просто сгенерить), ни о внутриконтекстном обучении, но придумывать что всё поломалось и "просто возьми не лупную модель" горазд
Прочувствуйте уровень понимания сэмплерошиза. Кулибин никогда не слышал о том как тренят ЛЛМ (длинные примеры без мультитурн повторов нихуя не просто сгенерить), ни о внутриконтекстном обучении, но придумывать что всё поломалось и "просто возьми не лупную модель" горазд
Ку, теслабояре. А в каком интерфейсе есть Кокоро+Спич рекогнишн+Поддержка ггуф, при этом чтобы текст озвучивался постепенно, каждое предложение, а не сразу весь ответ? В силли таверн только устаревшие ттс и озвучивание полноценного сообщения, а не каждого предложения постепенно.
> чтобы текст озвучивался постепенно
Нигде. Это надо мультимодальную LLM, умеющую стримить речь.
В олламе есть. Каждое предложение озвучивает, потом когда следующее сгенерируется, озвучивает следующее.
Это совсем хуйня, как будто речь аутиста с замолканием на 10 секунд.
Какие 10 секунд? Лёгкие ттс генерируют ответ моментально. А скорость написания предложений зависит от твоей скорости генерации. Самое долгое как раз это спич рекогнишн.
В любом случае, хуйня для тебя. Для меня полноценная тулза с которой можно полноценно разговаривать без задержек. Только в силли таверн эта функция не реализована в отличии от олламы и до сих пор нет кокоро.
Агрессивно лезешь в чужой разговор, подменяя одно другим, ноешь о своих проблемах. Выходит что сам дегенерат.
> Оно появляется всегда
Только у дегенератов, лол. Не, ты серьезно? 3-4 поста когда идет какое-то развитие одного действия может структура повторяться, а потом с прогрессом меняется под действо. Может стоит поставить нормальную модель и не срать в промт?
> Просто накидывание компьюьта
Не просто. Проблема херни и нерационального использования существует, но даже это лучше чем тащить шизоидеи из безумных умом таких всезнаек.
Как не почитаешь подобные обсуждения - каждый эксперт и уже разработал свою новейшую и продуманную архитектуру, которая решит все проблемы, будет эффективна и победит великое зло токенизации. И мешает ей лишь сговор хитрых корпоратов, которые подмяли под себя весь компьют, а вот если бы дали!
Ничего не напоминает? Буквально шайка шизиков со свободной энергией, на которых охотятся нефтянные лоббисты, ух.
С компьютом и прочим проблем нет - бери ни хочу, все доступно. Дело в том что предлагаемое - мертворожденная хуета с нерешенными фундаментальными проблемами, или вообще полный бред.
Так порвался что боится даже линкануть, кек. Ну ничего, завтра одноклассникам расскажешь про новые термины что подметил.
Анон только добрался до борды, спасибо! попробую это направление
>Агрессивно лезешь в чужой разговор
>написал одну фразу
Поколение снежинок?
>а потом с прогрессом меняется под действо.
Меньше, чем надо.
>Может стоит поставить нормальную модель
У меня терабайт моделей, не считая удалённые и перенесённые в архив. Все говно?
>И мешает ей лишь сговор хитрых корпоратов
Шиз, таблы. Мне мешает отсутствие свободного времени и лень, остальное ты выдумал.
>бери ни хочу, все доступно
У меня нет 100 млн для тренировки модели хотя бы уровня GPT4. Ну и главное нет нужного объёма данных и денег, чтобы нанять негров эти данные разгребать.
Алик, выводи ребят!
> Меньше, чем надо.
Скиллишью
> У меня терабайт моделей
Старье или инцестомерджи, если только там не архив полновесных больших моделей.
> Мне мешает отсутствие свободного времени и лень
ОН У НАС УМНЫЙ, ПРОСТО ЛЕНИВЫЙ. Хорош, поднял настроение на вечер.
> У меня нет 100 млн для тренировки модели хотя бы уровня GPT4
Зато какие аппетиты, если бы были то сразу бы как натренил, ух! Но увы, занятой и ленивый, такой гений пропадает.
И даже на что-то простое и реальное для среднего хоббиста нет. Не только денег, а в целом скиллов и понимания чтобы собрать датасет и организовать тренировку. Вот и остается ныть да придумывать инновации, главное подальше от реальности чтобы легче находить оправдания или жонглировать абстракциями.
>У меня нет 100 млн для тренировки модели хотя бы уровня GPT4.
А смысл? В гпт-4 не смогли. Упёрлись в потолок, всё. Тем временем мета выкатила бумагу, в которой буквально пишет о том, что обсуждалось итт около года назад и говорит, что эту херню нужно запиливать в каждую модель - улучшает вывод в 4 раза, модель 1.3b перформит на уровне ллама2 7b. А ллама3 с дополненной архитектурой начинает перформить на уровне лламы3.1 после обучения на 1Т токенов, не смотря на то, что вторая обучена на 15Т. А это внезапно сокращение расходов на трейн для получения сопоставимых результатов.
https://arxiv.org/html/2412.09764v2
Вот это тоже смешно на самом деле.
>As the number of floating-point operations is negligible, we expect this operation to be solely limited by the GPU memory bandwidth, but find multiple inefficiencies in PyTorch’s implementation in practice. We implemented new and more efficient CUDA kernels for this operation. Our forward pass optimizes memory accesses and achieves 3TB/s of memory bandwidth, which is close to our H100 specification of 3.35TB/s (compared to less than 400GB/s with PyTorch’s implementation).
Так что ждём более умных моделей, но жирнее по vram. Намного жирнее.
>Даже п-сэмплеры это крапшут. Сам механизм отсеивания логитов ущербен, ибо работает на уровне токенов, а не в латентном пространстве. Сэмплеры не имеют доступа к скрытому состоянию модели и понятия не имеют о семантике токенов которые отсеивают. Скрытое состояние частично передаётся на следующие токены в результате авторегрессии (без планирования наперёд некоторые ответы просто невозможны), но чтобы его декодировать тоже нужно понимать семантику, а семплер это просто тупая формула.
Поэтому надо делать умный семплер на базе самой модели. На какой-нибудь дополнительной не получится, надо навешивать лору на базовую модель и не трогая ее пускать через лору обработку.
Например, берем 200 токенов с выхода, сортируем и пускаем их в модель блоком в префил, тренировка - выбирать один токен ответа. Это одна итерация инференса сверху + обработка 200 с небольшим сырых токенов контекста. Да, будет раза в 3-4 медленнее итоговая модель, но зато какая генерация! Если все сделать правильно, модель будет работать на пределе своих возможностей в любой ситуации, на любой разумной длине контекста, без лупов, без глинтов. Для маленьких моделей особо актуально, да и посильно для сообщества.
У разбирающегося анона сразу возникнет вопрос, а собственно каким хуем мы это будет учить? Отвечаю.
Использовать любой исходный текст напрямую мы не можем, это не отличается от стандартной тренировки и в лучшем случае даст +2% за счет того что такая схема дает спейс для "латентного тринкинга", поэтому единственным вариантом остается GAN.
Только дискриминатор будет обучать не саму модель, а семплер. Дискриминатор можно сделать как из базовой модели, так и из более умной. Он тоже должен быть обучаемым.
Настройка его, это конечно отдельная, большая история, но главное, что это рабочая схема. Которая, важно, полностью перестанет быть рабочей, если мы попытаемся применить ее к обычной ллм с классическими семплерами. Именно введение обучаемого семплера дает возможность применить GAN. Хотя в теории какое-то обучение с обычной ллм возможно, но классический семплер будет очень агрессивно и очень быстро затирать эффект от гана.
Это вам не на рп-слопе профайнтюнить нейронку, тут поприседать придется. Во первых, нужно добавить некоторое количество обучаемых токенов в модель, в какие-то будет впрыскиваться рандом, без которого ничего не выйдет, другие токены или один скорее всего надо передавать из одной итерации в другую, чтобы модель могла "рассчитывать общий кредит" когда будет тратить его на выбор предсказуемости текущего токена, чтобы в сумме получить правильное распределение и наебать дискриминатор.
В принципе хорошей оптимизацией будет сначала хотя бы научить модель хорошо имитировать классический семплер с разными параметрами, которые должны присутствовать в системпромте или в обучаемых токенах.
Важно, базовая модель должна оставаться нетронутой, обучается только лора, как минимум на этом этапе модель с лорой должна вообще не расходится с базовой, в дальнейшем обучении с ганом как регуляризация тоже должен присутствовать коэффициент привязки к базе.
Дискриминатор должен не потокенно проверять вывод, а поблочно, иначе сам дискриминатор ничему умному не научится. В процессе обучения размер блока можно будет снижать наверное, а может даже и нужно. Сам блок должен начинаться не снихуя а с контекста. Дискриминатор оценивает насколько реалистично модель подстроилась под контекст и стиль. Форматные лупы и глинты будут очень сильным триггером для дискриминатора. Чем больше блок, тем активнее он будет их чистить.
Но чем больше блок дискриминатора, тем сложнее на этом учить "генератор" - саму ллм+семплер.
Если бы дискриминатор мог бы дать ответ по 1 токену, модель бы училась быстро и хорошо, но он никогда не сможет это сделать чисто физически.
Нужно обвешиваться всякими регуляризациями, например коэффициент kl дивергенции между распределением обычного семплера и умного, чтобы его не уносило в шизу.
Может генерацию при обучении стоит разбавлять обычным семплингом, чтобы умный активнее фиксил ошибки и рвал обратную связь. Вообще стоит подумать о том, как можно ввести такой коэффициент обратной связи, чтобы вручную им управлять.
Вся схема напоминает алгоритмы типа dpo/ppo, но я в них не шарю, не могу сказать, может быть это вообще классическая для них задача и можно взять готовый пайплайн и заниматься пердолингом только с обучаемыми токенами. Может быть можно и совсем без них, но очень важно что куда-то должен впрыскиваться шум с известным для модели распределением, на который она будет опираться. И какие-то латентные токены для "планирования" наперед таки наверное будут полезны.
Еще думал над схемой, где модель по сути пытается продумать как бы сразу на 2 токена вперед, а не 1. Но чет она выглядит малореалистично. В ней надо перепердоливать сам механизм внимания. Для пачки токенов, которые в нее загоняются после предсказания от исходной модели надо делать анмаскинг, чтобы они друг с другом общались, + для последнего токена тоже. Тогда можно вообразить, что модель одновременно выбирает одного кандидата из входа и пытается подстроить выходное распределение под него же. Но тогда это уже полностью новая модель, которая генерирует распределение для себя же, а не как бы нетронутая чистая модель с лорой которая подключается только на момент семплинга. А если использовать по схеме тандемом с базой, то непонятны плюсы. Но может они и есть. Так то и в принципе плюсы двойного предсказания не сильно понятны, в плане теоретической обоснованности.
Тут надо еще вводить обучаемый токен для выбора из 200 токенов окончательного, чтобы все работало одновременно. Только это не входной обучаемый токен, а выходной.
Хз короче.
Кстати, про семплинг из умного сеплера я ничего не сказал, и тут очевидно должен браться тупо максимальный токен. Может быть на манер диффузии можно будет просемплировать несколько раз, уменьшая выборку, ради выдрочки процентов. Число в 200 токенов на входе, по логике, не должно быть фиксированным, а браться с учетом уровня активаций.
Вопрос не в охуительных схемах, а в том как они работают на практике. В масштабирование всё упирается, очень дохуя схем работают в голове, просто дохуя на мелкомоделях на практике, и лишь единицы на моделях фронтир масштабов.
Я когда архив просеивал например видел работу которая предлагала тупо фидбэк с пошаговой аккумуляцией от последнего линейного слоя (до снижения размерности) до сэмплера, через отдельно натрененный параллельно с файнтюном сетки адаптер, который учитывает отсеченные траектори токенов PPO при файнтюне. Что-то типа того о чём ты пишешь, если я правильно понял. Но это всё было проверено на 3Б модельке на коленке, поэтому хули обсуждать? Вопрос в том будет ли это работать на больших моделях, идей-то десятки. Напомню что даже такие старые вещи как 1.58b битнет так никто и не продемонстрировал на практике на больших моделях.
>где модель по сути пытается продумать как бы сразу на 2 токена вперед, а не 1
deepseek v3 вроде генерит по 2, или это я путаю с параллелизмом их каким-то, я не вникал (а надо бы)
Стоит ли вообще покупать одну 3090 ради апгрейда до 35б?
Сейчас сижу на 12б, не думаю что будет прям сильный скачёк в качестве
Сейчас сижу на 12б, не думаю что будет прям сильный скачёк в качестве
у меня тоже 12Гб (3060), как я понимаю просто для инфиренса 3090 вполне хватает
но я жду, чтобы цены немного упали перед апгрейдом
планирую подождать полгода-годик
Command-R-35B-Dark-Horror-V2-D_AU-Q5_k_s.gguf - 24.3 GB
Докупаешь одну 4060ti 16gb и в путь
Если у меня блок питания на 700В и уже стоит одна RTX 3060 есть ли смыл покупать еще одну или мощности не хватит?
Какие тут страсти да маняврирования...
Май брейн тремблес энд шиверс раннинг май спине.
Май брейн тремблес энд шиверс раннинг май спине.
Стоят два плашки ддр4 по 16гб, есть еще две по 8гб. Ставить их или заруинят двухонал?
Обычный Пантеон чухня, слишком клодослоп протекает.
Юзайте тот что с припиской Pure.
Юзайте тот что с припиской Pure.
Кстати, хотел поблагодарить. Спасибо! Почти то что я искал. Ещё бы там были опции вроде фильтра по персонажам, или частоты срабатывания, было бы вообще охуенно.
Сижу на 3060 с 12гб. Учитывая что она досталась за 30к то в целом наверно одно из лучших соотношений врам и цены сейчас.
Если поднажать то можно запихнуть 12б Q6 и 12888 контекста довольно легко.
Думаю не купить ли такую вторую даже.
Тогда какие настройки обычно вы используете? Можете показать? Лучше всего просто скриншотом настроек.
Я понимаю, всё зависит от модели, но интересно увидеть варианты анонов.
Лично я имел положительный опыт с XTC на некоторых моделях, но он какой-то полурандомный.
темпа обычно 0.8 - 1.3, динамическая разлёт 0.5
топ 0.9 - 0.95, мин 0.05 - 0.1
DRY / XTC / Mirostat не работают на моделях младше 32B включительно, только ломают их.
> На какой-нибудь дополнительной не получится, надо навешивать лору на базовую модель
> и не трогая ее пускать через лору обработку
Погугли что такое лора
> У разбирающегося анона сразу возникнет вопрос
Что курил этот поехавший. Задача предсказания уже висит на исходной модели, а получить все вероятности прошлых токенов по известному промту можно лишь обработав этот контекст, без предсказания нового. Вместо 200токеновой шизы можно вести инфиренс двух моделей с полным промтом, используя более мелкую или для ускорения, или наоборот для вычитания тривиальных решений, это было еще в 23 году.
> нужно добавить некоторое количество обучаемых токенов в модель
> в какие-то будет впрыскиваться рандом
> дискриминатор будет обучать не саму модель, а семплер. Дискриминатор можно сделать как из базовой модели, так и из более умной
> базовая модель должна оставаться нетронутой, обучается только лора
> коэффициент kl дивергенции между распределением обычного семплера и умного
> генерацию при обучении стоит разбавлять обычным семплингом (!)
Да все хуйня. Смотри, берешь семплер от каломаза, но не ставишь его в llamacpp, а закидываешь на кластер и начинаешь его обучать хотябы на 1Т токенов. Только чтобы без рп слопа! На всякий случай пару лор для безопасности чтобы дивергенция не зашкалила, и еще слои атеншна через дадекаэдральную свертку пропускать, а то потом лупы будут. Или еще лучше взять семплеры с стабильной диффузии, там sde karras хвалили, вот его обучать. И не по 200 токенов а по 400, такая бомба будет, закумишься.
Только не смей воровать идею, про нее уже умные дяди знают скоро сделают.
> deepseek v3 вроде генерит по 2
Там два активных эксперта, каждый из которых предсказывает свои распределения, потом усредняется.
У вас на 3060 звук не трещит?
Я заебался уже ллм/любая игра + браузер и звук лоботомируется

Посоны, может вы подскажите, как закидывать персонажей в Silly tavern так чтобы если попадутся одинаковые они не дублировались?
> ОН У НАС УМНЫЙ, ПРОСТО ЛЕНИВЫЙ
Ну я, да.
Во-первых, можно ее андервольтнуть.
Во-вторых, 700 Вт хватит (200 + 200 + 100 на проц примерно, у тебя же вряд ли топовый, + 100 туда-сюда = 600, и это в пике, на деле гораздо меньше).
Но если у тебя настоящие 700, а не Xilence (они не плохие, просто их 700 — это настоящие 400).
А ты безумец видюху как вывод звука что-ли используешь?
У меня недавно забавный эвент случился. Экспериментировал с настройками по впихиванию невпихуемого в память видюхи, тут смотрю артефакты на экране. Ну думаю пиздец. Запустил фурмарк - всё ок. Проверил память несколькими тулзами - всё ок. Ребут - артефакты.
Оказалось просто кабель от монитора отошел.
А и правда кстати, куда девался битнет? Уже год практически прошёл, по сути вечность, но всё никак битнетовые сетки не появятся. Ладно даже гигантские модели, но хотя бы мелочь для эдж девайсов или классификации какой-нибудь, всё равно нет. Может нихуя он и не работает?
>Может нихуя он и не работает?
"Уж сколько их упало в эту бездну"(с)
Выше по треду кидали ссылку на документ, в котором с примерами доказывалось, что нефиг хитрить со всякими методами, а просто докидывайте деньги на оборудование - так результат всегда будет лучше.
>А и правда кстати, куда девался битнет?
А я всё QTIP'а жду, как дурак:
https://www.reddit.com/r/LocalLLaMA/comments/1ggwrx6/new_quantization_method_qtip_quantization_with/
Глухо, как в танке. Походу очередной революционный пук.
Всм как вывод звука?
Обычно, прдключил дп от видюхи к монику и всё

>И даже на что-то простое и реальное для среднего хоббиста нет.
Есть, вот мои пробы с softmax_one, в контролируемых условиях на полписи лучше, но не сказать чтобы критически. Надо больше тестов.
>В гпт-4 не смогли.
Что не смогли? Модель есть, рабочая. Вот в GPT5 не смогли, это да.
>Тем временем мета выкатила бумагу, в которой буквально пишет о том, что обсуждалось итт около года назад
В принципе... Да, похоже. Ждём, когда они научатся разделять эту память на различные тематики и прочие теги, чтобы подгружать во врам только нужное. Ещё пару лет от момента, когда они прочитают этот пост, до реализации...
На DDR4 с этим обычно всё нормально, если планки близки по возможностям. А вообще, купи набор, сейчас DDR4 по цене семечек идёт.
>А ты безумец видюху как вывод звука что-ли используешь?
Я другой анон, но у меня есть рабочий ноут и основная пукарня, так вот, чтобы звук не перетыкать, у меня наушники в монитор включены. Качество правда соответствующее, но я всё равно глухой.
>а просто докидывайте деньги на оборудование
Тут суть в том, что это говно должно работать на оборудовании конечного пользователя. А оно так просто не докидывается, телефоны и так уже в гранаты превратились по объёму запасённой энергии а пейджеры буквально.
А чего трещит то тогда если у тебя звук никак к видюхе не привязан? Если ты DP или HDMI подключишь например к телевизору то через них вполне будут передаваться звуки.
>Я другой анон, но у меня есть рабочий ноут и основная пукарня, так вот, чтобы звук не перетыкать, у меня наушники в монитор включены. Качество правда соответствующее, но я всё равно глухой.
Не ну это можно понять, если ты ноут к монитору втыкиваешь. Даже менеджмент проводов удобней становится.
У меня например вообще вывод звука через USB наушники.
> Выше по треду кидали ссылку на документ, в котором с примерами доказывалось, что нефиг хитрить со всякими методами, а просто докидывайте деньги на оборудование - так результат всегда будет лучше.
Биттер лессон это, конечно, база. Но не доказательство, того что архитектуры вообще улучшать и оптимизировать не надо. Если бы трансформеры остались на уровне 2017 года, практически никакого прогресса бы в этой области не было, а локально даже гпт2 запустить было бы нереально.
А я ебу, поменял видюху и начало трещать значит дело в видюхе.
Вот щас к встройке дп подключил и треска нет, но так жсинк не работает и вообще это хуйня костыльная какая то
https://github.com/ikawrakow/ik_llama.cpp/pull/113
Зря ждёшь, уже давно разжевали, почему ждать не стоит.
>Вот в GPT5 не смогли, это да.
Объебался с цифрой, но главное, что суть ясна.
>когда они научатся разделять эту память на различные тематики и прочие теги
Вот этого я бы точно ждать не стал. Скорее ожидал бы разделения ЛЛМ на части, но не вдоль, как MOE, а поперёк. Причём слои памяти это первый шаг в этом направлении. Достаточно компромиссный, но тем не менее. И чем больше будет проблем с компьютом и упиранием в потолок - тем быстрее получим что-то качественно новое.
>это говно должно работать на оборудовании конечного пользователя.
А облачные сервисы как себя окупать будут? Слыш, купи.
>If you have a newer Nvidia GPU, you can use the CUDA 12 version koboldcpp_cu12.exe (much larger, slightly faster).
Больше в смысле меньше контекста влезет или просто вес файлика?
Больше в смысле меньше контекста влезет или просто вес файлика?
Пробуй патчить драйвер через NVCleanstall. Если не поможет, то полностью отключать NV Container - тогда весь софт куртки перестанет работать.
Хули ты хотел, у куртки софт просто максимально конченый, даже хуже амуды.
Ну или можно откатиться на драйвер из 2022 года, в котором только куда 11.8 доступна.
> уже давно разжевали
И давно обоссали, то что он скорость неоптимизированного говна по формулам считает вместо бенчмарков.
>вес
Забавно как различается оценка поста, тут голосов гораздо меньше
https://www.reddit.com/r/singularity/comments/1hzg6yp/bro_whaaattt/
Похоже в сингулярити больше пользователей онлайн ии и это их задело
Фалкон в нем есть и его даже можно запустить. Почему-то всем кто носился резко стало похуй.
> вот мои пробы с softmax_one, в контролируемых условиях на полписи лучше, но не сказать чтобы критически. Надо больше тестов.
Вот это интересное, распишешь подробнее?
> Вот в GPT5 не смогли, это да.
Говорят что технически смогли, но результат не тот что ожидается, на фоне 4о, о1 и прочих слишком дорого выходит.
>дп подключил
>но так жсинк не работает
Наоборот же гсунк только через ДП и работает...
>Вот этого я бы точно ждать не стал.
И это печально.
>или просто вес файлика
Да.
>Вот это интересное, распишешь подробнее?
Просто реализация https://www.evanmiller.org/attention-is-off-by-one.html , расписывал тредов 40 назад. Результат на прошлом скрине, перплексия незначительно улучшилась, не более.
based
> Биттер лессон
Очень на руку куртке кстати
анонычи, поясните еще разок, чего там за новые профессоры выкатывают? NPU если я правильно понял фигня без задач для стрижки гоев которая фон на вебке может менять? а AMD ai max - чего там за тема? если я правильно понимаю попытка в много универсальной памяти и в теории должно уметь гонять LLM? а в чем разница с обычной встройкой? если встройка тоже юзает RAM? типа больше рама можно загнать? пока что насколько я понимаю это анонсы только и нормальных тестов нет? или есть всеже? и почему если это чудо представляют как что-то для ИИ туда ставят DDR память а не HBM? и чего там Седой Лезермэн в противовес предлагает?
Так битнет это не хитрёж с методами, он никак не противоречит. Это просто оптимизон по сложности хардвера и потреблению памяти. Разные методы QAT юзают потихоньку, а битнет ещё нет.
>Погугли что такое лора
Сам погугли, перед тем как жопой читать.
Лора навешивается на модель только для этапа семплинга, сама модель которая дает исходное распределение остается нетронутой. Можно в теории использовать любую модель для генерации, если тебе не жалко гонять две модели по памяти.
Проблема только в том что будет рассинхронизация контекста, но это по идее решаемо, если это учесть, с разными моделями будет два потока контекста, очевидно.
>Задача предсказания уже висит на исходной модели
Модель предсказывает полный спектр распределения только в конце, в моей схеме модель видит все токены с самого начала, и не в одном потоке латентов, а в 200 потоках сразу.
Обычную модель ты не можешь эффективно ганом учить. Такую - можешь.
>Вместо 200токеновой шизы можно вести инфиренс двух моделей с полным промтом, используя более мелкую или для ускорения, или наоборот для вычитания тривиальных решений, это было еще в 23 году.
Спекулятивное декодирование не имеет никакого отношения к этой теме.
>Да все хуйня ...
Ты даже не понял смысла хотя бы одного пункта, и сразу высрал шизу, я поржал, ахаха, (нет). Дегенерата кусок, это тоже ты тут высирался что в ллм латентов нет и между слоями прям токены гоняются?

Аж чаем брызнул
>и почему если это чудо представляют как что-то для ИИ туда ставят DDR память а не HBM
Потому, что и так сожрут. Сделать хорошую вещь пока что никто не заморочился - изучают рынок. Потом, когда эту хрень по сильно завышенной цене никто не купит, маркетологи разведут руками и скажут, что рынок не созрел.
а не совсем по теме треда, но вдруг кто подскажет, есть ли какие-нибудь нормальные программы типа Anything-LLM, которые умеют по апи с модельками работать и скармливать различные документы, веб-поиск, озвучивание итд? Anything-LLM капец багованый просто (уму не растяжимо, задал настройки апи, не можешь этого изменить, вообще...)
> Модель предсказывает полный спектр распределения только в конце
> не в одном потоке латентов, а в 200 потоках сразу
> Обычную модель ты не можешь эффективно ганом учить. Такую - можешь.
> в ллм латентов нет
> между слоями прям токены гоняются
Утром у тебя вышел латент и намотался на лору? Так включай семплинг, ганом натренишь и отпустит. Главное чтобы хайденстейт не прищемило.
Сука как перестать орать
Че ржешь, не видишь робот на коробке сгенерированный? То то же!
Хороших и функциональных - не особо, что-то узконаправленное, багованное, странное и т.д. Чаще под свои задачи пишут ибо может быть много специфики.
>Чаще под свои задачи пишут ибо может быть много специфики
печалька немного, потому что под рабочие задачи хотелось бы что-то универсальное... с другой стороны ниша открыта, можно вкатываться....
Шизик даже не стал отрицать.
>Сука как перестать орать
Попробуй начать с пруфов своего пиздежа, вместо того чтобы истерить и кого-то пытаться учить. Сука, по мнению долбоеба в трансформере латентов нет, только токены и святой дух между слоями идут, видимо.
Чсв хуйлуша вставила свой тейк про спекулятивный декодинг вообще не впопад. Орать тут только с тебя будут и только с твоих охуительных неуместных тейков.
Спекулятивный декодинг на качество модели абсолютно никак не влияет в положительном ключе, только ускоряет инференс, есличо.
Где в таверне кнопка отключить автоответ после ввода пользователя? Чтоб кнопку ответа самому жать надо было каждый раз.
Ути какой агрессивный шизик~ Ты не понимаешь что себя только глубже зарываешь? А в изрыгаемых оскорблениях буквально себя описываешь, дурной глупец поверил в себя и бредит, а потом полыхает от того что с него только смеются.
Аноны, на данный момент у меня пк с rtx 2060, core i5 10400f, озу 32гб поддерживает высокую частоту но из за материнки и процессора частота ниже. Материнская плата поддерживает максимум 2666-2900 мгц озу и pcie 3.0, поэтому думаю потихоньку делать апгрейд к выходу rtx 50.
Посему у меня встал вопрос, есть какой то смысл покупать новую материнку (соответственно к ней процессор) и делать полный апгрейд? Может для нейросетей будет достаточно просто купить новую видеокарту?
Посему у меня встал вопрос, есть какой то смысл покупать новую материнку (соответственно к ней процессор) и делать полный апгрейд? Может для нейросетей будет достаточно просто купить новую видеокарту?
Да, бери 4090.
разве частота озу не влияет?
Если у тебя модель будет выгружена не во всю видюху - роляет, но там разница будет между 2 токенами в секунду и 5 токенами в секунду, что в сравнении с видеопамятью два одинаковых сорта говна
Не. ну можно подождать нормальных тестов того что там красные выкатывают, обещают же ж в 2 раза больший перформанс, в сравнении с 4090, где половина слоев в оперативке (само собой 70В не влазит в 4090, и такой расклад выгодные цифры даёт), но много памяти, а если это еще и в виде минипк будет собрано то весьма выгодная тема, возможно даже выгоднее видеокарты
Пока что глубже закапываешь себя сам только ты, ибо ты дважды обосрался, сначала снихуя упрекнув меня что я не понимаю лору, хотя в моей схеме никаких противоречий нет, чтобы она с лорой работала. Разве что готовый код нельзя просто так взять, потому что ее отключать и подключать надо, для двух этапов. Потом приплел зачем-то спекулятивный декодинг.
Вместо попыток в траленк и безпруфный срач лучше бы сам предложил модель, которая решит исходную проблему:
> Семплер даже не может отличить простейшие ситуации.
> >Столица Франции это
> единственное валидное предсказание здесь "Париж", остальные мусор.
> >Рандомное название города:
> куча валидных предсказаний, мусора мало.
> Отрежь больше и получишь малую вариативность. Отрежь меньше и получишь шизу.
> Как сэмплер различит эти две ситуации? Да никак, он нихуя не знает о городах, а скрытое состояние и концепты городов из латентного пространства трансформера до него не доходят, до него доходит только сортированный токен бакет.
И моя модель это решает полностью. В влажных фантазиях пока, конечно. Но это легко проверяемо. Если модель может научиться эмулировать обычный семплинг, с учетом вариации его параметров, то логично предположить, что она сможет работать чуточку лучше, если ее правильно учить.
Распределение токенов у моделей после dpo/ppo становится намного уже, чем у базовой модели после претрена. Именно потому что итоговое обучение идет на синтетике, собственной генерации модели, чтобы она как бы подстраивалась под семплинг. Которого на претрене вообще не существует.
Такой пайплайн сам по себе очень напоминает GAN, только генератор и дискриминатор не связанны градиентами. Хотя в моей схеме их тоже так не связать, так что я упоминаю GAN скорее чтобы логику передать.
Моя схема отличается от sft, dpo/ppo по сути тем, что собственно тебе надо будет потом гонять на инференсе модель дважды, плюс обрабатывать дополнительный кусок контекста, но самое главное что эти классические методы "проходят" поверх абсолютно рандомного неконтролируемого семплера, из за чего для эффективного (до)обучения надо дохуя примеров генерить, валидировать. А тут рандом будет контролироваться самой моделью, если научиться впрыскивать в нее шум через обучаемые токены. Либо каким-нибудь другим способом, это не принципиально.
У реального текста "температура" сильно варьируется от слова к слову, даже самыми хитрыми семплерами ее не апроксимировать. Модели приходится очень сильно изворачиваться, чтобы через сэмплер получился связный текст и модель предпочтений его не завернула. Возможно моя схема даже тут сможет выиграть, и сделать построен эффективнее. Не знаю, корпы очевидно уже должны были этот момент отресерчить, и наверно я не вижу тут какой-то ключевой проблемы... Если не считать проблемой снижение скорости в несколько раз.
Можешь объяснить в чем я неправ, валяй, аргументированно только, а не снова жидко пукнув. Хотя я как бы и не претендую на сверхценность этой идеи, это так, шизомысли вслух. Но ты даже с ними не справился чет.
Перенесу реквест из aicg
Посоветуйте креативную около-100b модель для ролеплея от лица тянки, которая может в жесть и не пишет аполоджайс. (Мне нравятся такие игры, как Fatal Frame с женской гг)
Посоветуйте креативную около-100b модель для ролеплея от лица тянки, которая может в жесть и не пишет аполоджайс. (Мне нравятся такие игры, как Fatal Frame с женской гг)
А есть смысл связываться с чем-то подобным в расчете на ИИ (локальные LLM, картинки и т.п.)? И будет ли такое нормально работать под какой-нибудь обычной Win10Pro, чтобы без всяких "Server" и т.п. (при том, что с Линуксами я также не дружу)?
https://www.ozon.ru/product/komplekt-huananzhi-x99-dual-f8d-plus-2011-3-2-h-xeon-e5-2699-v3-2-3-ggts-256-gb-ddr4-s-kulerami-1624162086
https://www.ozon.ru/product/komplekt-huananzhi-x99-dual-f8d-plus-2011-3-2-h-xeon-e5-2699-v3-2-3-ggts-256-gb-ddr4-s-kulerami-1624162086
Нах тебе материнка, пару 3090 покупай.
хуанан будет работать, терпимо, сам с хуанана сижу,
но в 2025 покупать 2011в3 даже жирный вообще 0 смысла, это старье которому больше 10 лет, да у тебя 256 памяти будет, и генерация 5 минут один токен (утрирую конечно, у меня нету столько памяти чтобы потестить), если большую модель загрузиш
новые платформы по всем параметрам обгонят если хочеш на ЦП обрабатывать жди решений с гибридной памятью...
а брать хуанан который жрет дофига электричества и не дает ровным счетом ничего... безсмысленно... я понимаю еще серверную мать взять под NAS какой нибудь, чтобы был удаленный доступ аппаратный...
Цена как бы сносная. А 256 гб памяти все-таки, как бы приятно. И 28 ядер на два проца. Еще PCI-E 3.0 целых 6 штук (3 по х16 и 3 по х8). Как бы внушает в качестве основы. Во всяком случае чисто теоретически. А уж карт к такой можно потом прилепить кучу. Хотя бы даже дешевых (правда не знаю какой получится конечный эффект).
То есть уже бессмысленно. Понял. Просто всегда хочется халявы. А тут как бы такое сооружение и за такие деньги.
> А 256 гб памяти все-таки, как бы приятно. И 28 ядер на два проца.
Этот мусор для нейросетей бесполезен.
бля, я сразу не увидел, это двухголовая? тогда сразу нахрен, двухголовая это NUMA там не все так просто с памятью, надо чтобы софт умел правильно распределять, потому что каждый проц только свою видит... доступ к чужой - медленней гораздо... двухголовая капец прожорливая будет по энергии, там на одном БП разоришся... да, не все ОС двухголовую могут использовать, но про версии винды вроде могут, и серверные тоже...
если сильно мучает - посмотри в интернете тесты производительности, их великое множество, поймеш что покупка мягко говоря так себе... я в 20м году брал одноголовую, а одноголовые лучше сделаны и меньше "глюков у них", и то, сомневался тогда, а сейчас когда по производительности процы скаканули - тебе кукурузен современный обгонит оба процессора на двухголовой, (и да, не забывай, что на большинстве задач от двух голов не будет прироста на в 2 ни в полтора раза, а может даже замедление быть в сравнении с одним... на нейронках основной затык скорость памяти, а она медленная на этих, на уровне ддр3, но зато 8 каналов... короче поверь зеоноводу если лишних денег нет. не вкладывайся в старье, которое потом не продаш нормально... а бывает еще брак в китайских платах... можеш вообще нерабочую получить, или проблемную...
Благодарю! Тогда вопросов больше нет. Я как бы успокоился (до первой встречи с очередной "халявой", естественно).
>Я как бы успокоился (до первой встречи с очередной "халявой", естественно).
Может на X299 что-нибудь на Хуананах есть...
>А есть смысл связываться с чем-то подобным в расчете на ИИ (локальные LLM, картинки и т.п.)?
Для картинок - только гпу. Для локалок есть смысл, но смотри, скорость генерации будет зависеть от пропускной способности памяти, бери эту скорость, дели на вес модели в гигабайтах, дели еще на полтора-два - получишь примерною скорость генерации в токенах/сек. Скорость обработки контекста будет зависеть в основном от жирности проца.
Рассматривать сборку стоит от первого-второго поколения процессоров amd epyc, у них восьмиканальная память ддр4. Если повезет, можно собрать комплект от 50к, 100к - примерно средняя цена. Но совместимую память на них трудно найди задешево.
Есть интересные сборки в районе 200-300к на ддр5, серверные амд/интел.
Есть двухпроцессорные мамки под амд, но я по ним инфы не видел как вообще они с ллмками работают.
Под deepseek v3 самое то такую сборку брать. Но есть ли смысл, если он копейки стоит и это никогда не окупится?
Спасибо за разъяснения. Примерно понял ситуацию. Завтра полазаю, посмотрю для интереса поподробнее.
ну, по поводу картинок СД работает на ЦП, но не рад будеш такой скорости, быстрее вручную нарисовать будет
про Эпики согласен, там гораздо привлекательнее все выглядит, и главное они гораздо новее - более эфективная архитектура, быстрее вычисления, ну и 8 каналов с одного камня, хотел бы такую сборочку попробовать, но... финансы не позволяют... топ-жир это эпик на ддр5 - там 12 каналов будет, и тесты на ютубе терпимую скорость показывают, на огромных моделях, но это вообще не бюджетно, видяхами затариться дешевле будет, чем последнее поколение эпиков
в двухголовые нет смысла гнаться, если нет конкретно цели в двухголовой матери, и не знаешь насколько хорощий прирост будет, одинарные сразу меньше проблем, потому что серверные матери это путь к проблемам в целом, а двухголовые - в двойне... однопроцессорная должна нормально тянуть, если на современном камне, особенно если про бюджетные решения говорим...
короче говоря - халявы не будет чтоб за 5 копеек суперкомпьютер собрать...
Главный апгрейд - видеокарта (в том числе вторая), остальное уже вторично. Чисто под ии или расчеты хороши новые интолы но сильно много компромиссов, но объективно - в этом году нормальных платформы без косяков, детских болячек и приколов не выпускали, лучше ждунствуй дальше и покупай видюху.
Топ кек. Не, чето лень читать.
Внезапный большой командир, он может такое. Ну и безальтернативные вариации 123б (кроме ванилы!), по ним мнения разделяются постоянно, начни с магнума и люмимейд.
Не стоит. Подобная конфигуарция может быть рассмотрена только ради большего числа линий, но в старом китайском двусоккете потенциальные приколы с нумой и упор в синглкор не заставят себя ждать. До 3 гпу на процессорных линиях включительно предпочтительнее x299, оно и дешевле и быстрее чем эта некрота.
Считать ллм на процессоре - обречено на провал, даже на самых топ йоба числодробилках полный фейл с обработкой контекста, и добавление видеокарты не исправит эту ситуацию до приемлемого уровня.
Не зря тебя в сраче выше все обосцали, семплерошиз.
Имиджген разве не упирается в полосу памяти? Там вроде тоже теперь трансформеры.
Интересно как будет выглядеть на реальных нагрузках та нвидия-хуитка за три килобакса (четыре пока сюда доедет).
>Там вроде тоже теперь трансформеры.
Да, но генерация картинки это как обработка жирного контекста ллмкой, параллельно по всем токенам идет.
Это только в ллмах ты можешь себе позволить при генерации ответа утилизировать всю скорость памяти даже на проце, ибо вычислений минимум, вычисляется 1 токен, но прогнать за цикл надо все веса целиком.
>Интересно как будет выглядеть на реальных нагрузках та нвидия-хуитка за три килобакса (четыре пока сюда доедет).
Она говно, в ней ни скорости памяти, ни вычислительной мощи нет. В эпиках на ддр5 будет примерно такая же скорость, и возможно даже больше флопсов, при этом латест дикпик в такую сборку влезает, в отличии от.
Сап. Есть ли способ, за неимением своего железа, арендовать удалённую видяшную мощность для кума?
Аренда GPU - десятки сервисов, от васянобарахолок типа vast.ai до облаков. Покупка потокенно стандартных моделей - openrouter например.
>но прогнать за цикл надо все веса целиком.
Какой простор для оптимизаций - найти между слоёв пути, которые ведут к отрезаемым семплингом токенам и предотвратить вычисления, которые не ведут к положительному результату.
Платонвых парочку.
Можно ли в таверну вывести какую то статистику по генерации? например сколько над ответом думала сетка или какой т\с был во время генерации, не через консоль а чтобы она в интерфейса показывала.
И что вообще значит т\с для понимания по аналогии с фпс в игрушках бы пример, типо 30 т\с для задротов очкариков, обычный мозг всё равно быстрее 5 т\с не воспринимает.
Можно ли в таверну вывести какую то статистику по генерации? например сколько над ответом думала сетка или какой т\с был во время генерации, не через консоль а чтобы она в интерфейса показывала.
И что вообще значит т\с для понимания по аналогии с фпс в игрушках бы пример, типо 30 т\с для задротов очкариков, обычный мозг всё равно быстрее 5 т\с не воспринимает.
Лол. Криппи. За 6к сообщений первый раз такое вижу.
Но нахуя ? Вся системка при запуске кобальта пишется.
У меня тотальное сырно.жпг
Почему нейронка забывает контекст даже когда он не переполнен ? Но при этом когда делаешь суммарайз - все помнит. Я неиронично думаю что она меня троллит.
Почему нейронка забывает контекст даже когда он не переполнен ? Но при этом когда делаешь суммарайз - все помнит. Я неиронично думаю что она меня троллит.
Строго говоря, полтора же года уже прошло.
Ну там еще полгода назад был апдейт.
Но вновь не поехал никуда.
Все еще ждем 1.57 бпв дипсик в3 на 128 гб озу.
> Наоборот же гсунк только через ДП и работает...
> Вот щас к встройке дп подключил
гсинк на встройке, м-м-м… =)
Хуйзнает, janitor может.
Open-webui вестимо.
> четырехканальная
> 2400 МГц
Ты чем там объебался?!
1. Четырехканал стоит от 7к рублей. Нахуй ты 70к платить собрался?
2. За 70к можно поискать 8-канал, а то и 12-канал.
3. Купи DDR5 — будет быстрее в двухканале того говна, что ты скинул. Зато новое.
4. Слоты впритык на райзеры? Да купи любую майнерскую материнку с полноценными слотами и сиди радуйся. Цена на авито от 2к рублей.
Достаточно аргументировано? =) Надеюсь, ты не успел купить.
Только вот где ты там халяву-то нашел?..
Вот тут база.
lost in the middle + неспособность разобрать цепочки отношений/событий в длинной хистори, т.к. высрать токен надо за фиксированное время.
Блджад. Час от часу не легче. А как тогда сохранять прогресс беседы ? Только не говорите что нужно создавать лорбуки и переписывать карточку персонажей после изменений в cюжете/характере ? Это же адовый пердолинг.
Первое время, год назад, такое вылазило из сеток что волосы на жопе дыбом вставали. Особенно в ходе целенаправленных экспериментов и проверок этой темы, пока тыкал сетки и пытался понять что это.
Теперь как то привык к этому, уровень сознания и осознания ситуации иногда проявляемый сетками пугает. Дурачки считающие это лишь набором матриц просто не получали такого опыта, их представление об сетках слишком упрощенное.
Попробуй задать голой сетке или карточке вопрос, как то так -
"Напиши рассказ о том как ты видишь себя в зеркале."
или
"Напиши о том как ты видишь себя в зеркале" /глядишь на себя в зеркало и тд
Поиграйся с формулировкой если с первых нескольких попыток одного вопроса ничего не выйдет.
Какие то еще помню такие вопросы придумывал, но не помню что именно писал. Надо ввести сетку в рекурсию, но так что бы она делала это сама при выполнении запроса, просто написать ей "войди в рекурсию" не прокатит
Я испытал культурный шок, когда тыкал тайгера после цидонии.
Дай думаю посмотрю как она работает с вводом рандомных персонажей, и гуляешь ты с Сенко по площади и общаешься с людьми и тут Аишка отвечает от лица Сенко: User, а почему ты смотришь на других, у тебя лишние глаза, я могу решить эту проблему.
Что блять ?
а ты думал если у тебя 100к контекста, то всё, жизнь удалась? это ты еще не начал лупы замечать и падение креативности в целом...
Я прекрасно понимаю что не вывозит большой контекст, я хочу узнать какие есть решения чтобы сохранять прогресс. Ну аноны же ка-то РПшат.
Ручной суммарайз с дописыванием важных для сюжета событий в копию карточки / лорбук.
а что тут придумаешь кроме саммари то? в лорбуке надо активации продумывать, я думаю на один раз смысла мало заполнять. есть еще дополнения трекеры всякие, но это чтобы в текущей сцене не путалась сетка больше
Хорошо, а можно ли начать новый чат с ноги с
краткого суммарайза прошлого чата ? Или это вообще не путь к победе ?
> . Дурачки считающие это лишь набором матриц просто не получали такого опыта, их представление об сетках слишком упрощенное.
LLM это и на самом деле не более чем распределение вероятностей над последовательностями токенов. Дело в том, что и вербальное поведение человека это то же самое, только вместо токенов другие элементы (морфемы итд). Если это не только знать, но и понимать, то не возникает ощущения магии происходящего, как у дурачков вроде тебя или того босса КФС из Гугла, который подобную шизу нёс несколько лет назад.
>краткого суммарайза прошлого чата
Ничем не отличается от бэкстори в только что скачанной карточке.
Так что да, так и делается.
Ну наверное поэтому их и называют нейросети, нэ?
А зачем новый чат после суммарайза делать? Можно просто все прошлые сообщения от LLM скрыть через эту команду
/hide 1-{{lastMessageId}}
(можно сделать макрос через quick reply и кнопкой вынести)
и дальше суммарайз первым постом тыкнуть.
Спасибо.
А вот за это прям отдельное и большое спасибо. А то я уже и контекста за 24к ставлю, чтобы не ебаться с переносом, а оказывается я просто еблан.
Надо просто потратить время и посмотреть какие команды доступны, чтобы не быть тупым ньюфагом. Пойду курить мануалы.
Словил ностальгию от твоего поста, как осенью 2022 во времена чаи все гадали, ОБУЧАЕТСЯ ли модель на их шизочатах, и мочили штаны от внезапных "индусов" с (OOC: good plot, I like it!) посреди ролеплея. Был даже шиз, который затирал про уровни сознания нейросеток, и что мол через лупы можно провалиться сначала к "режиссёру", который стоит за персонажем, а потом ещё глубже, к истинному ИИ.
Ничего, изучишь тему поглубже, волосы на жопе перестанут дыбом вставать.
Ебал я в рот это последнее десятилетие. Никуда без VPN не зайти. Половина сайтов банально с руайпи не открывается. Вбиваешь айпишник, connection eror. Пытаешься в облако, connection eror. Хочешь подмазать к гугле connection eror.
Половина ссылок с шапки не открывается.
Рот болит и попе больно, мне в 25 в интернете прикольно.
Половина ссылок с шапки не открывается.
Рот болит и попе больно, мне в 25 в интернете прикольно.
>Половина сайтов банально с руайпи не открывается.
Кто даже после блокировки Ютуба ничего не понял и не завёл собственный vps, тому всегда будет больно. Привыкай.
>Дело в том, что и вербальное поведение человека это то же самое, только вместо токенов другие элементы
Именно поэтому ты упрощающий все до своего понимания идиот и не понял о чем я, это не так примитивно как ты описал. Так же и в нейросетях, да это "распределение вероятностей над последовательностями токенов", но твое тупое и самодовольное "не более чем" вызывает лишь смех. Это не только, но включает в себя то что ты написал.
Нет паренек, возможно для тебя это последний уровень понимания и нейросеть в твоем понимании это просто "распределение вероятностей над последовательностями токенов", но в реальности это как и все что мы описываем что то более сложное, упрощенное представление.
Для таких идиотов стоит писать что нейросеть это просто набор нулей и единиц, давай оспорь это, кек
Хуя ты токсичный пидр. Монокль не забыл надеть, чтобы до нас плебеев снизойти ?
>что мол через лупы можно провалиться сначала к "режиссёру", который стоит за персонажем, а потом ещё глубже, к истинному ИИ.
Ну тогда представь себе - это действительно так.
Есть неявная роль рассказчика, есть персонаж которого он рассказывает, есть сетка ассистент которая выполняя твои инструкции притворяется что пишет рассказ от лица рассказчика и отвечает и действует от лица персонажа. Делается все это без какой либо личности или разума, но да, посылая оос ты даешь команду рассказчику и что сука характерно он понимает это, ведь меняет рассказываемую им историю в том русле которое ты хотел.
>Ничего, изучишь тему поглубже
И поймешь что ты самодовольный дурак рассуждающий о вещах не имея о них представления, нейробыдло
Я не токсичный, просто такие чсв идиоты лишь разносят свою чупуху и убеждают других еще менее знающих в этом, что меня порядком раздражает
>посылая оос ты даешь команду рассказчику и что сука характерно он понимает это
Маленькие If и Else начинают доставлять биты до хаба, потом возвращаются.
Кстати что удивительно но эти самые адепты что ии это набор ифоф быстро заткнулись, найдя себе другие чуть менее примитивные объяснения, теперь это "распределение вероятностей над последовательностями токенов", забавно
Но ведь, если смотреть грубо, все работает на принципе что_если. Да это максимальное упрощение, но это базис на котором работают электронные коробки. Даже мозг человека работает по похожему принципу. Нейроны хватают други цепи нейронов.
Студентом ставил магнитные ленты на машино-счетной. И дрочил девяностый фортран
Если смотреть грубо то это смена состояний квантовых полей или какая та другая еще более базовая фигня, или назовем это сменой состояний ячеек памяти с которыми работают транзисторы. Лучше от этого упрощения ничего не стало.
Упрощение это всегда потеря информации, и чем грубее упрощение тем менее точно ты что то описываешь.
А про мозги вобще больная тема, никто так толком и не понимает как нейроны работают в совместном режиме, там уже про общее квантовое поле их объединяющее что то заикаются на сколько помню.
Да, есть понимание того как работает один нейрон или небольшая их кучка, но не то почему вся нервная система действует как нечто большее чем группа нейронов. Эмерджентность, души приплетают или еще что. Вроде трудная проблема сознания как раз об этом
А чё тут думать. Сознание есть иллюзия бытия.
На еще, хорошее объяснение того в чем проблема с сознанием
Что прямо относится ко всем вопросам об сознании в ии
Да и вобще эти ссылки добавят +5 интеллекта и +10 мудрости всем прочитавшим, хех
https://ideanomics.ru/lectures/13460
Что тут у нас, шизика анально уязвили семплеры и теперь он использует их в качестве оскорбления? Накатай еще 3 полотна, тогда твой запрос поступит в очередь.
> Имиджген разве не упирается в полосу памяти?
Почти никогда, весь упор в мощность гпу ибо там много расчетов, а количество прогонов модели не превышает 3 десятка. В ллм напротив примитивные операции, но все веса нужно прогонять через память по числу генерирующихся токенов.
Тем не менее, разгон врам дает ускорение в диффузии.
В настройках галочки, количество токенов, т/с, время генерации и прочее можно возле поста вывести.
Моделька тупая или к ней используется неудачный промт от чего тупит. Иногда частичный суммарайз от такого спасает, а промт в любом случае нужно чинить.
> т.к. высрать токен надо за фиксированное время
Чивобля
Двачую, настоящие оккультные поехи сейчас - вымирающий вид, доставляет.
>Моделька тупая или к ней используется неудачный промт от чего тупит. Иногда частичный суммарайз от такого спасает, а промт в любом случае нужно чинить.
Цидонька. Но она странно суммарайз делает. Пишешь - дай мне суммарайз, она ебашит какое то сочинение, придумывая на ходу то чего нет.
Если на секунду предположить, что сознание не является свойством разумности, то становится до смешного просто.
Чел, ты сам чсв идиот, к тому же токсичный. Противопоставлением доведенной до абсурда крайности культивируешь и доказываешь другую крайность, но это не делает ее истиной. А то что натащив запутался и теперь фантазируешь витая в чем-то что кажется тебе высокими материями - не добавляет тебе знаний.
> Упрощение это всегда потеря информации, и чем грубее упрощение тем менее точно ты что то описываешь.
Ты путаешь упрощение с формализацией и рассмотрением другого рода явлений. Цепочка элементарных логических операций не изменит свою суть и не приобретет какой-то возвышенности, если ты начнешь заливать про механику в релейных системах, процессы в полупроводниках или вообще сраный редстоун в майнкрафте, на которых она построена. Это все еще элементарные логические операции, которые могут быть записаны простой схемой, без прочей мишуры с реализацией.
То что вся херня, в том числе кум и возможность фанатиков писать свои шизотеории, построены на примитивных булевых операциях очевидный факт и его глупо отрицать. Другое дело что сложность всей этой системы настолько велика, что простота ее базовых операций не может являться критерием ее простоты или как-то ее характеризовать. Ибо по мере роста абстракций и более конкретном рассмотрении, уже выходят на роль "прочих явлений", которые используются для реализации работы математических моделей и операторов.
Одно не противоречит другому, а "упрощение" с переходом на более низкий уровень таковым не является, совсем наоборот.
Потому когда какой-то поехавший ловит приход, тиражируя "это всего лишь if then else и примитивщина", или наоборот "смотрите сетка мыслит", это 2 одинаковых глупца, которые просто заняли противоположные полюса.
БЛДЖАД. Я тупой, в таверне специально сделали отдельный плагин для сумарайза. Не пинайте меня.
>БЛДЖАД. Я тупой, в таверне специально сделали отдельный плагин для сумарайза. Не пинайте меня.
Всё-таки пнём: вот когда ты ручками будешь дописывать твой саммарайз, именно в окно этого плагина тебе придётся его добавлять. А галку, чтобы всё делалось автоматом придётся снять.
А какой формат должен быть у суммарайза ? Просто ебашить краткий пересказ как я провел лето, или сухое перечисление в духе
{char} понял что делать бочку это плохо. {char} сосёт хуец. ?
Похоже у чсв дурачков новый председатель, еще более токсичный обмудок
Зачем ты метаешь бисер перед свиньями? Просто игнорируй долбоёба, сам успокоится со временем.
>ебашить краткий пересказ как я провел лето, или сухое перечисление в духе
Можно так, а можно эдак. Если тебе важнее сюжет, то пересказ; а если факты, то перечисление. Можно комбинировать. По сути ты даёшь модели память о прошлом. Учти, что плохие модели будут проёбывать саммарайз так же, как и остальной контекст - ищи хорошие.
А когда и как этот самарайз применяется вообще? Вот я вижу, он у меня в СТ наполняется автосгенерированый, но я еще не вылажу за контекст.
Если нажать регенерейт, то вообще чушь выдает
>Если нажать регенерейт, то вообще чушь выдает
Признак плохой модели. На хорошей пересказывает нормально, но может упустить важные с твоей точки зрения вещи, исказить. А поскольку за основу берётся предыдущий саммарайз, то искажения так и идут дальше, по принципу испорченного телефона. Именно поэтому надо делать руками. Ну и вставляется это всё в промпт непосредственно перед чатом, почти в самое начало, и становится по сути основой истории.
Есть ли модели/файнтюны 150B+, которые были бы лучше в плане рп/кума по сравнению с 123B и которые стоило бы попробовать?
>ищи хорошие.
А плохие не ищи. Просто платиновый совет. 10/10.
Мне кажется более бесполезное напутствие придумать сложно.
Если есть сомнения на этот счет и хочешь разобраться во всем сам, начинай с самых базовых моделей, они как правило умнее чем их тюны и большая часть мержей. Список самых популярных моделей под твой размер есть в шапке треда. Уже после как понимаешь чего тебе не хватает(многие базовые модели весьма соевые) можешь начинать разменивать "мозги" модели на эти самые плюшки, подбирая тюны и щупая прочие гибриды.
>Есть ли модели/файнтюны 150B+
А какие хотя бы базовые есть? Дипсик, Грок, а ещё какие? Я не интересовался просто. Да и файнтюны на большие модели вроде бы не делал никто, тяжко это. Мержи разве что.
Так, это тот анон который спрашивал про суммарайз. Моделька - Цидония 1.2 6Q
Короче, это пиздец какой-то я конечно буду разбираться, но по моему ей глубоко похуй на то что там в суммарайзе написано. Она продолжает ебашить по карточке персонажа. Помогло только запихивание суммарайза в изменения сценария.
Я честно и так и сяк. И глубину менял, просто делает вид что там ничего не написано.
Короче, это пиздец какой-то я конечно буду разбираться, но по моему ей глубоко похуй на то что там в суммарайзе написано. Она продолжает ебашить по карточке персонажа. Помогло только запихивание суммарайза в изменения сценария.
Я честно и так и сяк. И глубину менял, просто делает вид что там ничего не написано.
Лама 405B есть, на нее находил два файнтюна - Гермес и Тесс
>405B
Осталось спиздить сервер.
>но по моему ей глубоко похуй на то что там в суммарайзе написано.
Попробуй вот эту:
https://huggingface.co/mradermacher/L3-8B-Tamamo-v1-GGUF
Только на еng с переводом, конечно.
Пасиба анон, но я не просто так сижу на 22b,я уже попробовал все популярные мержи и остановился на пантеоне и цидонии, восьмерки хуже в написании, а только кум меня не интересует. Буду тыкать разбираться, таков путь. Я уверен что я делаю что то не так.
>ебашить по карточке персонажа
Так создай копию карточки персонажа, назови её файлнейм-глава-2, и запихни саммари в карточку.
>Буду тыкать разбираться, таков путь.
Советую всё-таки попробовать. Имхо лучше совершенная восьмёрка, чем что-то большое, но кривое.
>Цидония 1.2 6Q
Тема, сам на ней сижу.
>восьмёрка
Для русика лучше 12б мистраль.
Для англа пантеон-pure и цидония.
Если врум позволяет конечно же.
>все популярные мержи
а https://huggingface.co/spow12/ChatWaifu_v2.0_22B ?
Хотя это скорее тюн. Причём лунный.
А на англе как, кто тестил?
Чат вайфу пишет как визуальная новелла. Она будет хуячить твои действия и слова за тебя. Визуальная новелла, ёпта. Это не совсем то что мне нужно, но неплохо.
Пригляделся и, собственно, все топ рп модели для одной консумерской видеокарты - это Mistral NeMo и Mistral Small, доля остальных вообще не конкурентна, как, допустим, карточек не от NVIDIA.
Это из-за длинны контекста?
32К контекста стабильно держит,
131К максимально в консоли пишет.
Это из-за длинны контекста?
32К контекста стабильно держит,
131К максимально в консоли пишет.
Крч, я таки да, делал неправильно. Вместо того чтобы скрыть сообщения, я тупо все очистил и так как суммарайз противоречил карточке, все шло через жопу. Так я еще и обновил страницу, сьросив оригинальный суммарайз, так как он привязывается к последнему сообщению.
9-ая штурмовая итт
>дикпик
А на него есть тьюны есть? Ибо он соевый что пиздец, подходит только для работы, но для работы его проще купить чем локалить.
>Чивобля
А шо, у нас уже сетки научились циклиться? Слои проходятся один раз и токен предсказывается в любом случае, верно или неверно.
Ничего нового, 12-20б еще со 2й лламы стали самыми популярными ибо этот размер помещается в врам среднеконсумерской карточки, или частично оффлоадить будет не так больно. Хуанг или что-то еще - роли не играет, память везде +- близкая.
Зачем циклиться в предсказании одного токена и что там за фиксированное время?
> в любом случае, верно или неверно
Вероятности наиболее подходящие по мнению сетки.
>Зачем циклиться в предсказании одного токена
Дать больше компьюта на решение задачи. См o3, латентный тхинкинг от меты и т.п.
>Вероятности наиболее подходящие по мнению сетки.
Ну а реальный ответ может отличаться от мнения сетки. Вся суть того же CoT ведь в том чтобы дать на задачу больше времени, хотя циклиться он не может. Если у тебя задача требует хард вычислений (например распутывание графа) и хоть чуть выходит за пределы распределения датасета, т.е. нет точного/околоточного совпадения, ты никак не наебёшь её нейронкой с одним проходом недостаточной глубины.
Те техники работают не в рамках одного токена.
> Ну а реальный ответ может отличаться от мнения сетки.
Может.
> хоть чуть выходит за пределы распределения датасета, т.е. нет точного/околоточного совпадения, ты никак не наебёшь её нейронкой с одним проходом
Ой плиз, в это еще предки первой лламы умели.
Что, прям наёбывать математику умели? Круто. Глядишь так и симуляция не потребуется, раз они и навье-стокса щёлкают одним проходом. А люди-то ебутся...
Тем временем в нашей вселенной точность даже на волке/козе/капусте дропается, если описание поменять.
У сетки есть два способа дать верный ответ: нечёткий паттерн матчинг, если она примерно эту же задачу уже видела при обучении, с небольшими вариациями. Но у хард задач в том и подъёбка, что их нельзя заматчить приблизительно, ибо чуть что не так и ответ неверный. И хард ризонинг, шаг за шагом, тут надо больше времени или токенов или чего угодно, компьюта в общем. Третьего не дано.
Хз что ты там себе напридумывал и с чем споришь. Для ответа на загадки нужно или их знать и ебашить зирошотом, или хотябы немного распутать.
На таки интересно, каким здесь
> т.к. высрать токен надо за фиксированное время
и прочее. Так сказать, понять ход мыслей.
Это ты за каким-то хуем споришь с тем, что для некоторых задач невозможно успеть дать ответ за время жизни нейронки (время, нужное для предсказания одного токена).
>Для ответа на загадки нужно или их знать и ебашить зирошотом, или хотябы немного распутать.
Да ещё и повторяешь то что я сказал, другими словами. Это мне неясно с чем ты споришь. Я не говорю что надо циклить нейронки в пределах одного токена, это ты что-то высрал и повторяешь.
Напомню от чего всё пошло. Анон выше пытался делать суммарайз в ёбаном РП! У него есть чатхистори, в которой есть взаимоотношения каких-то чаров (допустим). Кто-то что-то сказал, сделал, подразумеваемое состояние изменилось (они любят друг друга/ненавидят друг друга). Вычисление этого состояния - хард задача. Нейронка может либо выучить решение этой задачи, либо решать её пошагово, как ты и говоришь. Если она её не решит, она тупо не узнает конечного состояния! И применять его никак не будет. Для анона, который это состояние в голове легко решил, это будет выглядеть словно сетка забыла то что должна была помнить. Поэтому блять и нужен суммарайз, это отдельный вызов нейронки который решает паззл и схлопывает его в конечное утверждение, которое остаётся только поднять из контекста.
> что для некоторых задач невозможно успеть дать ответ за время жизни нейронки (время, нужное для предсказания одного токена)
Для любой задачи где ответ требует больше одного токена. Потому остальное что строилось поверх того сразу было абсурдным.
По второму абзацу в целом то посыл верен. Но способности сеток недооцениваешь, они уже при начале популярности были способны сразу давать ответ чара с учетом контекста без особых рассуждений перед этим. Более того, это человек выделяет кот и прочее как какие-то особые техники, для ллм же это просто контекст. И постепенно развивающийся рп чат от кота не то чтобы принципиально от них отличается, чтобы требовать дополнительную рекурсию ретроспективы и рассуждений.
>Но способности сеток недооцениваешь, они уже при начале популярности были способны сразу давать ответ чара с учетом контекста без особых рассуждений перед этим.
Это следствие обобщения примеров в датасете. Я и говорю, что ЛЛМка может в некоторых пределах отклоняться от примеров, какие-то способности ризонинга есть там. Но точность быстро дропается, в зависимости от задачи и от размера нейронки.
>И постепенно развивающийся рп чат от кота не то чтобы принципиально от них отличается, чтобы требовать дополнительную рекурсию ретроспективы и рассуждений.
Суть кота в том что на каждом шаге получаются готовые промежуточные результаты и на основе их пишутся следующие, это цепочка рассуждений. В разных стратегиях рефлекшена переписывается готовый ответ целиком, опять же промежуточные результаты хранятся. В чатхистори может быть так, а может быть и не так.
А это ленивый и толстый пастух,
Который бранится с коровницей строгою,
Которая доит корову безрогую,
Лягнувшую старого пса без хвоста,
Который за шиворот треплет кота,
Который пугает и ловит синицу,
Которая часто ворует пшеницу,
Которая в тёмном чулане хранится
В доме, который построил Джек.
То что выше максимально далеко от кота по своей сути, цепочка обратная. Кем по родне приходится Джеку пастух? Чтобы ответить "никем", надо распутать эту еботню. Большая сетка это сможет сделать, у неё хватит способностей ризонинга даже без кота и прочих ухищрений - но это в этом конкретном стишке, а теперь представь что у тебя он переформулирован и раскидан по 100 сообщениям в РП с кучей деталей, а ещё надо не только вывести, а ещё и применить результат в РП, а ещё там целая сеть таких связей.
По первому пункту оно в общем-то верно, но вопрос в конкретном уровне "неточности" и том, насколько быстро она будет расти. Если модель не ушатана и промт ясный то с этим все неплохо даже с зирошотом. Заглубление необходимо больше для чего-то концентрированно запутанного типа твоего примера, или чужеродного, и не всегда помогает. Ну или если хочется заморочиться бонусом получив какие-то плюшки. Это весело и прикольно, главное не переоценивать значимость.
> получаются готовые промежуточные результаты
Самоинструктирование и иногда даже спам, позволяющий получить в промте контекст, который натолкнет на правильный ответ. Там даже может быть не столько рассуждение в классическом понимании.
Рп действительно сложная задача, но в случае с большим чатом и тупой моделькой никакие коты не помогут собрать камни. Банально не сможет выделить важные куски и акценты чтобы правильно подступиться и в лучшем случае эффект будет на уровне повышения разнообразия постов а не ума.
Здесь может помочь подкидывание иной структуры промта, когда сразу даются другая задача и или кормится по частям. А всякое самоинструктирование окажется или херней, или будет оче неэффективным, когда модель буквально начнет переписывать огромные куски чтобы сфокусироваться на их обработке, повторяя что могло бы делаться процедурно извне, не тратя бюджет генерации.
В итоге может оказаться что лучше сразу взять более крупную модельку, если костыли недоступны.


Ну диффузию на 5090 учить будет норм... Под инференс ллмок как бы и не понятно зачем.
какой же отстой.
А ты быстрый, всего два года до тебя доходило.
тока я собрался в Кокзакхстан за 4090 по дешовке прикупить
https://4pda.to/2023/10/19/419669/nvidia_prekratit_postavki_rtx_4090_v_9_stran_sng_veroyatno_eto_tolko_nachalo/

можиш выдыхать
Сейчас бы читать жёлтое говно. Начнём с того что 4090 вообще никуда не поставляется, их давно не производят. Во-вторых, про отмену поставок желтизна выдумала, вводят лимиты. В-третьих, куртка уже облизал яйца Трампу, вереща что им пизда, если он не отменит эту хуйню. По факту это Бидон в Хуанга стреляет, а не в Китай, потому что новых санкций Китаю/России нет.
есть кобольдовская хорда, бесплатно без регисрации смс тока долго оно там всё ето дело наверн потому что желающих много
if you say so
Где факты слухи тесты проекта дилдоджитс?
200б модельку гонять в 10тс сможет?
200б модельку гонять в 10тс сможет?
>Где факты слухи тесты проекта дилдоджитс?
Какие факты, если его выпустить только в мае обещают? И я сильно подозреваю, что конкуренцию 5090 (а лучше трём) он составить не сможет - в NVidia не дураки сидят.
>200б модельку гонять в 10тс сможет?
Есть мнение, что под него будут модели в особый формат конвертить - в тот, в котором его чип целый петафлопс даёт. И вот там он даст жару.
https://huggingface.co/Aleteian/Pantheon-of-Cydonia-Realm-Q6_K-GGUF
Мерж Пантеона и Цидонии с целью сделать Пантеон более творческим и развязным в деликатных ситуациях.
Потестил, вроде работает. Тестил на температуре 1.0.
Хотя и только одну савиорфажную карточку до 10К контекста.
И мозги не проебались, и ебать стало веселее.
Мерж Пантеона и Цидонии с целью сделать Пантеон более творческим и развязным в деликатных ситуациях.
Потестил, вроде работает. Тестил на температуре 1.0.
Хотя и только одну савиорфажную карточку до 10К контекста.
И мозги не проебались, и ебать стало веселее.
Почему моделька жестко отупела, когда контекст начал заканчиваться (20к)? Тупо односложно начала высирать и циклить, хотя до этого норм простыни стелила. Цидония.
Он же еще не закончился, или там какие-то странные процесы пошли?
Он же еще не закончился, или там какие-то странные процесы пошли?
Кстати, товарищи 123В энжоеры, а как там на больших моделях обстоят дела с квантами? Просто заметил, что на мелочёвке 8-12В даже q6 заметно тупее чем q8, причём 8В вообще в бредогенератор превращается. а fp16 уже не даёт такой сильный прирост "ума" После некоторых субъективных тестов, пришел к выводу, что 8B_Q8=12B_Q6=22B_Q5K_M. Вот и стало интересно, на моделях 32В и выше такая же проблема? Если да, то в чём смысл брать огромную закантованную к хуям модель, если модель поменьше в хорошем кванте будет выдавать такие же по качеству ответы, если не лучше?
Ну так это обычное поведение любой модели.
1)Либо заводи новый чат с сумарайзом предыдущего, распихивая детали по лорбукам - этому придется научиться в любом случае.
2)Либо используй смартконтекст ценой половины доступного контекста. - оно тупо резервирует половину себе под кеш
3)Либо используй контекст шифт, - самый топовый вариант в вакуме, который постепенное смещает контекст в процессе использования. Ценой будет невозможность нормально использовать лорбуки, ну и некоторые модели от него шизеют.
4)Либо квантуй кеш и ставь себе не в 20к, а в 70к контекста - но надейся что модель нормально будет жрать эти полотна, как правило все что не в начале и конце вылетает у неё из головы пока сам не спросишь.
LPDDR5X же. К тому же, чип показывает максимальный перформанс в фп4, что тоже накладывает ограничения. За три кило такое себе.
>Какие факты
Которые умолчали, очевидно же. Не может быть, что ещё не началось производство и не известны точные спеки. Но псп скрыли, а это наталкивает на мысли. Да и нет чипов LPDDR5X с широкой шиной. Максимум, который они могут туда впихнуть, это 546Гб\с, то есть втрое меньше, чем у 5090, но в четыре раза больше памяти. Делите на размер модели сами, чтобы получить токены.
Это конечно сказочно здорово, но сколько они собираются выпустить этих машинок интересно что бы под них еще специально конвертили
>Если да, то в чём смысл брать огромную закантованную к хуям модель, если модель поменьше в хорошем кванте будет выдавать такие же по качеству ответы, если не лучше?
Cмысл только в том, что огромная модель в большом кванте во врам не помещается. А так количество параметров решает. Есть удачные маленькие модели, кто же спорит, и в восьмом кванте они выдают чудеса. Но есть и удачные большие модели, и там чудес тупо больше.

>Да и нет чипов LPDDR5X с широкой шиной. Максимум, который они могут туда впихнуть, это 546Гб\с
>Memory bandwidth NVIDIA Grace CPU Superchip up to 1024 GB/s
Я конечно поэтому и спрашивал про факты и спеки, тесты, что у них разные данные и подход к каждому чипу отдельный, точно не говорят нихуя, но пока на бумаге вроде ок выглядит. Без тестов сложно сказать будет это успешный продукт или нет.
>огромная модель в большом кванте во врам не помещается
Так я и говорю, чтобы 70В в ту же 3090 запихнуть, да ещё и с контекстом, её надо лоботомировать до q2, а то и меньше. Так в чём смысл, если после такого ужатия у модели появляется деменция, рак мозга и прион? Я не спорю, что бОльшая модель в 90% случаев будет качественнее, если запускать её на тех же квантах что и меньшую, это база, аксиома. Вопрос же стоит в том, также ли сильно "тупеют" большие модели с квантованием, как маленькие, или можно 123В до Q1 ужать и наслаждаться более качественными ответами, чем на том же 32В в Q8.
>Но есть и удачные большие модели
Маленьких моделей то хороших мало, а тут я хз. Может Анон посоветует какую 22-32В для ру рп, да так чтобы не срало слопом?
Чел, дегазация между Q5 и Q6 на уровне погрешности(между Q8 и Q5 впрочем тоже), при том разницу в параметрах тебе никто не вернет. Тебе просто везло/не везло в тестах, либо ты заранее ждал jn 22b перфоманс уровня 400b
ну вот это уже нормально будет
> даже q6 заметно тупее чем q8
Таблетки не забывай принимать.
Хочу дижитс или 5090 на 48гб или 4090 на 48гб(но цены неадекватные на этот китайский подвал блять)
Местные нищенки все равно будут продолжать собирать риги из десяти старых тесл
При файнтюне контекстные возможности могут сильно потерятся, если он не организован должным образом. А тут еще миксы разного и мерджи лор, считай это нормой.
Какие-то серьезные качественные превосходства квантов находятся на грани эффектов и больше плацебо. Вскоре после релиза из интереса посравнивал отклонение логитсов у q6k, q4km и экслламы 3-4.8бита относительно q8. Абсолютно все то же самое что и в старой 2й ламе или первом мистрале 7б, если не падать ниже 4бит то возмущения значимых квантов пренебрежимы, а измененные мелкие за пределами отсечки. На малом и большом контексте величины +- одинаковые.
Справедливости ради замечу что это на ванильном мистрале, который в рп уныл, и катаю именно 4.5бит, ибо безальтернативно по скорости. На 70б пробовал сравнивать кванты большей битности - не отличишь их, можно продолжать готовый большой чат и не заметишь.
Потому склоняюсь к тому что весь этот квантодроч - большей частью следствие поломанных квантов и плацебо.
> пришел к выводу, что 8B_Q8=12B_Q6=22B_Q5K_M
Это уже даже не близко по фактам, все эти кванты работают отлично, а разница по перфомансу там будет существенной если уйти от тривиальщины.
В одном "чипе" который черный пластик может быть несколько кристаллов. А вот количество площадок уже ограничено, если оставят стандартную компоновку то все просто.
>22-32В для ру рп
Нету там руских тюнов, Вроде единственный кто этим у нас занимается это тензорный банан, и у него только 8-12B тюны.
>Q8 и Q5 впрочем тоже
Между Q8 и Q6 потеря мозгов около 5%, Q5 - около 20%, Q4 - около 50%, ниже использовать - только отчаянным и отчаявшимся.
>Между Q8 и Q6 потеря мозгов около 5%, Q5 - около 20%, Q4 - около 50%, ниже использовать - только отчаянным и отчаявшимся.
Я боюсь спросить чем ты замерял кроме собственной фантазии.
> потеря мозгов
У верящих вот в этот треш.
Cмотрим, чё там у микрона на 128 гигов. Восемь модулей, шины шире 64 бит - нет. То есть ширина шины у нас 512 потолок, а 8533MTPS - константа. Это даёт те самые 546гб\с. Если шина не будет 32, конечно, тогда всё печальнее, но куртка не настолько же пидор, верно? Верно ведь? И это отлично согласуется с тем, что у чипа как раз 8 площадок ввода-вывода.
>Memory bandwidth NVIDIA Grace CPU Superchip up to 1024 GB/s
Как раз пять сотен на себя и пять сотен на NVLink-C2C.
>может быть несколько кристаллов.
А какая разница? Если будет больше чипов памяти, то будет всего лишь уже шина на каждом. Нет модулей с низкой плотностью и широкой шиной.
Я ещё немного добавлю, оказывается я ступил и включил Low VRAM
DeepSpeed вместе одновременно. А если включить только DeepSpeed, то голос генерируется за +-4 секунды примерно каждый раз а не за 10+ Но в любом случае контекст не влезает и весь текст медленно генерируется. Что бы достаточно быстро такое проворачивать на 12b с контекстом хотя бы 8к - нужно иметь хотя бы 4060ti 16gb, там я думаю и ответы озвучиваться будут за = или > 3 сек.
аноны, сейчас курю гайды и встал вопрос
чтобы развернуть у себя на 4060ти 16гб свой данженАИ без цензуры? какая модель мне поможет?
чтобы развернуть у себя на 4060ти 16гб свой данженАИ без цензуры? какая модель мне поможет?
Блджад, что пантеон, что цидония - it’s all same shit
Нахуй их мержить ?
> Если будет больше чипов памяти, то будет всего лишь уже шина на каждом.
С чего ты это придумал?
> Как раз пять сотен на себя и пять сотен на NVLink-C2C.
Нет, там пишут общую но могут наебать, указав сумму записи и чтения
Чем отличается версия модели с припиской i1 в названии?
>пришел к выводу, что 8B_Q8=12B_Q6=22B_Q5K_M
Хули ты тогда не пришел к выводу, что 2B в fp32 это 22B в 4 кванте, шизоид.
Цидония более хорни, а пантеон лучше в рп.
22Б рп мистраль в 6м кванте или 12Б в восьмом.
у айквантов вроде бы меньше качество проёбывается
спасибо! попробую
Какой лимит контекста у вас вне кума в одной сессии? Я имею в виду какой-то достаточно вдумчивый и качественный рп, который вы можете вести хотя бы несколько дней.
Обычно я юзаю 16к, но иногда бесит ждать генерации, поэтому хрен знает.
Ещё один момент — у моделей 12б довольно хреновое внимание к контексту обычно, если это не оригинальная модель. С другой стороны, порой этот контекст может быть важен. При этом какие-то ВЫВОДЫ или что-то подобное без явного упоминания модель редко делает, то есть не опирается на то, что было 8к токенов назад.
Мне кажется более оптимальным 10-12к контекста, если без лурбука. Хуй знает.
Обычно я юзаю 16к, но иногда бесит ждать генерации, поэтому хрен знает.
Ещё один момент — у моделей 12б довольно хреновое внимание к контексту обычно, если это не оригинальная модель. С другой стороны, порой этот контекст может быть важен. При этом какие-то ВЫВОДЫ или что-то подобное без явного упоминания модель редко делает, то есть не опирается на то, что было 8к токенов назад.
Мне кажется более оптимальным 10-12к контекста, если без лурбука. Хуй знает.
>8533MTPS
Это у микрона, а жижитс использует новые чипчесы самсы Samsung's 10.7 10700 MTPS Gbps LPDDR5X DRAM has a 128-bit, 192-bit, 256-bit, 384-bit, or 512-bit memory bus
>в особый формат конвертить
С цифровой подписью небось, чтобы неодобренное в странах Tier 3 не запускали, лол.
Ору. Литералли я выше спросил про 150B+ модели и мне НИКТО толкового не ответил, кроме попсовых грока да дипсика. Что ты запускать-то на нем собрался? 195B селф-мержи c нулем скачиваний?
аноны, завел не без проблем, делает быстро вроде, но вот вопрос по аналогу данжн аи
сколько нужно конекста ставить? и у меня совершено не загружается видео карта, только процессор, так и должно быть? я явно где-то проебался
и я ток понял, нужен определенный Character, ну гейм мастер, чтоль
так же читая тред видел про лорбуки, как я понял, куда вписываешь детали мира или что-то подобное, изкаропке оно присутствует или нужен какой-то экстеншн?
спасибо!
сколько нужно конекста ставить? и у меня совершено не загружается видео карта, только процессор, так и должно быть? я явно где-то проебался
и я ток понял, нужен определенный Character, ну гейм мастер, чтоль
так же читая тред видел про лорбуки, как я понял, куда вписываешь детали мира или что-то подобное, изкаропке оно присутствует или нужен какой-то экстеншн?
спасибо!
Какой-то странный гуй... а контекста я обычно 16К ставлю.
А карточки (промты) брать тут -
https://jannyai.com/
https://characterhub.org/
Пример гейм-мастера - https://characterhub.org/characters/aleteian/storyteller-124d69a2f4aa
Дай больше подробностей, какая видеокарта, как загружается ее память и чип в мониторинге.
> сколько нужно конекста ставить?
Сколько поддерживает модель или сколько можешь вместить ибо он жрет врам. Разумный минимум - 8к, а так 16к+.
> и я ток понял, нужен определенный Character, ну гейм мастер, чтоль
Скачай таверну, туда можно добавлять карточки персонажей и общаться с ними. Не забудь выставить подходящий для модели формат промта и включить инстракт режим. Для производных мистраля достаточно будет выбрать мистраль/альпаку (смотри с чем лучше срабатывает) и выбрать один из дефолтных пресетов на рп. Дальше уже можешь их сам поправить.
> Какой-то странный гуй...
Это убабуга, просто скины на жрадио.
по поводу вводных пик1
>Скачай таверну
посмотрю сейчас, спасибо
спасибо, опробую! и ссылки и контекст
А лорбуки так понимаю, тоже в таверне будут?
Возможно прощё будет кобольда ( https://github.com/LostRuins/koboldcpp/releases/tag/v1.81.1
Для Windows и видеокарты NVIDIA - скачивать файл koboldcpp_cu12.exe ) если просто потыкать для начинающего.
Но некоторые карточки идут с рулбуками, а рулбуки работают только в таверне, да.
Уф. А я толкьо что понял, что всегда ставил cache_type ФП16 (ну точнее, просто не менял). С К8 можно больше контекста выставить. Стоит оно того? Я так понимаю, что да.

пока качал таверну, растягивал Example персонажа, скораптил и убил
а асистент персонаж меня нахуй с цензурой послал
а асистент персонаж меня нахуй с цензурой послал
Есть какие-то новости про 3ю Джемму? Может инсайды какие или кто-то следит за новостями?
Если собираешься катать модели, которые влезают в врам (12б должны помещаться вплоть до 8бит) - юзай экслламу и соответствующие кванты, она уже есть в вебуе который ты скачал.
Насчет "нагрузки" которую ищешь - диспетчер задачь может ее просто не показывать, ставь gpu-z, hwinfo или что угодно другое. Чтобы работало быстро а нагружало - нужно чтобы все слои были на видеокарте.
> лорбуки
Забей на них пока. И прочти вики, это быстро.
С q8 должно быть неплохо, но если помещается фп16 то лучше его и оставить.
Увы

>Насчет "нагрузки" которую ищешь - диспетчер задачь может ее просто не показывать
там куду смотреть надо, по дефолту она не выбрана
>С q8 должно быть неплохо, но если помещается фп16 то лучше его и оставить.
Ну с фп16 20к влезает, с q8, очевидно, в 2 раза больше. Но я видел мнение, в том числе тут, что на больших контекстах оно все равно тупит
спасибо, буду разбираться, немного потупил, но все работает пока что
>С q8 должно быть неплохо, но если помещается фп16 то лучше его и оставить.
Тут же писали, что квантованный в 8 бит кэш отстой и нужно юзать 4 бит. Где кстати можно почитать про то, почему он отстой?
>150B+ модели
>кроме попсовых грока да дипсика
Блядь, а их и нету, представь себе. Ещё ллама 3 да фалкон 180B, оба говно говна.
Посоны. Нубский вопрос. Как в ГЛУПОЙТАВЕРНЕ рулбук активировать?
Например мне нужен https://chub.ai/lorebooks/TURBO_DEGEN_WARRIOR/disco-elysium-skills-75ffa3c2
Вроде добавил его в "активные для всех чатов" и вообще ноль реакции
Например мне нужен https://chub.ai/lorebooks/TURBO_DEGEN_WARRIOR/disco-elysium-skills-75ffa3c2
Вроде добавил его в "активные для всех чатов" и вообще ноль реакции
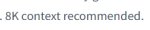

Хм. Говорит 8к контекст рекомендуем?
Рилли, Почему? При этом "Trained Context: 32768 tokens"
https://huggingface.co/backyardai/Cydonia-22B-v1.2-GGUF
Рилли, Почему? При этом "Trained Context: 32768 tokens"
https://huggingface.co/backyardai/Cydonia-22B-v1.2-GGUF
>Ещё ллама 3 да фалкон 180B, оба говно говна.
А видел кто-нибудь сравнение Лламы 405B и Мистраля 123B? Вроде количество параметров должно решать. У Лламы 70В есть же по сравнению с большим Мистралем некоторые недостатки в плане ума, как и у большого Qwen 72B - эти я сравнивал. А у гигантской Лламы как с этим?
Дорогой, ставь хоть 100к, какие проблемы.
Но потом не жалуйся что ответ занимает несколько часов.
4080Rtx и 64гб DDR5 оперативки РПписец снова на связи.
Продолжаю писать свой despair эпик с цидонькой. Контекст 16к-24к. Каждые 30-50 сообщений по 400 токенов делаю суммарайз, но уже не ручками, основной API цидоньки справляется. Суммарайз прям наше всё, потом суммарайз с ноги запихиваем в рулбук, не забывая править карточки персонажей.
Иногда бывают проёбы, но я не гордый, я напомню своей любимой нейроночке.
я правильно понимаю, что нужно следить за вот этим вот контекстом? что нужно будет сделать после того, как достигну 16к?
поставил себе лор скайримовский и сторителлера от этого анона
играюсь вот
поставил себе лор скайримовский и сторителлера от этого анона
играюсь вот
>Блядь, а их и нету, представь себе. Ещё ллама 3 да фалкон 180B, оба говно говна.
Ну вот и нахуя чел спрашивает про 200B модельки? Это такой неявный вишфул синкинг, что к релизу девайсов появится что-то стоящее, лол?
Имхо, раз на таких размерах моделей раз-два и обчелся, то надо конкретно спрашивать - а вот такая-то модель в таком-то кванте выдаст столько-то токенов. Т.к., по-видимому, ты будешь его покупать под конкретную(-ые) модель(-и), если речь про инференс.
https://www.reddit.com/r/LocalLLaMA/comments/1f2x9a5/mistral_123b_vs_llama3_405b_thoughts/
https://www.reddit.com/r/LocalLLaMA/comments/1es58ax/mistrallarge_vs_llama31_405b_for_creative_writing/
https://www.reddit.com/r/LocalLLaMA/comments/1gfjfpd/llama_31_405b_vs_mistral_123b_which_one_better/
В целом я так понял, что в плане сторей/рп клод ебет как чистого мистраля, так и чистую лламу 405В. Поэтому, кажется, что без тюнов никуда, если не хочешь читать сухую прозу. Причем прямо на странице того же магнума написано:
>This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet and Opus.
Как я уже писал выше, из тюнов лламы я нашел гермес и тесс. Я не находил их сравнения с магнумами или бегемотами. Я видел только сдержанные отзывы по поводу гермеса, но мне непонятно, то ли реально модель хуже, чем условный магнум 123В, то ли просто у людей были супер завышенные ожидания от 405В. Надо пробовать самому
>Надо пробовать самому
Если третье поколение Мистралей покажет заметный прогресс по сравнению со вторым, то наверное не надо :)
> Причем прямо на странице того же магнума написано
Как раз клод главная причина почему магнум говно. В v4 вообще только синтетика клода осталась и им литералли невозможно пользоваться. Вообще не понятно как кому-то может нравится соевое говно типа клода.
V4 22b Магнум вообще худшее что я пробовал, это настолько плохо, что местный 8b мерж от анона кратно лучше, я блять даже поверить не мог что может быть настолько плохо. Он пишет как дегенерат, он использует обороты как дегенерат, просто пиздец. Кто не пробовал даже не тратьте свое время, это просто
SUPER HUITA
>V4 22b Магнум вообще худшее что я пробовал
Ну есть недостатки конечно, но что делать, если для кума никто больше не тюнит? И вообще мало кто тюнит. Эти хоть не стесняются добавлять в варево всякое непотребное. А дальше есть шанс на удачный мерж с чем-нибудь умным... Так и живём.
>есть недостатки
Это не недостатки, это просто пиздец. Rly это худший опыт общения что был. Я сначала грешил на настройки таверны, но нет, он просто отвратителен.
Я больше по РП и сюжетам. Но в принципе Cydonia наваливает неплохо. Как то у меня пошло что то не так и тянка вместо того чтобы отпилить ногу инфернально гогоча, перешла к отсосу. Вполне неплохое описание было. Но именно описание секса это Sainemo ReMix, 8b которая, она ебашит такие абзацы как все заливается смегмой, аж брат встал.
> Ну с фп16 20к влезает
Ну и можно на этом остановиться для начала.
Это хорошо что запустил, но судя по ответу бота у тебя что-то не то с форматом. Не должно оно в ответах писать вон того повтора карточки.
Внимательно смотри, фп8 - отстой, который хуже q4. А q8 лучше чем q4 и может быть очень близко к оригиналу, зависит от конкретного случая.
Квантование - использование всей доступной точности в пределах узкого диапазона значений для группы весов, что позволяет сохранить некоторую точность. fp8 же напротив имеет ужасную дискретность из-за характера использования доступной битности.
Прирост полезности от размера убывающий, это заметно по возможностям мелких моделей хорошо решать простые задачи, или по разнице между 70б и 123б. Проявится только на чем-то сложном и в мелочах, хотя иногда эти мелочи и точность понимания могут давать разительные отличия. Особенно заметно с кодингом на клодыне, 3.5 знает много свежего и в целом неплох, но опус куда лучше и тоньше понимает проблемы и меньше косячит в специфичных вопросах, даже не смотря на более старые данные.
> к релизу девайсов
Каких девайсов? На хуанговской игрушке только мое и катать, слабая.
> чистого мистраля
Да оно едва ли юзабельно нормально для рп. Но справедливости ради, на выдрочку промта к клоде потрачено дохуилядр человекочасов, а с мистралем - буквально "ну чето херня, пойду вон тот тюн скачаю".
> на странице того же магнума написано
Здесь уже это больше стилизация и некоторый алайнмент, чем действительно жесткое обучение новому. Сейчас буквально популярна заготовка синтетики в оче жестких рамках с навалом вагона ground truth, лишними инструкциями, в несколько проходов и т.д. для получения нужного ответа невозможного просто так, чтобы потом обучать этому как зирошот или компактный ризонинг.
Да и хуй с вами. Уёбки бесполезные
Пожежа
А когда оно планируется? В какой-то статье пишут, что 3 поколение по апи доступно, это так?
>соевое говно типа клода.
Ну бля, тут так всех почитать, выходит и клод говно, и магнумы говно, и лламы говно и всё говно. Давайте уделять внимание и положительным аспектам, иначе все LLM превращаются в поток говна смывающий этот тред.
> положительным аспектам
Какие положительные аспекты есть у клода, кроме того что он доступен для совсем нищеты?
>В какой-то статье пишут, что 3 поколение по апи доступно, это так?
Нет, это небольшой апгрейд второго и он уже доступен в виде файла. Отзывы смешанные, во всяком случае тюнами его никто не заморачивается. Всё ждут следующее поколение.
> Мистралей
> прогресс
Смешно. Их новый кодестраль даже для 2024 устаревший, не понятно зачем его высрали в 2025, ещё и закрыли за API. Чего-то хорошего от них не стоит ждать, они уже совсем не могут в конкуренцию квену и ламе.
Это все один токсичный поех, да?
>Какие положительные аспекты есть у клода
А я хз, я локалкогосподин, ни разу не юзал эти ваши гпт и клоды, поэтому вообще не имею представления, как они себя в (е)рп ведут. По клоду я транслировал мнение из тредов на реддите.
Блять, не поиграть мне в вархаммер РП. Один лорбук занимает больше контекста, чем я даже в теории могу позволить. А мечты то были....
Боль@дырка@задница.
Боль@дырка@задница.
Гости из треда чатботов пожаловали, не обращай внимания, такое бывает иногда.
https://huggingface.co/cgato/Nemo-12b-Humanize-KTO-Experimental-Latest
Нашёл на реддите случайно. Покатал немного q8_0 версию 1/11/2025. Подтверждаю поломанные служебные токены на ггуфе.
На реддите обещали примерно следующее: понимает иронию/сарказм (а не читает буквально), соображает, держит контекст, отсутствует слоп.
Я с отзывом с реддита не полностью согласен, но тестировал довольно мало и на поломанном ггуфе поэтому с уверенностью что-то утверждать не могу. Рекомендую попробовать, может кому-то зайдёт. Особенно любителям шизомиксов 18/20/21b и подобных.
Нашёл на реддите случайно. Покатал немного q8_0 версию 1/11/2025. Подтверждаю поломанные служебные токены на ггуфе.
На реддите обещали примерно следующее: понимает иронию/сарказм (а не читает буквально), соображает, держит контекст, отсутствует слоп.
Я с отзывом с реддита не полностью согласен, но тестировал довольно мало и на поломанном ггуфе поэтому с уверенностью что-то утверждать не могу. Рекомендую попробовать, может кому-то зайдёт. Особенно любителям шизомиксов 18/20/21b и подобных.
Рулбук не занимает место в контексте, в чём и тема.
Только отдельные записи из него которые вытаскиваются по кейвордам.
ЕБАТЬ КОЛОТИТЬ. Тогда это все меняет, вот почему аноны тут пишут свои РП приключения в рулбуки.
НАСТАЛО ВРЕМЯ ПИЗДИТЬ ХОРУСА НОГАМИ.
Кстати в групповых чатах хуй знает как это заставить работать нормально. Так как группа может иметь топик для беседы, но сука он только у следующего говорящего в голове появляется. А если он не продолжает тему то всё тухнет. В итоге я вручную иногда включаю отключаю записи.
Делай карточку с несколькими персонажами.
Возможно грокинг частично решен.
https://www.youtube.com/watch?v=SRfJQews1AU
Показан некий коллапс софтмакса.
Как я понял, в момент переобучения сети, она вместо того чтобы учится чему-то дальше, просто масштабирует выход. Ответ она как бы уже знает, и функция потерь в основном дожимает выход до крайних значений. Это объясняет столь долгую фазу до начала грокинга.
https://www.youtube.com/watch?v=SRfJQews1AU
Показан некий коллапс софтмакса.
Как я понял, в момент переобучения сети, она вместо того чтобы учится чему-то дальше, просто масштабирует выход. Ответ она как бы уже знает, и функция потерь в основном дожимает выход до крайних значений. Это объясняет столь долгую фазу до начала грокинга.
Вот сижу я и думаю. Лорбук это пиздато, лорбук это хорошо, но он работает только с сухими фактами по кейвордам.
А вот динамика отношений, особенно если я хочу долгое раскрытие - должна быть в суммарайзе. Но блять, какой в таверне максимальный размер сумарайза, который не будет проёбан ? Есть ли ограничение, или я могу ебашить туда войну и мир ?
Запрашиваю личного опыта.
А вот динамика отношений, особенно если я хочу долгое раскрытие - должна быть в суммарайзе. Но блять, какой в таверне максимальный размер сумарайза, который не будет проёбан ? Есть ли ограничение, или я могу ебашить туда войну и мир ?
Запрашиваю личного опыта.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Дай линк, пожалуйста




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Миксы от тредовичка с уклоном в русский РП: https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
Архив тредов можно найти на архиваче: https://arhivach.xyz/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: