



Вкот
У меня ощущение от каждого трая лоры как от вскрытия подарка каждый раз кто сейм
У меня ощущение от каждого трая лоры как от вскрытия подарка каждый раз кто сейм
> Я не уточняю, но вообще можно уточнять. Но локон норм и так.
Уточнил короче
> Че за приколы, не влезут, ток что проверил, в 1024 с букетами до 768 еле влезает один, с двумя уже на рам протик.
Сам проверил, действительно переоценил что то, вспомнил просто 11300 чтоли потребление с 2 и спизданул навскидку. 2 влезают точно, прямо сейчас проверил, а больше обычно для мелкого говна и не юзаю энивей, хоть врам и позволяет, но толку нет
> Вообще речь шла у меня в посте про 64 дименшен такто, там один батча то еле влезает, что уж говорить о двух трех.
Ну а нахер тебе такой огромный для одной еот? Хорошего человека должно быть много чтоли?
> У меня лр на юнет какраз 10 щас
Ебанись
> Вармап не юзаю, его как бы заменяет продижистепс параметр, который ищет оптимум лернинг и фризит его
Вот этот продиджистепс вообще какая то шутка. Единственный случай когда продиджи всё зажарит, это когда ты рестарт на лре сделаешь, он такое точно не любит и плавные шедулеры для него мастхев, а так он обычно если ему лр не хватает, от падения шедулера сам начинает его вверх дёргать, шедулер не до нуля обычно, а до 0.01-0.005 хорошо работает
> Не, один чел не сможет так сделать, цивит бы в помойку быстро превратился. Тут дору взяли потому что не хуй с горы сделал а нвидиеподсосы.
AYS тогда почему не сделали? Я помню там кто то, кто первую дору выложил и писал им чтобы добавили
> Это скорее алгоритм ДЛЯ ликориса. И ничеси очередной, почти полноценный файнтюн без нужды дрочить фул модель, лафа для врамлетов и гораздо меньше временных затрат.
Ты уверен? Оно тренилось когда я пробовал намного дольше, единственный плюс, что врам типо засейвит, а толку ноль, во времена поней даже оно нихуя от обычных не отличались, единственный верный способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть, ценой пиздеца по датасету, даже глора не спасала, вот всё перепробовал, прямо помню это чётко с аутизмом этим ебучим
> Ну глора это вот алгоритм репараметризации. Ты можешь эту глору вместо с дорой юзать, у них вообще разные задачи и наверно они дополнят друг друга. Кстати надо попробовать, интересно че будет, в сдскриптс вроде есть.
Я в курсе, что дора поверх других алго работает, с аутизмом ничего не помогло, опять же
> Забей место под ADOPT, другой сверхточный адам форк https://github.com/iShohei220/adopt
Да этих новых оптимайзеров как говна за баней, с каждого теперь охуевать чтоли? Вон иди попробуй фишмонгер, он ещё хлеще продиджи там по визуализации был в одном трункорде https://github.com/Clybius/Personalized-Optimizers и я на нём делал пару лор, они действительно заебись перформят, но у тебя небось не влезет в память, там 2 батч уже лучше 16гб и дольше продиджи в 2 раза, будто флюкс тренишь
Вон ещё охуевай, мемори эффишиент и фаст, потому что адам, с фичами https://github.com/lodestone-rock/torchastic
Как тред то ожил, сколько написали. Теперь читать вас и отвечать.
>Ну а нахер тебе такой огромный для одной еот? Хорошего человека должно быть много чтоли?
Ну параметризация больше моментная в работе, потенциальная точность выше, выше мощности адаптации модели и её способности захватывать более сложные паттерны в данных. Это особенно хорошо видно когда тренишь отдельные слои как в случае с билорой, выставил 1024 если ты 4090 боярин 128 и оно прям дышит сразу и в разы проще наваливает. Если оно работает с отдельными многомерными слоями то почему не работает с полными параметрами? Всегда можно отресайзить потом по финалу.
>Ебанись
А что, не запрещено - значит разрешено. Тем более работает и решает задачи.
>Вот этот продиджистепс вообще какая то шутка
Не, не шутка. Т.к. шедулера тут нет, то продижи надо пинком отрубать чтобы вызвать т.н. escape velocity и чтобы он перестал уменьшать свою полезность бесконечно, можешь тут почитать принцип https://arxiv.org/pdf/2409.20325
>шедулеры шедулер
Так речь про бесшедулерный...
>AYS тогда почему не сделали?
AYS это шедулер для семплеров же, буквально просто функция одной строчкой от лабы нвидии. Куда ее добавлять собрался?
>Ты уверен?
Ну да. Дора это такой читкод на фулпараметрик без полноценного фулпараметрика.
>Оно тренилось когда я пробовал намного дольше, единственный плюс, что врам типо засейвит, а толку ноль, во времена поней даже оно нихуя от обычных не отличались, единственный верный способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть, ценой пиздеца по датасету, даже глора не спасала, вот всё перепробовал, прямо помню это чётко с аутизмом этим ебучим
Чет я мысль твою потерял, переформулируй
>способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть
Не ну зажарить иногда бывает полезно, потом просто лорку можно поменьше весом применять и тольковыигрывать. Не с дорой конечно, т.к. там шаг влево шаг вправо от базового веса уже ощутимая потеря данных идет.
>с аутизмом ничего не помогло, опять же
Ну ты вот пишешь то не работает, то не работает, я ж вообще понятия не имею как ты тестируешь, тренируешь, какой юзкейс у этого всего. Может ты там 3000 степов на эпоху страдаешь вообще по 60 часов лору тренишь и с хоть малейшим смазом на гене отбраковываешь и начинаешь заново, а гены пускаешь на какомнибудь Dormand–Prince в миллиард шагов. У меня лично есть несколько рабочих вариантов как даже самый всратый тренинг заставить терпимо работать. Принцип тренинга же в чем вообще заключается? В том чтобы он давал результат безотносительно того как ты этот результат достигаешь. В чем проблема недотренов и перетренов? В недостатке или избытке данных и последующем денойзе этих данных. По факту дифузные модели уже с первых шагов понимают и знают калцепт который ты им кормишь, единственный вопрос в достаточности и точности данных, которые сеть получает во время тренировки дальше чтобы тюнить свои вектора, и разными способами можно заставить сетку считать, что достаточность данных для инферирования в результат на месте.
>Да этих новых оптимайзеров как говна за баней, с каждого теперь охуевать чтоли?
Да понятно что любой лох может оптимайзер сделать, но тут университет токио все дела, оптимизер без нужды тюнить параметры тренировки и с хорошей скоростью и точностью базированный на адаме.
>Вон иди попробуй фишмонгер
Давай попробую, че там как его настраивать?
>и я на нём делал пару лор, они действительно заебись перформят
Покажи + настроечки
>Вон ещё охуевай, мемори эффишиент и фаст, потому что адам
Круто, но это просто мемори эфишент мод со знижением байтов на параметр. ADOPT про другое.
> Всегда можно отресайзить потом по финалу.
Неа, не всегда, некоторые алгоритмы до сих пор не ресайзятся с сд-скриптс, полагаться можно только на лору и локон в этом плане и плане мерджей. Костыли правда я видел, для глоры той же были скрипты где то на форчонге
> Не, не шутка. Т.к. шедулера тут нет, то продижи надо пинком отрубать чтобы вызвать т.н. escape velocity и чтобы он перестал уменьшать свою полезность бесконечно, можешь тут почитать принцип https://arxiv.org/pdf/2409.20325
Ну ёпта там всё в матане, короче продиджи в стоке шедулфри через жопу работает и если эстимейшен не выключить на определённом шаге будет пиздец с нетворком?
> Так речь про бесшедулерный...
Реально не пойму в чём прикол убирать шедулер, он всегда в диапазоне двух порядков от лр нормально работает, или вообще до нуля, ладно там лр искать заёбно, но шедулер то, плюс ещё придётся ебаться с параметрами поновой искать, судя по тому что в основной репе пишут, один гемор
> AYS это шедулер для семплеров же, буквально просто функция одной строчкой от лабы нвидии. Куда ее добавлять собрался?
В генератор на сайте, куда же ещё, тоже ведь от нвидии
> Ну да. Дора это такой читкод на фулпараметрик без полноценного фулпараметрика.
Вот этот читкод сейчас полностью облажался при тренировке гойвэя впреда, с энкодером сдохло просто и пережарилось, юнет онли нан. На сам попробуй, если хочешь https://files.catbox.moe/8bpnnx.toml без доры нормально, там тольк минснр ёбнутая указана по фану проверить, с ней работает без доры и на адаме и на продиджи
> Чет я мысль твою потерял, переформулируй
Я пытался генерализовать максимально одного маняме хуйдоджника известного в узких кругах с аутизм чекпоинтом, фангдонга, он в основном к*ичек рисует, тестил на конкретном промпте, который был отдалён от того что он рисует, там была какая то кошкодевка с блюарка с огромными бидонами в купальнике, что очень отдалённо, ни один алгоритм из доступных полгода назад не выдал стиль на этом промпте, только одна лора, которую я взял с цивита работала на этом и почти всех остальных промптах, она по факту была ужарена, но я хотел повторить это, ведь ничего не работало, глянул в мету, там тренилось на похуй стоком с адамом прямиком с аутизма на малом датасете, ну сделал так же и получилось с первого раза по перформансу схоже с той, что была на циве, и та и другая по датасету выдают ужас, если кэпшен 1в1 копировать, но генерализация у них охуенная
> Ну ты вот пишешь то не работает, то не работает, я ж вообще понятия не имею как ты тестируешь, тренируешь, какой юзкейс у этого всего. Может ты там 3000 степов на эпоху страдаешь вообще по 60 часов лору тренишь и с хоть малейшим смазом на гене отбраковываешь и начинаешь заново, а гены пускаешь на какомнибудь Dormand–Prince в миллиард шагов
Ну вроде выше расписал понятно что я пытался сделать
> По факту дифузные модели уже с первых шагов понимают и знают калцепт который ты им кормишь, единственный вопрос в достаточности и точности данных, которые сеть получает во время тренировки дальше чтобы тюнить свои вектора, и разными способами можно заставить сетку считать, что достаточность данных для инферирования в результат на месте.
Это всё здорово конечно, но есть огромные байасы у чекпоинтов, тот же пони или дериватив аутизм (который ещё хуже говноговнапростоблять) практически невозможно направить в определённое русло, считай в пэинтерли стили, без лютых танцев с бубном, yd, fkey или ciloranko на них выглядят и тренятся отвратительно, а, например, на люстре заебись
> Да понятно что любой лох может оптимайзер сделать, но тут университет токио все дела, оптимизер без нужды тюнить параметры тренировки и с хорошей скоростью и точностью базированный на адаме.
Когда уже там будет оптимайзер, который сам лучшую архитектуру и датасет подберёт, а после чекпоинт натренит по запросу за часок с нуля? Ну что, как он в деле в итоге?
> Давай попробую, че там как его настраивать?
Я в рекомендуемом дефолте его гонял вообще с адамовским лром, с ним особо быстро не покрутишь и хз как будет не на впредонубе, ну смотри сам короче, конфиг такой был https://files.catbox.moe/i2ed6m.toml прикостылил к изи-скриптсам сделав из него питон пэкэдж
>Неа, не всегда, некоторые алгоритмы до сих пор не ресайзятся с сд-скриптс, полагаться можно только на лору и локон в этом плане и плане мерджей. Костыли правда я видел, для глоры той же были скрипты где то на форчонге
Ну можно по старинке смерджить лору с моделью а потом экстракцию ликориса в нужный дименшен произвести.
>короче продиджи в стоке шедулфри через жопу работает и если эстимейшен не выключить на определённом шаге будет пиздец с нетворком?
Не совсем так. Если никак не контролировать lr юнета на продигах он просто вечно будет его увеличивать. Не то что бы это было плохо, но в теории он может проскочить свитспот (шедулер фри константные) и тренить не так эффективно при определенных условиях. Это можно доджить через кучу разных параметров впрочем. Параметром продижи степс ты просто указываешь продигам шаг после которого лр обязать стать константой для него.
>Реально не пойму в чём прикол убирать шедулер,
Бесшедулерный оптим очень гибкий и реагирует на loss/градиенты, классика жесто привязана к функции шедулера (косинус хуесинус вот ето все, как барен матанского мира решил так и будет). Бесшедулер быстро реагирует на лосс, каждый шаг, классика реагирует только каждую эпоху. Очевидный плюс в меньшем количестве тюнинга конфига. Не нужен вармап.
>плюс ещё придётся ебаться с параметрами поновой искать
Да там в d0 менять только, в зависимости от того насколько агрессивно и бысттро ты хочешь обучать.
>В генератор на сайте, куда же ещё, тоже ведь от нвидии
Не, дора прям разработка мозгов из нвидии, даже в блоге у себя писали, AYS это так чисто разнообразить количество шедулеров и решить конкретную задачу.
>На сам попробуй
Странные настройки у тебя, я бы половину повыкидывал сразу.
>с энкодером сдохло просто и пережарилось, юнет онли нан.
Датасет дашь какой тренил?
>гойвэя впреда
Ой я вперды не тренил никогда, там какие-то особые условия есть?
>Ну вроде выше расписал понятно что я пытался сделать
Дай датасет крч и ссылку на лору или гены на которые ты ориентируешься по квалити, плюс ссылку на проблемный чекпоинт
>Когда уже там будет оптимайзер, который сам лучшую архитектуру и датасет подберёт, а после чекпоинт натренит по запросу за часок с нуля?
Неиронично билору тренить на одной картинке проще всего по такому запросу лол
>Ну что, как он в деле в итоге?
Адопт чисто не гонял, только в комплекте с шедфри продиги, и он даже работает. Ну консистенцию увеличивает да, сразу с первой эпохи, не говнит.
>прикостылил к изи-скриптсам сделав из него питон пэкэдж
А дай гайд кстати
Гандон на кое захардкодил применение fused_backward_pass который пиздец как повышает скорость и снижает юз врама на адафактор онли, ну что за пидераст. А между прочим фьзд изкаропки держит продижи шедулед фри. Как же пичот сука.
>дора прям разработка мозгов из нвидии, даже в блоге у себя писали
Дохуя мозгов видимо потребовалось чтобы магнитуды вынести в отдельный параметр.
ну ты ж не вынес, значит одного мозга не достаточно
> Ну можно по старинке смерджить лору с моделью а потом экстракцию ликориса в нужный дименшен произвести.
Не ну ты слышь, читы то не включай
> Не совсем так. Если никак не контролировать lr юнета на продигах он просто вечно будет его увеличивать. Не то что бы это было плохо, но в теории он может проскочить свитспот (шедулер фри константные) и тренить не так эффективно при определенных условиях. Это можно доджить через кучу разных параметров впрочем. Параметром продижи степс ты просто указываешь продигам шаг после которого лр обязать стать константой для него.
Ладно, понял короче
> Бесшедулерный оптим очень гибкий и реагирует на loss/градиенты, классика жесто привязана к функции шедулера (косинус хуесинус вот ето все, как барен матанского мира решил так и будет). Бесшедулер быстро реагирует на лосс, каждый шаг, классика реагирует только каждую эпоху. Очевидный плюс в меньшем количестве тюнинга конфига. Не нужен вармап
К классике вармап и нормальный шедулер с 1.5 не менялся, он тоже везде подходит, но в целом конечно понятно почему у меня хуита была с адамом и флюксом, я там не особо запариваясь просто оптимайзер поменял, но оставил тот же косин и лр даже не поднимал
> Да там в d0 менять только, в зависимости от того насколько агрессивно и бысттро ты хочешь обучать.
Сколько, 1e-4?
> Не, дора прям разработка мозгов из нвидии, даже в блоге у себя писали, AYS это так чисто разнообразить количество шедулеров и решить конкретную задачу.
Тоже через жопу с впредом кстати работает
> Странные настройки у тебя, я бы половину повыкидывал сразу.
Что там странного? Вообще ничего лишнего даже не стоит, чуть ли не сток. А конфиг с фишмонгером не странный а сраный, изискриптс просто калговна и там чтобы кастомный оптимайзер заюзать надо оверрайдом хуярить через экстра арг, в мету всё равно основной оптимайзер запишется, хоть он и не используется по факту
> Датасет дашь какой тренил?
Не сорян, конкретно этот не дам, я уверен там не от него зависит, любой подойдёт
> Ой я вперды не тренил никогда, там какие-то особые условия есть?
Ну теоритически только два флага включить, фактически вот доры в трейнинге и аусы в инференсе отваливаются, бета шедулеру ещё другие альфа и бета нужны, лр поменьше для тренировки лучше юзать, короче нюансов хватает, сигмы там ещё стоит крутить выше, даже кто то я видел скидывал ~35 значений для вставки в кумфи, предположительно используемых в наи
> Дай датасет крч и ссылку на лору или гены на которые ты ориентируешься по квалити, плюс ссылку на проблемный чекпоинт
На короче паком, там только две генерализуются нормально из всех, по гридам увидишь, https://litter.catbox.moe/2t6iys.7z стандартный, чекпоинт https://civitai.com/models/288584?modelVersionId=324524 датасет просто с буру сграбь, будет максимально приближённо к генерализуемым версиям
> Неиронично билору тренить на одной картинке проще всего по такому запросу лол
Вот несколько дней назад делал лору из одной картинки буквально, не стал изобретать велосипед и сделал с адамом и продиджи, справился лучше адам, более менее с такой лорой можно ещё нагенерить датасета, потом уже выёбываться
Да вот просто https://packaging.python.org/en/latest/tutorials/packaging-projects/ в доки глянул

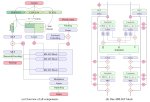
Сначала хотел спросить здесь, но решил сначала сам загуглить. Вопрос был про встроенные в комфи генераторы промтов. Вайлкарты меня заебали, особенно на флюксе который стал их очень хорошо реализует так что начинаю замечать повторы.
Оказалось есть Ollama с локальными текстовыми нейронками к которым можно подключиться через ноду в комфи. Быстро накалхозенный воркфлоу приложен.
Оказалось есть Ollama с локальными текстовыми нейронками к которым можно подключиться через ноду в комфи. Быстро накалхозенный воркфлоу приложен.
Тут тоже спрошу:
Есть ли возможность эту модель
https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
Запихнуть в wd-таггер для WebUI?
Почему-то в списке не появляется. Что-то не то делаю, но что именно - понять не могу. Я сильно тупой для всего этого программирования.
Или может какие-то другие расширения для вебуя появились?
Есть ли возможность эту модель
https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
Запихнуть в wd-таггер для WebUI?
Почему-то в списке не появляется. Что-то не то делаю, но что именно - понять не могу. Я сильно тупой для всего этого программирования.
Или может какие-то другие расширения для вебуя появились?
А я в убабуге запускал всякие нсфв чекпоинты из ллм треда, а в комфи апо апишке подключался (есть ноды под убабугу).
Братан, все гораздо проще
скрипт https://github.com/kohya-ss/sd-scripts/blob/dev/finetune/tag_images_by_wd14_tagger.py
тутор https://github.com/kohya-ss/sd-scripts/blob/dev/docs/wd14_tagger_README-en.md
https://pastebin.com/nuhUkepm tagger/utils.py на это поменяй
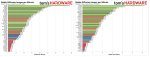
На пике три прогона на одном и том же файле конфига, два одинаковых рана, второй ран чучуть отличается. Почему так нахуй? Если сравнивать чекпоинт с красного графика то он отличается по генам с зеленого (и нихуево так отличается, композ и прочее говно в целом то же но отличается как будто другой сид). Все настройки зафиксированы. Отчего данный факап мог случиться?
Хм. Вероятно это кеш на диск или ошибки округления. +1 к страхам того что нейроговно обосралось с точностью.
>Братан, все гораздо проще
Да скриптом то я и так могу. Ну, почти - если оно с зависимостями не обосрется по какой-то причине, тогда их чинить придется.
Мне именно для вебуя решение нужно было, чтоб и протэгать, и посмотреть, что таггером навалило, и сразу в другой вкладе начать редачить.
Нашел форк таггера, в котором поддержка всех моделей реализована. Хотя модель качать заново пришлось, старую он не увидел. Ну да пофиг, работает - и хорошо.
Сохраню, на всякий случай, спасибо.
> Нашел форк таггера, в котором поддержка всех моделей реализована. Хотя модель качать заново пришлось, старую он не увидел. Ну да пофиг, работает - и хорошо.
А ссылку?
Я просто в форки перешел, и поставил тот, который обновлялся самым последним.
Вот этот:
https://github.com/67372a/stable-diffusion-webui-wd14-tagger
Как же я заебался на глазок подбирать лернинги пиздец просто еб вашу мать
Надо напердолить себе валидейшен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78
Надо напердолить себе валидейшен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78
>еверидрим
ого ебать, живые полторашкошизы
почему валидатора нет нигде больше?
Чет я заебался запускать этот валидейшен лосс, какие-то ошибки ебанутые в коде скрипта. Вроде все правильно делаю, а он не может оптимайзер загрузить из-за какого-то [doc] в скрипте трейна.
Вот есть допустим в целом для питорча https://github.com/davidtvs/pytorch-lr-finder , пытался оптимизнуть код под юнет хотя бы - хуй мне в ебало, максимум че достиг это начало тренинга и мисматч ошибки по тензорам хуензорам.
А кто-нибудь из моделеделов пробовал такую штуку проворачивать с руками:
1) собираем какой-нибудь датасет (пиздим с каггла или ещё откуда-то) с изображениями рук
2) изалекаем из него эмбеддинги, уменьшаем размерность эмбеддингов
3) кластеризуем уменьшенные эмбеддинги, присваиваем кластерам какие-нибудь рандомные хеши
4) идём уже датесет для обучения нашей SD модели, берём YOLO для детекции рук и те квадраты, что нам извлек YOLO мы классифицируем по полученным ранее кластерам (изалекаем эмбеддинги, тем же уменьшителем размерности проецируем, считаем косинусные расстояния)
5) и по результатам классификации мы в теги кладём хеш соответствующего кластера
По идее такой трюк должен существенно улучшить качество рук, но наверняка я не первый, кому она приходила в голову...
1) собираем какой-нибудь датасет (пиздим с каггла или ещё откуда-то) с изображениями рук
2) изалекаем из него эмбеддинги, уменьшаем размерность эмбеддингов
3) кластеризуем уменьшенные эмбеддинги, присваиваем кластерам какие-нибудь рандомные хеши
4) идём уже датесет для обучения нашей SD модели, берём YOLO для детекции рук и те квадраты, что нам извлек YOLO мы классифицируем по полученным ранее кластерам (изалекаем эмбеддинги, тем же уменьшителем размерности проецируем, считаем косинусные расстояния)
5) и по результатам классификации мы в теги кладём хеш соответствующего кластера
По идее такой трюк должен существенно улучшить качество рук, но наверняка я не первый, кому она приходила в голову...
>Чет я заебался запускать этот валидейшен лосс,
Так, наконецто запустил. Ну в принципе удобная штука да чтобы находить промежуток идеального лернинга для датасета. Жаль что прогоны только на ублюдских полторахо чекпоинтах.
Нахуя он тебе всрался то вообще? Вот этот форк типо может https://github.com/67372a/LoRA_Easy_Training_Scripts но там он пиздец поломанный был в стоке когда тестил, и даже через жопу хл тренил, если включить энкодеры, то он тренил только мелкий, баг или что хз, но я ебал, даже оптимайзер в стоке не работал практически ни один нормально. Включи просто продиджи и несколько датасетов натрень, он тебе всё равно покажет лр нормальный средний для того чтобы ставить с адамом
>Нахуя он тебе всрался то вообще?
Чтобы ручками не подбирать.
>Вот этот форк типо может https://github.com/67372a/LoRA_Easy_Training_Scripts
Ебать он у меня стоит, а я не заметил.
>Включи просто продиджи и несколько датасетов натрень
А я че по твоему делаю? Учитывая что у продигов достаточно своеобразные настройки то в лернинг я попал примерно на 20 прогон последний раз.
> он тебе всё равно покажет лр нормальный средний
Нет, ты не понял концепции. У продижи/продижишедулерфри есть параметр d0, который по сути управляет силой обучения. Лернингрейт самих весов и енкодера у него фиксед и настраивается отдельно. Сам d0 продижи не побирает.
>для того чтобы ставить с адамом
Я не пользуюсь адамами.
Вообще, строго говоря, та хуйнюшка которая дрочит полтораху достаточно удобная, потому что делает все быстро со вторым батчем в 512, буквально моментально 10 дестовых эпох на 200 пикчевом датасете ебашит. С хл так быстро не будет ни разу.
Лучший помощник для кодеров GitHub Copilot стал БЕСПЛАТНЫМ сегодня.
Пока открываете шампанское, пару слов о лимитах: 2000 дополнений кода и 50 сообщений к умнейшим нейронкам GPT-4o и Claude 3.5. Всё, что нужно — зайти в VSCode через аккаунт в GitHub.
Надеюсь хоть оно справится с моей задачей и портирует скрипт нормально
Пока открываете шампанское, пару слов о лимитах: 2000 дополнений кода и 50 сообщений к умнейшим нейронкам GPT-4o и Claude 3.5. Всё, что нужно — зайти в VSCode через аккаунт в GitHub.
Надеюсь хоть оно справится с моей задачей и портирует скрипт нормально
Скормил ему https://github.com/davidtvs/pytorch-lr-finder , на какойто из итераций фиксинга оно даже запустилось, но видимо развернуло мне веса в фп100500 и не влезоо ни в 32 рама ни в видяху при этом и ебнулось с ООМ. Последущие фиксы чтобы было все в фп16 к успеху пока не привели. Чисто на гпт там вообще нихуя не заработало есличе, так что копилот мощнее для кодинга определенно.
> Нет, ты не понял концепции. У продижи/продижишедулерфри есть параметр d0, который по сути управляет силой обучения. Лернингрейт самих весов и енкодера у него фиксед и настраивается отдельно. Сам d0 продижи не побирает.
Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0 и лр впринципе, он ведь и разгоняется сам по себе, а ты ему придумал новый лр подбирать, обрубив шедулер
> Я не пользуюсь адамами.
А что так? Лр от продиджи как раз ему и подходит, ну процентов 15 накинь максимум и по идее тот же эффект окажется
>Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0 и лр впринципе, он ведь и разгоняется сам по себе, а ты ему придумал новый лр подбирать, обрубив шедулер
Оптимизация времени обычная. Если ты знаешь оптимум d0 для своего датасета или любой параметр в любом другом бесшедулернике отвечающий за это то ты его указываешь и не ебешь себе мозг пока косинусное говно само себе там чето высчитает на лоу лр за 100500 часов. Это супер критично когда у тебя огромный датасет, а учитывая что дора+локр+скалар это буквально полноценный файнтюн со звездочкой позволяющий хоть 10к картинок датасет обучать, то это неебическое сохранение времени и баланс.
>А что так?
Жрет больше, чем бесшедулерник продижи, а 8бит лютая параша дли совсем нищеты Сложно доджить падение в локальный минимум. Еще и падает не в тот локальный минимум часто. Если датасет вариативный, то как-то хуево с признаками работает сопредельными и убивает вариети. Бесшедулерный адам вообще ебнутый - обучаешь хую, запоминает яички, ну это условно.
>Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0
Кстати нет.
If the model is not training, try to keep track of d and if it remains too small, it might be worth increasing d0 to 1e-5 or even 1e-4. That being said, the optimizer was mostly insensitive to d0 in our other experiments.
> Оптимизация времени обычная
Но ты же 20 ранов сделал ебли, какая тут оптимизация времени то
> Если ты знаешь оптимум d0 для своего датасета или любой параметр в любом другом бесшедулернике отвечающий за это то ты его указываешь и не ебешь себе мозг пока косинусное говно само себе там чето высчитает на лоу лр за 100500 часов
Зачем лоу лр то? Если знаешь тот же лр с обычным адамом, то тоже самое что знать д0 с бесшедулерным. Поставь просто дефолтный 1е-4 на д0 с продиджи безшедулерным, раз уж на то пошло, или ты уже пробовал?
> Это супер критично когда у тебя огромный датасет
Когда у тебя огромный датасет, в эксперименты как то лезть не особо есть желание и хочется юзать то что точно работает нормально, ведь вот подобная
> дора+локр+скалар
Комба литералли обсирается с впредом, начиная с доры, которая нанами начинает сыпать
> 10к картинок
Вообще в лору влезет, от 100к хотя бы был бы смысл в полноценном файнтюне, но учитывая жор хля, либо сосать с мелким батчем на адаме, либо сосать с большим на адафакторе, про продиджи вообще можно забыть
> Жрет больше, чем бесшедулерник продижи
Да ну нахуй, что это за волшебная оптимизация там такая? Может и тюн даже влезет в 24, кто знает
Это кстати буквально недавно добавили https://github.com/konstmish/prodigy/commit/9396e9f1ca817b1988466f46ed40e9f993aef241 на самом деле охуеть интерес к оптимайзеру проснулся, даже начали пры пуллить и ридми обновлять, ну окей, но что 1.5, что хл, до недавнего времени действительно был инсенсетив и трогать д0 смысла не было в стоковой версии
>Но ты же 20 ранов сделал ебли, какая тут оптимизация времени то
Это меньше чем бы я потратил на другом оптимизере. Ты же понимаешь что если трен слишком медленный, или слишком быстрый, то в обоих случаях это на выходе будет замещение весов, ликинг, мутанты, сломанные веса или пережар?
>Зачем лоу лр то?
Потому что базовый лр 1е-4 это лоулр.
>Если знаешь тот же лр с обычным адамом, то тоже самое что знать д0 с бесшедулерным.
Ну так а смысл чето с адамом делать тогда? Тот же самый поиск свитспота, так еще и шедулер трахать.
>Поставь просто дефолтный 1е-4 на д0 с продиджи безшедулерным, раз уж на то пошло, или ты уже пробовал?
Да не работает так как надо. Оно может вообще не тренировать эффективно. С 1e-4 на моем датасете тренинг идет крайне медленно притом что я и лр юнета задираю чтоб побыстрее. Можно делать как ты предлагаешь и терпеть, но это не разумно и не нормально, проще свитспот для d0 найти и потом лр юнета оттюнить туда сюда - это гораздо проще.
>Когда у тебя огромный датасет, в эксперименты как то лезть не особо есть желание и хочется юзать то что точно работает нормально
Дело вкуса. Я предпочитаю точность и меньше тюнинга параметров.
>Комба литералли обсирается с впредом, начиная с доры, которая нанами начинает сыпать
Ты конечно извини, но это 99% вопрос скилишуя, я на твой пост как-то подзабил в ответе и до сих пор не тестировал впред. Вот ты там спрашивал 1е-4 или нет, откуда мне знать, у меня вообще на одном датасете свитспот на 5e-4 находится, а ты какие-то мелкие лернинги берешь вообще непонятно для какого датасета и потом говоришь что ниче неработает.
Кароче, давай сразу попути отвечу
>Что там странного?
Давай начнем с того почему у тебя дименшены одинаковые. Ты тренируешь полное замещение? Смысл? У тебя какойто-то анимушный трен кастомный, судя по всему ты какуюто анимепизду тренишь, так смысл в замещении если тебе надо оставить веса кастомной модели? Хочешь получать датасетовые картинки? Датасет ты мне не показал по количеству сколько там, но судя по степам в 2500 и лернингу в 1 там может и 250 и 25 картинок быть. Опять же непонятно почему ты говоришь про обсер впреда в контексте доры локра и скалярного слоя, если у тебя изначально вообще другое.
Дальше почему min_snr_gamma = 99? Это требование вперда или ты просто от балды ебанул? У тебя градиенты супернеустойчивые и вероятно поэтому наны, но я не уверен.
Почему lr те именно 0.25, если у тебя стоит и так низкий лернинг? Тоже от балды поделил на 4 или есть какое-то обоснование данного мува? Ты тренируешь токен или фул описание?
Зачем вармап в режиме ратио на продиги, если у тебя шедулер контролирует невозможность вечного роста лр?
Почему лосстайп l2 если он неусточив к шуму, а ты тренируешь вперд который работает со скоростью шума, повышает нестабильность и слишком сильно ебет за большие ошибки, что все вместе дает анстейбл лосс?
Почему минимальный букет 256? Эта циферка очень ситуативна и понижает качество и генерализацию на сдхл. С 2048 на макс вообще в шок выпал потому что в этом ноль смысла вообще такто. Допустим у тебя в датасете куча картинок выше 2048 и ты хочешь обрабатывать широкий рендж резолюшенов, чтобы что? У тебя базовая анимушная модель на которой ты тренишь может в 2048 искаропки? По моему мнению гораздо эффективнее было бы тогда настроить нойзофсет, мультиреснойздискант и итерации чтобы детализация/шарп остались на месте, снизив букет до дефолтных 768/1024 и увеличив стабильность градиентов наоборот таким образом, поделив альфу на 2 таким образом у тебя сохранилась бы возможность генерировать хайрезы не прибегая к шизобукету в 2048 пукселей.
Почему репитов именно 10? У тебя супермелкий датасет? Тогда зачем 2500 шагов? Это же шиза.
Зачем кешировать латенты на диск если они багуют частенько?
Косинусный шедулер конфликтует с шедулером из оптимайзера теоретически.
Зачем указан конволюшн дименшен одновременно, если у тебя и так указаны 16x16 по дименшену и альфе? Ты уверен что это не бесполезный параметр в данном случае и локон не является алиасом обычной лоры? Ты перепроверил наличие и фунциклирование конв слоев в лоре после тренинга вообще?
Почему пресет фулл вообще? У тебя мелкий датасет же судя по всему, зачем тренить дримбутлайк фул?
>от 100к хотя бы был бы смысл в полноценном файнтюне, но учитывая жор хля, либо сосать с мелким батчем на адаме, либо сосать с большим на адафакторе, про продиджи вообще можно забыть
Но количество каринок в датасете не коррелирует с оптимайзером, у тебя ж все картинки в латент переводятся просто и потом по мере дрочения юзаются. Не понял проблемы кароч и именно такого вывода по оптимайзерам.
> Вообще в лору влезет
В обычнолору нет, там по струнке магнитуд дирекшена вся дата с 10к пикч выстроится и поломается, т.к. лора либо вносит изменения большой величины + большого направления, либо изменения малой величины + малого направления.
>Может и тюн даже влезет в 24
Может и влезет, у меня нет 24 карты.
>трогать д0 смысла не было в стоковой версии
Хз, на дефолте всегда трогал...
>Дальше почему min_snr_gamma = 99
>там тольк минснр ёбнутая указана по фану проверить
А всё, отразил.
> Это меньше чем бы я потратил на другом оптимизере. Ты же понимаешь что если трен слишком медленный, или слишком быстрый, то в обоих случаях это на выходе будет замещение весов, ликинг, мутанты, сломанные веса или пережар?
Хз к чему ты это, но замещение весов будет всегда, ведь ты их обновляешь тренируя лору, ну и в инференсе накладывая потом это поверх. Ликинг, мутанты и пережар идут почти всегда в комплекте, а вот непослушность энкодера может сильно выделяться
> Потому что базовый лр 1е-4 это лоулр.
Конкретно для чего? Для того чтобы поней стукнуть и они сместили свой ебучий стиль дефолтный, да, помню что на порядок пришлось поднимать, там уже всё вышеперечисленное комплектом как раз и шло, а ниже нихуя считай и не тренилось
> на одном датасете свитспот на 5e-4 находится
Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
> а ты какие-то мелкие лернинги берешь вообще непонятно для какого датасета и потом говоришь что ниче неработает
Этот лр подходит для 90% стилей с буру для аниме моделей, ну или хотя бы частично аниме моделей, люстре кстати в стоке продиджи до 4е-4 задирает, с ней можно в стоке и прибавить в пару раз, с нубом эпсилоном ставит те же 1е-4
> Давай начнем с того почему у тебя дименшены одинаковые
Линейный и конволюшен? Хз, ну этого достаточно чтобы одну хуйню по типу стиля или чара вместить, можно даже конволюшен отключить для чара, что ты предлагаешь сменить?
> Ты тренируешь полное замещение? Смысл?
По другому не работает, смотри лоры выше, они от разных тренирователей с форчка, сработало только полное замещение, причём считай со стоковыми параметрами
> У тебя какойто-то анимушный трен кастомный, судя по всему ты какуюто анимепизду тренишь, так смысл в замещении если тебе надо оставить веса кастомной модели?
Нет, там хуйдоджник анимушный, веса базовой модели нереально стереть лорой впринципе, можно лишь сильно задавить
> Датасет ты мне не показал по количеству сколько там, но судя по степам в 2500 и лернингу в 1 там может и 250 и 25 картинок быть
50 картинок показали себя лучше, там максимум около 75 можно найти консистентных и без повторов, литералли просто на буру зайди и вбей tianliang_duohe_fangdongye, скачай всё это говно граббером, вот тебе и фулл датасет, потом только повторы фильтрани
> Опять же непонятно почему ты говоришь про обсер впреда в контексте доры локра и скалярного слоя, если у тебя изначально вообще другое.
Это вообще отдельная тема, с дорой и впредом походу надо на порядок лр уменьшать минимум, мне лень разбираться, но так в наны падает сразу обычно если огромный лр поставить не подходящий абсолютно, 1е-5 и ниже проверять надо
> Дальше почему min_snr_gamma = 99? Это требование вперда или ты просто от балды ебанул?
Нет, с впредом лосс высчитывается по другому, но если включить минснр, то "по старому", вроде ключ скейла лосса делает тоже самое, но я просто сделал это через минснр, буквально выключив эффект от него таким значением
> Почему lr те именно 0.25, если у тебя стоит и так низкий лернинг? Тоже от балды поделил на 4 или есть какое-то обоснование данного мува? Ты тренируешь токен или фул описание?
Фулл выхлоп с вд теггера, в 4 раза меньше поставил чтобы энкодер не поджигать, в 3-4 раза меньше просто из прошлых экспериментов вывел значение. Опять же, а сколько ты предлагаешь туда ставить? Равный юнету результировал в непослушности с лорой, слишком мелкий в неработающем вовсе теге, если стилей несколько в лоре
> Зачем вармап в режиме ратио на продиги, если у тебя шедулер контролирует невозможность вечного роста лр?
Вообще хз зачем я вармап до сих пор ставлю с продиджи, когда у него свой, надо было хоть сейвгвард тогда влепить чтоли или вообще убрать. Ты уверен что он "вечно" растёт? Я гонял продиджи с флюксом на константе, он максимум там один бамп делал х2 иногда и всё, в то время как когда шедулер начинает стремительный спуск посередине, с лром примерно такая же картина случается из скачков
> Почему лосстайп l2 если он неусточив к шуму, а ты тренируешь вперд который работает со скоростью шума, повышает нестабильность и слишком сильно ебет за большие ошибки, что все вместе дает анстейбл лосс?
Там и выбора то не особо много. Huber или smooth l1 лучше типо будет? Ну хз, экспериментировать опять надо, дефолт хоть как то работает вроде нормально
> Почему минимальный букет 256? Эта циферка очень ситуативна и понижает качество и генерализацию на сдхл. С 2048 на макс вообще в шок выпал потому что в этом ноль смысла вообще такто. Допустим у тебя в датасете куча картинок выше 2048 и ты хочешь обрабатывать широкий рендж резолюшенов, чтобы что? У тебя базовая анимушная модель на которой ты тренишь может в 2048 искаропки?
Это не так работает. Цифры такие элементарно чтобы не ограничивать бакеты вообще, если картинка ультравайд, либо наоборот, она попадёт в соответствующий бакет тренировочного разрешения 1536х512 и наоборот, оно не ставит разрешение 2048 во время тренировки, а крутится вокрут 1024х1024 так или иначе, такие картинки кстати энивей большая редкость
> По моему мнению гораздо эффективнее было бы тогда настроить нойзофсет, мультиреснойздискант и итерации чтобы детализация/шарп остались на месте, снизив букет до дефолтных 768/1024 и увеличив стабильность градиентов наоборот таким образом, поделив альфу на 2 таким образом у тебя сохранилась бы возможность генерировать хайрезы не прибегая к шизобукету в 2048 пукселей.
Вообще хрень какая то полная, если честно. Нойз оффсет нельзя трогать даже палкой издалека, мультирез хоть и очень полезен с эпсилоном, в впреде его трогать увы нельзя и придётся отдать всё на откуп зтснр. Ты же просто предлагаешь ужать бакеты, чтобы получить хер пойми что из датасета по итогу, вообще без понятия как он будет ресайзится и скейлится от такого, а зная кохью, ему вообще никакие ресайзы лучше не давать делать
> Почему репитов именно 10? У тебя супермелкий датасет?
Да, этот был из 15 вроде картинок, я делал лору из одной ебучей картинки итеративно
> Тогда зачем 2500 шагов?
С одной там на 500 уже прогар пошёл лютый, но с 15 уже 2500 зашло, тоже конечно прогар, но всё лишь бы сделать ещё больше для следующей итерации. А 2500 просто многочисленными эмпирическими тестами хл вывел что для стиля хороший свитспот, беря в расчёт остальные параметры того конфига, конкретно с тем датасетом этого много было, но там вери эджи кейс, так сказать, ну и концепты и чары тоже поменьше будут требовать, как и датасеты, в которых меньше 100 картинок например
> Зачем кешировать латенты на диск если они багуют частенько?
Очистить можно, если багнутся просто, почему нет впринципе
> Косинусный шедулер конфликтует с шедулером из оптимайзера теоретически
Там не до нуля косинус, а CAWR до 0.01 обычно, но ты же сам рассказываешь про стратегию "контры постоянно растущего лр", работает и довольно заебато
> Зачем указан конволюшн дименшен одновременно, если у тебя и так указаны 16x16 по дименшену и альфе?
? Чтобы добавить конволюшен слоёв
> Ты уверен что это не бесполезный параметр в данном случае и локон не является алиасом обычной лоры? Ты перепроверил наличие и фунциклирование конв слоев в лоре после тренинга вообще??
То что слои там есть это точно, ведь как минимум лора весит чуть больше, чем обычная лора с линейными слоями, должно работать, насколько эффективно хз как объективно оценить
> Но количество каринок в датасете не коррелирует с оптимайзером, у тебя ж все картинки в латент переводятся просто и потом по мере дрочения юзаются. Не понял проблемы кароч и именно такого вывода по оптимайзерам.
Никакой проблемы. Говорю просто что фулл файнтюн потребует много памяти, не каждый оптимайзер будет реально запустить, тем более с большим батчем
> В обычнолору нет, там по струнке магнитуд дирекшена вся дата с 10к пикч выстроится и поломается, т.к. лора либо вносит изменения большой величины + большого направления, либо изменения малой величины + малого направления.
Хз, я запихиваю тонны нейрокала, тегаю по разному разный нейрокал, что даёт возможность потом это контроллировать, и пока вроде нормально, конечно имеет общий паттерн нейрокаловости, но в этом и есть весь датасет, с фулл тюном не сравнивал конечно, да и туда норм батч хотя бы в 8 с адамом даже не впихнуть скорее всего. С нубом просто больше нехуй тренить считай, всё остальное с буру и так по идее в датасете было
> Может и влезет, у меня нет 24 карты.
Так что там по оптимизациям в итоге?
>но замещение весов будет всегда, ведь ты их обновляешь тренируя лору
Так альфа контролирует насколько ты дефолтные веса тюнишь. Можно избежать практического замещения оттюнив основные веса и не применяя TE, например. В локре допустим вообще факторизация и не требуется указывать дименшены вообще, кроме фактора их сокращения чтобы сделать локр универсальным или наборот только под конкретную модель, то есть по факту с помощью локра ты тюнишь веса основной модели, а не примешиваешь тренинговые веса классической лоры. И посмотреть веса и слои в локре ты тоже не сможешь, потому что их не существует.
>Ликинг, мутанты и пережар идут почти всегда в комплекте
Это неправильно подобранный лернинг, о чем я и говорю.
>а вот непослушность энкодера может сильно выделяться
К вопросу о те, то он то в целом на концепт и не нужен, клипатеншен слои ты так и так тренишь и его хватает. Я бы даже сказал что тренировать ТЕ+веса на токен сразу это какой-то нубский мув, который по факту задействуется чтобы недотрененные веса через ТЕ добирать при генерации до норм состояния, такой ред флаг на то что лернинги неправильно подобраны.
>Конкретно для чего?
Для любого небольшого датасета.
>Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
Unet тестовый на одну бабу тренился на маленьком датасете. Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
>Этот лр подходит для 90% стилей с буру для аниме моделей, ну или хотя бы частично аниме моделей, люстре кстати в стоке продиджи до 4е-4 задирает, с ней можно в стоке и прибавить в пару раз, с нубом эпсилоном ставит те же 1е-4
Но в реальности то эти лернинги не является golden так скажем. Я ж не говорю что их нельзя использовать и терпеть, я про то что идеальный лернинг который тебе в жопу говна не накинет и не потребует снижать/повышать вес применения готового продукта - это тонкая штука которую надо искать.
>Линейный и конволюшен?
Я имею в виду network_dim = 16 network_alpha = 16.0, конволюшены это другой вопрос.
>По другому не работает
Я бы поспорил и даже бы тестовый прогон сделал, но я сейчас другое треню.
>веса базовой модели нереально стереть лорой впринципе, можно лишь сильно задавить
Бля ну если так рассуждать то любой жоский файнтюн это вообще лора обмазанная поверх базовой модели, которая успешно экстрагируется. Я ж не про то.
>50 картинок показали себя лучше, там максимум около 75 можно найти консистентных и без повторов, литералли просто на буру зайди и вбей tianliang_duohe_fangdongye, скачай всё это говно граббером, вот тебе и фулл датасет, потом только повторы фильтран
Ну у тя ж есть готовый сет, скинь.
>Фулл выхлоп с вд теггера
А смысл если сам чекпоинт анимушный и хуйдожник анимушный? Думаешь сетка не разберется сама?
>в 4 раза меньше поставил чтобы энкодер не поджигать, в 3-4 раза меньше просто из прошлых экспериментов вывел значение
А че ты отдельно юнет и отдельно те не тренируешь несвязанно? Пережар происходит из-за несоответствующего схождения во время одновременной тренировки, а так это можно так костыльно обойти в целом.
>Опять же, а сколько ты предлагаешь туда ставить? Равный юнету результировал в непослушности с лорой, слишком мелкий в неработающем вовсе теге, если стилей несколько в лоре
Я бы вообще не тренировал те на стиль такто, максимум на один новый токен, не пересекающийся с основой.
>Там и выбора то не особо много. Huber или smooth l1 лучше типо будет?
Хубер будет лучше да.
>Это не так работает.
В смысле? Ты делаешь букеты по разным разрешениям с шагом 64 чтобы лишний раз не даунсейлить 2048 до 1024, чтобы изображения разных размеров букетировались друг с другом а не 256 с 2048 и не потерять детали разве нет?
Алсо у тя включено enable_bucket = true что добавляет паддинг с черными пукселями вместо скейла, я бы не скозал что это ок.
>Вообще хрень какая то полная, если честно. Нойз оффсет нельзя трогать даже палкой издалека
Я тебе рабочий вариант расписал. У меня датасет с текущей бабой состоит из мыльного говна с переебанными цветами и тонной шумов с размерами от 512 до 1024, вместе с условными --noise_offset=0.05 --multires_noise_discount=0.2 --multires_noise_iterations=7 ^ выходные гены ни в каком месте не имеют ни шумов, ни мыла ни чего бы то ни было вообще.
>Ты же просто предлагаешь ужать бакеты, чтобы получить хер пойми что из датасета по итогу, вообще без понятия как он будет ресайзится и скейлится от такого
Прекрасно будет скейлиться.
>С одной там на 500 уже прогар пошёл лютый, но с 15 уже 2500 зашло
Бля ну как по мне это ну очень дохуя, 15 картинок и 2500 шагов. Я бы не терпел так.
>но ты же сам рассказываешь про стратегию "контры постоянно растущего лр", работает
Ну может быть, я просто предположил что может конфликтовать теоретически.
>Чтобы добавить конволюшен слоёв
Не, я конкретно юзкейс конв в твоем случае. В датасете много текстурок или локальных деталей что сетка не уловит без их помощи на адаме?
>о что слои там есть это точно, ведь как минимум лора весит чуть больше, чем обычная лора с линейными слоями
Они могут быть просто пустыми.
>насколько эффективно хз как объективно оценить
Слайсишь лору на две части - одна лора чисто конв слои, вторая часть это все остальное, тестируешь.
>я запихиваю тонны нейрокала
Вот у меня датасет есть готовый на 7000 пикч с достаточно обширным универсальным концептом, до того как дору выкатили я с обычнолорами так наебался с ним, ничего путного не выходило, урезал вплоть до 1000 - все равно отсос - либо натрениваешь в датасетовские картинки, либо лезет основная модель и насилует бедную лору, хоть медленно трень хоть быстро, то есть было проще дримбудкой целый чекпоинт тренить и потом дифренс вычитать в лору, а сейчас спокойно любой размер датасета всаживается практически в любой алгоритм и лора работает как и должна - быть дополнением для модели и работать аккуратно. Это 1 в 1 как ситуация с первыми нсфв лорами на сдхл типа https://civitai.com/models/144203/nsfw-pov-all-in-one-sdxl-realisticanimewd14-74mb-version-available , где нсфв калтент как бы работает, но эта работа ужасная и ограниченная, насколько я понял там чето около 100к пикч датасета.
>Так что там по оптимизациям в итоге?
В каком смысоле?

>Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
>Unet тестовый на одну бабу тренился на маленьком датасете. Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
Кароче вот эта тестовая лора на 5e4, 3 эпоха всего лишь с датасетом около 10 пикч, оригинал бабцы наверно не надо показывать, просто скажу что основные признаки сетка спокойно сожрала и они на вот это пикче все полном объеме и в принципе на 5е4 дальше можно тренить было, но мне 10 пикч тренить нахер не надо было.


Ну и допом еще две пикчи.
> В локре допустим вообще факторизация и не требуется указывать дименшены вообще, кроме фактора их сокращения чтобы сделать локр универсальным или наборот только под конкретную модель, то есть по факту с помощью локра ты тюнишь веса основной модели, а не примешиваешь тренинговые веса классической лоры. И посмотреть веса и слои в локре ты тоже не сможешь, потому что их не существует.
И что тогда в файле выходном остается? Я пробовал в локр с 1.5 давно, не помню какой фактор ставил, 1000000000000 чтоли, чтобы по размеру был как обычная лора короче в 100мб, там приходилось с лр заёбываться и ставить что то типо в 4 раза больше, чем с обычной, эффекта вау не было, просто другой способ сделать одно и тоже
> К вопросу о те, то он то в целом на концепт и не нужен, клипатеншен слои ты так и так тренишь и его хватает
Концепт как раз тренят обычно включая энкодер, ведь там есть слабые или неизвестные модели токены
> который по факту задействуется чтобы недотрененные веса через ТЕ добирать при генерации до норм состояния
Был даже какой то датасет, который с энкодером лучше намного работал
> Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
Ты не перепутал? Чем меньше датасет, тем быстрее сетка оверфитнется и тем меньший лр лучше ставить, даже выше пример, 1пикча на 500 пиздец, 15 на 2500 не полный, но пиздец, 75 уже вроде ничего на 2500, даже можно было сильнее жарить
> Я имею в виду network_dim = 16 network_alpha = 16.0, конволюшены это другой вопрос.
А, ты имеешь ввиду почему у меня дим и альфа одинаковые? Чтобы не скалировать ничего, нахуя мне лишний дампенер, когда ничего не горит, а наоборот бы натренить посильнее
> Я бы поспорил и даже бы тестовый прогон сделал, но я сейчас другое треню.
Вот если бы я увидел ту кошкодевку в стиле фангдонга, натрененную твоим суперспособом, я бы реально поверил, а так до сих пор считаю все эти алгоритмы просто самовнушением и по большей части базовых вещей и стока хватит для 90% случаев Похуй, читай ниже насчёт конфига
> ну если так рассуждать то любой жоский файнтюн это вообще лора обмазанная поверх базовой модели
Не, это щитмикс называется, лол
> Ну у тя ж есть готовый сет, скинь.
У меня он всратый, нейрокал для паддинга до 120 был добавлен, с таким точно результата не выйдет желаемого по генерализации, да и не очень хочется это заливать куда то, по понятным причинам, сграбь просто с гелбуры, зарегайся, спизди апи ключ и введи в imgbrd grabber, настройки чтобы теги вместе спиздить поставь https://files.catbox.moe/e29fq5.png
> А смысл если сам чекпоинт анимушный и хуйдожник анимушный? Думаешь сетка не разберется сама?
Разберётся конечно, просто параметры с энкодера иногда помогают дотренить, но я и сам не особо люблю идею тренить одиночный стиль с энкодером, но так получается иногда лучше
> А че ты отдельно юнет и отдельно те не тренируешь несвязанно?
Потому что это лишний гемор, когда можно просто поменьше лра поставить
> Я бы вообще не тренировал те на стиль такто, максимум на один новый токен, не пересекающийся с основой.
На мультистиль без вариантов, надо тренить уникальные токены вызова
> Хубер будет лучше да
А ты его тестил с впредом? Может он вообще не работает или через жопу
> В смысле? Ты делаешь букеты по разным разрешениям с шагом 64 чтобы лишний раз не даунсейлить 2048 до 1024, чтобы изображения разных размеров букетировались друг с другом а не 256 с 2048 и не потерять детали разве нет?
Ты делаешь букеты, чтобы пикчи сами просто ресайзнулись до разрешений, смежных твоему выбранному разрешению. Это просто границы бакетинга, если базовое разрешение 1024, всё будет просто ресайзнуто в подходящие разрешения. Если ты укажешь 1280 верхнюю границу с 1024 тренировочным, а у тебя ультравайд 3:1 5400х1800 я на самом деле хз что будет, но она скорее всего ресайзнется в ещё более мелкую хуйню, что не есть гуд
> добавляет паддинг с черными пукселями вместо скейла
Всегда юзал букетинг и ни разу не заметил эффекта этого паддинга
> --noise_offset=0.05
А теперь 2-3-4-10 таких натрень и попробуй стакнуть, охуев от того что будет происходить, мультирез кстати даже маловат, 8/0.4 вполне
> ни шумов
Не усваивает ни одна, по крайней мере аниме, сетка film grain, хоть ты выебись, вае уничтожит ещё на этапе сжатия это всё, только в фш накидывать после
> 15 картинок и 2500 шагов. Я бы не терпел так.
Так они быстрые с батчем в 1 за 15 минут и без чекпоинтинга, потому что влезает, терпеть это когда пытаться нормально натренить и вдруг узнать, что с мелким датасетом было лучше и надо крутить что то, потому что мелкие датасеты насыщаются быстрее, это тупо база
> Не, я конкретно юзкейс конв в твоем случае. В датасете много текстурок или локальных деталей что сетка не уловит без их помощи на адаме?
Любому стилю не помешают, в любом сколько нибудь выделяющемся есть какие то особенности лайна как минимум, даже в однотипном анимекале, персу не критично естественно
> Слайсишь лору на две части - одна лора чисто конв слои, вторая часть это все остальное, тестируешь.
Воркфлоу есть для такого или чем делать?
> либо натрениваешь в датасетовские картинки, либо лезет основная модель и насилует бедную лору, хоть медленно трень хоть быстро, то есть было проще дримбудкой целый чекпоинт тренить и потом дифренс вычитать в лору, а сейчас спокойно любой размер датасета всаживается практически в любой алгоритм и лора работает как и должна - быть дополнением для модели и работать аккуратно
Ну окей, если не захочешь в итоге сам фангдонга собирать и тренить, то хотя бы скинь фулл конфиг, расчехлю пони и постараюсь в адекватное сравнение с предыдущими попытками генерализации того хуйдоджника на примере той кошкодевки, используя оригинальные работы без нейрокала
> В каком смысоле?
Что делал чтобы продиджи требовал меньше врам, чем адам?
> Кароче вот эта тестовая лора на 5e4, 3 эпоха всего лишь с датасетом около 10 пикч, оригинал бабцы наверно не надо показывать, просто скажу что основные признаки сетка спокойно сожрала и они на вот это пикче все полном объеме и в принципе на 5е4 дальше можно тренить было, но мне 10 пикч тренить нахер не надо было.
Ну это шагов за 500 небось, если не меньше в 2-3 раза с таким мелким датасетом, опять же, если бы было 100, задача бы усложнилась, в отрыве от других параметров кстати довольно бесполезно знать лр, может у тебя соотношение альфы там 1/128 или дропаут какой огромный, но раз утверждаешь что есть конфиг для генерализации даже огромного количества пикч, то я бы попробовал

>Вот есть допустим в целом для питорча https://github.com/davidtvs/pytorch-lr-finder
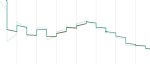
Так, вроде заставил эту хуйню работать, с полторахой правда и оно не помещается в гпу, но работает


Заставил работать в фп16, хуй знает как но оно работает. Непонятно правда как правильно настроить лол.
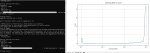
Както оно странно работает, тот же прогон без изменения настроек, лосс улетел в жопу
Suggested learning rate: 1.20e-04


А всё, там рандом сид каждый раз был. Ввел фикс сид все стало повторяемым. Теперь вопрос как этой хуйней пользоваться нахуй. Кто хочет потестить?
Не ну в принципе оно ебашит нормально. Если датасет увеличивается в 2 раза, то лернинг советуемый падает как и должно быть. На батче 2 нереально за 100 итераций вызвать нестабильность градиента.
Хоть какаято польза от полторашного чекпоинта, лол, считает моментально.

Ради теста бахнул стартовой точкой для датасета в 100 картинок 2e-3, оно мне сразу выдало повышающийся лосс, то есть определенно ниже нужно. Работает блядж!
Кароче я так понимаю основной принцип что нужно вызвать нестабильность для градиента, и примерно 10 эпох от количества картинок, то есть датасет в 100 картинок требует 1000 шагов постоянного повышения лернинга для чекинга градиентов. Щас проверим.
>Ну это шагов за 500 небось, если не меньше в 2-3 раза с таким мелким датасетом, опять же, если бы было 100, задача бы усложнилась,
139 шагов
>может у тебя соотношение альфы там 1/128
16/8 вроде, или 8/4
>дропаут
Не пользуюсь, он не нужон на продигах
>И что тогда в файле выходном остается?
локальная адаптация весов с помощью свёрточных операций, они не имеют визуализации в виде отличных друг от друга AB слоёв, буквально адаптация весов и слоев модели, а не добавление натрененных слоев как с классикой
сам состав локра сложный, я так сразу не скажу не подглядывая
>не помню какой фактор ставил, 1000000000000 чтоли, чтобы по размеру был как обычная лора короче в 100мб
Э ну там несколько не так работает, вес зависит от параметра факторизации - чем он ниже, тем больше параметров в итоговой лоре и тем больше ее вес вплоть до фактора 1 размером с полную модель, а если указать -1 то это будет минимальная лора из возможных, точно не скажу но чето около нескольких мегабайт, если не сотен килобайт. В целом там в дименшен нетворка можно хоть триллиард поставить циферку, ее главное назначение чтобы она была больше 10к с копейками чтобы факторизовать веса, если меньше поставишь то там деление не произойдет просто и тренинг не запустится.
>Концепт как раз тренят обычно включая энкодер, ведь там есть слабые или неизвестные модели токены
>Был даже какой то датасет, который с энкодером лучше намного работал
Я треню концепт на 1 токен если нужно с те. А баба сверху например вообще без те, и там клипатеншен захватил последовательность символов в качестве токена из кепшена и его можно юзать. Собсно поэтому я дрочу на правильный тренинг весов, потому что при правильном тренинге те и не нужен.
>Ты не перепутал? Чем меньше датасет, тем быстрее сетка оверфитнется и тем меньший лр лучше ставить
Нет, я все правльно скозал. Чем меньше датасет тем меньше даты для запоминания, тем выше лернинг для градиентов.
> 1пикча на 500 пиздец, 15 на 2500 не полный, но пиздец, 75 уже вроде ничего на 2500, даже можно было сильнее жарить
У нас разные эти как их пайплайны работы, у меня вообще другой опыт с моими вариантами мокрописек.
> Чтобы не скалировать ничего, нахуя мне лишний дампенер, когда ничего не горит, а наоборот бы натренить посильнее
Ну я понял что тебе выдача и знания самой модели не особо важны.
>Не, это щитмикс называется, лол
Ну как ето, можно же спокойно разницу в лору из любого файнтюна вытащить.
>У меня он всратый
Чел мне так лень заново делать когда у тебя уже есть. Мне без разницы всратый или нет, я и так со всратками работаю постоянно.
>Потому что это лишний гемор
Всего то в два раза больше времени, зато потом все работает как часеки.
>На мультистиль без вариантов, надо тренить уникальные токены вызова
Опять же спокойно можно на стиль тренировать без те, это не какаято особая магия.
>А ты его тестил с впредом? Может он вообще не работает или через жопу
Не тестил, но хуюер сам по себе мягкий и совмещает л1 и л2 в зависимости от типа ошибки.
>Ты делаешь букеты, чтобы пикчи сами просто ресайзнулись до разрешений, смежных твоему выбранному разрешению. Это просто границы бакетинга, если базовое разрешение 1024, всё будет просто ресайзнуто в подходящие разрешения. Если ты укажешь 1280 верхнюю границу с 1024 тренировочным, а у тебя ультравайд 3:1 5400х1800 я на самом деле хз что будет, но она скорее всего ресайзнется в ещё более мелкую хуйню, что не есть гуд
Ну вопервых я бы скозал что гигабукеты для сдхл уменьшают скорость сходимости, вовторых я бы не скозал что мелкая хуйня это какая-то проблема вообще для нейросеток ибо латент хуе мое, многомерное пространство признаков, что скукожилось выкукожится. Мне понравилось тренить каскад одно время когда он чучуть хайповал, там можно на ультракале из шакалов обучать достойно было.
>Всегда юзал букетинг и ни разу не заметил эффекта этого паддинга
Медленные лернинги вероятно. Если аналогично с альфой грузить пикчи которые обрабатываются как черный цвет то на высоких лернингах оно схватит и будет срать ими. Хотя опять же может это конкретный кейс альфаканалов, но я на всякий случай не букеирую со скейлом.
>А теперь 2-3-4-10 таких натрень и попробуй стакнуть
Не стакаю лоры, они же замещают друг друга, если только это не архитектрный дистиллят и лора контента.
>Не усваивает ни одна
Глора спокойно любое говно схватит и умножит.
>Так они быстрые
Какая карта?
>Воркфлоу есть для такого или чем делать?
Слои можно списком посмотреть через анализатор в кое или аналогичный скрипт, далее можно скриптом слайсить вот этим например https://github.com/ThereforeGames/blora_for_kohya ток расписать трейты под себя.
>Что делал чтобы продиджи требовал меньше врам, чем адам?
Я ниче не делал, просто наебенил себе шедулерфри.
>Вот несколько дней назад делал лору из одной картинки буквально
Как думаешь, есть смысл докидывать в датасет похожих картинок чтобы только греть оптимайзер на них? По сути просто побочные картинки в датасете, для которых будет нулевой или околонулевой лр.
Ого, я оказывается неправильно понял документацию. Надо не на уебавшийся лосс смотреть, а генерировать нисходящий лосс в начале и брать примерно середину. Интересно, то же самое дает валидейшен в евердриме, ток дольше по времени. Завтра кароч перну в гитхаб этой хуйней может кому итт пригодится.
Алсо может вы придумаете че еще можно прикрутить. Я вместо МСЕлосса хубер прихуячил например.
https://github.com/deGENERATIVE-SQUAD/stable-diffusion-lr-finder
Вот скрипт, можете погонять
Принцип работы по факту аналогичен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78

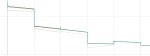
Запустил тренинг бофт. Лучше бы блять не запускал.

тренишь бофт
@
понимаешь что в комфе нет поддержки
да блять
@
понимаешь что в комфе нет поддержки
да блять




блять ну зато в вебуе обосраном работает конечно ебать свинья лежит там где не ждешь
ну результ бофты кароч шикарный, даже на первой эпохе ебет, взял датасет для теста из 600 пикч Cindy Shine с легалов, не тегировал
из минусов: как и случае с локром какой-то параметр или его отустствие (допустим конволюшн блоков нет ни там ни там и их в целом нельзя вкл сделать) не позволяет генерить без мутантов в нестандартных размерах, хотя основная модель позволяет, вероятно возможно надо было тренить ток атеншн, а не прям веса тюнить под 768 разрешение
ну и считает вечность конечно
3 эпоха, 453 шага с батчем 4
1 пикча с датасета, остальные лоурес гены, 4 кроп литса с нсфв контентной пикчи с расширенной песдой
еще хуйцы с порнухи все схватило нормально так и всякие позычи и нюансики детальки




> не позволяет генерить без мутантов в нестандартных размерах
То есть вот проблематика какая, первый три пикчи с разными настройками, с и без консистенси алайнерами, четвертая дефолт ген модели
Всё в 1024x1400
Если кто знает в чем прекол может быть подскажите




Не ну теоретически может быть банальный оверфит, потому что все более менее работает на весе бофта в 0.5, но тогда похожесть литса модели теряется (хотя я на нее и не тренил но все равно хочеца применять лорку на весе 1 в любом случае)


Щас бы еще понять в каком месте оверфтинулось и из-за какой настройки
Пикчи по эпохам 1 2 3, вес 0.5
>Если кто знает в чем прекол может быть подскажите
>1024x1400
Занижай разрешение, очевидно же.
ИИ имеет свойство заполнять персом все пространство, если ты ему жестко не говоришь делать обратное (т.е. в промпте много пишешь про окружение, плюс разные "ландщафтные" тэги типа изображения используешь).
Плюс потеря когерентности, ибо разрешение таки уже предельное.
И тут ты еще своей лорой говоришь рисовать исключительно тянку.
Вот у модели крыша от совокупности проблем и едет.
На более низких разрешениях, типа 1280х768 должно получше быть, даже учитывая какие-то проблемы с лорой.

Нет, ты не понял.
Модель на которой я треню натренена так что внедатасетовые размеры спокойно жрет, что я показываю пикчей 4 тут
Помимо этого дистиллят дмд2 в качестве алайнера сам по себе задизайнен на хайрезы.
Как только я применяю натрененный бофт с весом 1 начинаются мутанты на разрешении выше 1024-1280. Но если снижать влияние лоры до 0.5 то все устаканивается.
Для сравнения та же проблема с фуловым весом локра на пикче, в целом все консистентное но есть небольшая вытяжка тела, но по итогу он более лутше отрабатывает фул вес лоры. Если снижать вес, то там вообще чикипуки все.
То есть налицо проблема в тренинге, вопрос в чем именно.
Различие между конфигами локра и бофты буквально незначительно уровня отсутствия скалярного слоя у бофт и лернингов, единственное что есть у обоих - декомпрессия весов с помощью доры. Вероятность что это дора подсирает?
Так я про совокупность говорю.
На 4-м пике из поста тоже проблемы есть, просто из-за позы и заполнения кадра не такие заметные.
А ты своей лорой буквально приказываешь модели рисовать стоящую тянку на фоне стены и дивана. Да еще и на высоких разрешениях. Вот ее и вытягивает.
Когда занижаешь влияние лоры - модель рисует тянку с более корректной анатомией, так как старается отработать больше из своего датасета, а не из того, что ты натренировал. Отсюда и частичное исправление.
Другими словами, я бы не в архитектуру или настройки тренировки копал, а в то, что именно ты тренировал.
Ну или просто занизил разрешение, и посмотрел, как оно будет работать.
Если такие мутанты даже на минимальном 1024х768 будут - явно косяк в тренировочных параметрах. Если нет - значит, ты просто изнасиловал модель своим стремным сетом, и на тренировку плеваться не надо.




Касательно твоих тезисов
>ИИ имеет свойство заполнять персом все пространство, если ты ему жестко не говоришь делать обратное (т.е. в промпте много пишешь про окружение, плюс разные "ландщафтные" тэги типа изображения используешь).
Я не расписываю ничего, буквально несколько токенов вызовов уровня гирл стендинг, можно вообще без вызовов генерить.
>Плюс потеря когерентности, ибо разрешение таки уже предельное.
Зависит от базовой модели и мокрописек. Если шринк включать там все выравнивается и работает, но шринк это костыль.
>И тут ты еще своей лорой говоришь рисовать исключительно тянку.
Так датасет из тянки в модели которая полностью из тянок, даже с пустым промтом будет тянка. Ладно, давай попробуем без упоминания тянок.
skyscraper photo with car 1024x1400
Локр фул вес, локр 0.5 вес, бофт фул вес, бофт 0.5 вес
>На более низких разрешениях, типа 1280х768 должно получше быть
Так я и говорю что базовые разрешения норм.


>На 4-м пике из поста тоже проблемы есть
Нет, там нет никаких проблем. Вот тебе еще дефолт гены в еще более высоком разрешении.
>стоящую тянку на фоне стены и дивана. Да еще и на высоких разрешениях. Вот ее и вытягивает.
Можно то же самое сделать на дефолт модели и без каких-либо мутантов. В этом проблема.
>Ну или просто занизил разрешение, и посмотрел, как оно будет работать.
Ало, очевидно же что дефолт работает как надо.
>Другими словами, я бы не в архитектуру или настройки тренировки копал, а в то, что именно ты тренировал.
>Если нет - значит, ты просто изнасиловал модель своим стремным сетом, и на тренировку плеваться не надо.
Данных проблем не было на локоне и глоре.
Кароче, гпт мне сказало
Проблемы с артефактами и дублированием объектов чаще связаны с:
Некорректным масштабированием параметров LoRA.
Недостаточной адаптацией LoRA к высоким разрешениям.
Попробую кароч бакеты для начала повысить у локра.
Если мое предположение верно то тренировка глоры и локона насколько я помню была с включенными аугментациями типа --random_crop, флипы и даже колор, если щас окажется что так и есть и рандом кроп решит проблему ебаных мутантов на локре и бофт то буду очень рад
Да, проверил лоры с любыми кроп аугами (даже чисто на литсо) все они генерят не в размер спокойно без мутантов. Даже локр я оказывается уже тренил в таком ключе а потом чето все ауги убрал. Ебаный насос.
> 139 шагов
Как оно вообще в теории то должно успечь нормально пропечься, учитывая равномерное распределение таймстепов в стоке?
> чем он ниже, тем больше параметров в итоговой лоре и тем больше ее вес вплоть до фактора 1 размером с полную модель
Да, вспомнил, фактор 4 и дим дохуя ставил, чтобы получить эквивалент обычной лоры, короче не впечатлило, больше ебли, результат тот же
> Я треню концепт на 1 токен если нужно с те
А, лол, ты вообще без тегов чтоли хуяришь, ну это был полный забей на пони, когда я тестил, даже юнет онли лучше в тегами выглядел
> потому что при правильном тренинге те и не нужен
На что то одно да, а дальше нужно уже и те и разделение тегами
> У нас разные эти как их пайплайны работы, у меня вообще другой опыт с моими вариантами мокрописек.
Видимо, у меня обычно просто лора лопается, если пикч мало и неадекватный лр выставлен, поэтому абсолютно противоположный экспириенс, может дедомодели от анимушных отличаются конечно
> Ну я понял что тебе выдача и знания самой модели не особо важны.
Неиронично, я ещё не встречал ни одну хл модель, которая бы после накладывания лоры поверх не выпрямлялась бы, буквально все работают просто лучше с лорой и это какая то общая проблема шероховатости файнтюна, да и затереть там "скином" на стиль нереально, опять же повторю, особенно если специально не устраивать прогар
> Чел мне так лень заново делать когда у тебя уже есть. Мне без разницы всратый или нет, я и так со всратками работаю постоянно.
Да не в этом дело, даже очищенную версию просто заливать куда то не особо хочется, поглядел бы что там, понял бы что имею ввиду, а на буре уже валяется и стянуть любой может напиши чтоли хоть фейкомыло какое, туда хоть скину лучше
> Опять же спокойно можно на стиль тренировать без те, это не какаято особая магия.
Разделять потом как разные стили?
> Не тестил, но хуюер сам по себе мягкий и совмещает л1 и л2 в зависимости от типа ошибки.
Это смуз л1 вроде так делает, а не сам хубер, да и с впредом там в целом уже как то по другому всё с лоссом изначально
> Ну вопервых я бы скозал что гигабукеты для сдхл уменьшают скорость сходимости
Любое увеличение разрешения её снизит
> Мне понравилось тренить каскад одно время когда он чучуть хайповал, там можно на ультракале из шакалов обучать достойно было
Жаль тюнов кстати так и не появилось нормальных, в целом база не самая плохая была бы, модальная, нашли бы как тренить и врамлетам, и если надо, гигачедам с H100
> Медленные лернинги вероятно. Если аналогично с альфой грузить пикчи которые обрабатываются как черный цвет то на высоких лернингах оно схватит и будет срать ими. Хотя опять же может это конкретный кейс альфаканалов, но я на всякий случай не букеирую со скейлом.
> Не стакаю лоры, они же замещают друг друга, если только это не архитектрный дистиллят и лора контента.
Короче я в целом понял, ты на огромном лр одну вжариваешь без тегов и всё? Как она там себя показывает с другими и тд уже второстепенно, поэтому может и были проблемы с дмд от такого
> Глора спокойно любое говно схватит и умножит.
В том архиве есть глора от не самого глупого тренировщика с форчка, не схватила и не умножила, выглядит как дора обычная. Есть ещё идеи про волшебный конфиг который поможет это сделать без тупо оверврайта весов напролом? Конфиг так и не скинул кстати, в котором уверен, что сработает
> Какая карта?
4090, батч 1 лора быстрее всего делается, потому что нету штрафа от чекпоинтинга и влезает в память
> Слои можно списком посмотреть через анализатор в кое или аналогичный скрипт, далее можно скриптом слайсить вот этим например
По конкретней, какой скрипт у кохьи ты называешь анализатором и что приблизительно вписываешь в конфиг слайсера?
Если они прямо совсем одинаковые, то лучше на них тоже учить, потом проще будет датасет для некст итерации пополнять, если не совсем, то хз даже, наверное нет
> Алсо может вы придумаете че еще можно прикрутить
Хл так и не поддерживается?
Из опыта на анимекале так всрато вытягиваются если тренишь в разрешении ниже 1024, им впринципе никогда жертвовать нельзя с хл, хз что конкретно ты там напердолил
>Из опыта на анимекале так всрато вытягиваются если тренишь в разрешении ниже 1024, им впринципе никогда жертвовать нельзя с хл, хз что конкретно ты там напердолил
Это точно не разрешение, потому что вообще не вылезаю за 768 пукселей и
>Хл так и не поддерживается?
Можешь переделать спокойно под хд, там плюс минус тот же код за исключением зависимостей для полторахи, но мне в этом нужды ноль, потому что вопервых полтораха меньше весит, вовторых у нее базовое разрешение ниже для работы (хотя это и не важно вообще, тут слоп на графике же ток найти надо а не консистентное изображение), втретьих она быстрее считается, вчетвертых такто можно хоть 128x128 по разрешению выставить, впятых все перечисленное позволяет на 3060 гонять 50+ батчей за итерацию
> вообще не вылезаю за 768 пукселей
Тогда и в генерациях не вылезай за них, оно же тюнится под это разрешение
И на хл оно тот же самый лр найдёт думаешь? Только не говори, что ты полтораху на серьёзе тренишь
Этот тред нагоняет на меня тоску. Да и вся доска. Что то получается, радостный заходишь, смотришь на то ,что местные делают, и сразу какой то разочарование от собственного позора.
А ещё флюкс медленно работает, и по ощущениям, он на озу генерит, иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия
А ещё флюкс медленно работает, и по ощущениям, он на озу генерит, иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия

>Тогда и в генерациях не вылезай за них, оно же тюнится под это разрешение
Но это не так работает in vivo епт. Это если ты просто тюнишь веса под картиночки с нулем аргументов на каком-нибудь одном разрешении и упором в альфу на оптиме который падает в локальный минимум и там умирает. Можно вообще тюнить attn-mlp или attn и сохранять юзкейс модели изначальный. Или конкертные слои, как в случае билоры. У меня же юзкейс вообще другой, я где-то на какойто итерации тестинга проебал аугментационные аргументы, тупа random_crop не выставил, вероятно потому что решил перенсти латенты в кеш, а латенты с вкл кропом не работают, а он если че:
Когда включено (true):
Обрезает изображение случайным образом при его масштабировании. Полезно для нестандартных разрешений.
Изображение случайно обрезается до меньшего размера, а затем подгоняется под размер разрешения (resolution=768x768).
Это изменяет расположение объектов и может переместить объект от центра к краям изображения.
Используется для снижения переобучения на "центральных" объектах.
Включить (true) — когда нужно увеличить разнообразие расположения объектов. Например, чтобы лица или объекты могли находиться не только в центре, но и в углах. Для контекстуальных изображений.
Выключить (false) — если важно сохранить центрированное расположение объектов (например, при обучении модели для портретов или аватаров, где лицо всегда должно быть в центре).
Алсо тот же эффект без вытянутых пропорций и мутантов на хайрезах наблюдается если использовать автообрезку по ебалу, если трен на лицо.
>И на хл оно тот же самый лр найдёт думаешь?
А архитектура не важна, сам принцип алгоритма это постоянно увеличивающаяся кривая лернинга, который каждую итерацию считает лосс. Кривую обучения можно поделить на разогрев, слоп обучения, плато накопления признаков и взрыв градиентов/переобучения, задача алгоритма визуально показать в каком промежутке находится комфортный слоп обучения. Обучать в целом можно и на лернингах плато, но наиболее эффективно судя по паперам это именно промежуток слопа.
>Только не говори, что ты полтораху на серьёзе тренишь
Нет, я не шиз.
Кстати там ссану выпустили в весах умеющих в 2к + тренинг лор с гайдом https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md https://github.com/NVlabs/Sana вот ее бы я потренил, в комфю и прочие уи еще не завезли поддержку кстати
>Как оно вообще в теории то должно успечь нормально пропечься, учитывая равномерное распределение таймстепов в стоке?
Жоско наказываешь за ошибки, задираешь лернинг юнета. Для еще более быстрой сходимости на тест можно использовать (IA)^3, который чуть ли не в 5 раз меньше требований к шагам имеет чем любой другой оптим. Алсо еще имеет значение сам оптим, адам на котором ты сидишь требует условно 1к шагов на эпоху, продиги требуют в половину меньше шагов для успешного обучения, есть еще более пизданутые по скорости схождения, но там в основном проблема с признаками и ошибка в определении локальных минимумов.
>больше ебли
Так наоборот меньше, дименшены и их отношение выставлять не надо, количество параметров управляется значением фактора.
>ты вообще без тегов чтоли хуяришь
Именно. У меня не миллионный датасет, я не треню ТЕ, устойчивые мультиконцепты это рандом в несовершенных архитектурах и поиск грааля и проще разные лоры тренить.
>ну это был полный забей на пони, когда я тестил, даже юнет онли лучше в тегами выглядел
Я паприколу киданул сложный калцепт нюши из смешариков (шарообразное нечто с глазами, сетка вообще не отдупляет че это) в пони и оно норм в целом по первым эпохам было.Так что не думаю что пони как-то разительно отличается от безтокенного обучения на базовых сдохлях. Я бы даже сказал что пони проще, т.к. сломаный текстовый енкодер позволяют втюнивать exaggerated дату, ну типа в обычносдхл сложно втюнить концепт гипербубсов размером с солнечную систему, на пони это как два пальца обоссать будет.
>а дальше нужно уже и те и разделение тегами
Я руководствуюсь тем что модель которая берется в качестве базы уже в курсе обо всех концептах датасета и модель сама все прекрасно понимает по входящим данным. То есть естетсвенно в какой-нибудь файнтюн на архитектуру смысла пихать порно нет, а в модель про порно нет смысла пихать архитектуру. VIT обрабатывает картиночку, TE уже и так полон концептов связанных с весами которые тюнятся, зачем чтото еще, если оно и так работает?
>у меня обычно просто лора лопается, если пикч мало и неадекватный лр выставлен, поэтому абсолютно противоположный экспириенс, может дедомодели от анимушных отличаются конечно
Мне кажется ты просто не юзаешь мокрые письки чтобы контролить генерализацию и конвергенцию получающейся модели на ранних этапах и ждешь у моря погоды дотренивая лору до состояния уголька, я в прошлом треде писал уже что модель уже буквально с первой эпохи обучена, но недостаток инфы не дает ей инферировать корректно, ты можешь ее пиздануть ломом и заставить выдавать корректное даже в полном недостатке признаков чтобы понять а туда ли ты обучаешь вообще. Да, это не даст тебе выложить лорочку на потеху другим пчеликам и без гайда на конкретное использование они пососут при использовании, но тебе нужен фактический тест, а не готовый продукт.
>Неиронично, я ещё не встречал ни одну хл модель, которая
Я про сохранение концептов базовой модели. Какой мне условный смысл тренить ебало еот чтобы модель делала мне ебало еот вместо контента который может модель? Никакого.
>напиши чтоли хоть фейкомыло какое, туда хоть скину лучше
[email protected]
>Разделять потом как разные стили?
Не юзать мультиконцепты стилей в одной лоре? Нейросети локальные пиздец тупые, мультиконцепты делают ток хуже, ликинги вот эти все.
>ты на огромном лр одну вжариваешь без тегов и всё?
Преимущественно да.
>Как она там себя показывает с другими и тд уже второстепенно
Ну тут смотря что с чем. Можно шизануться и одну лору на один слой аутпута натренить, а другую на соседний и бед не знать. Или тренить ток атеншены в одной лоре, а в другой ток прожекшены. Вариантов масса, но в целом да я больше 1 концептной лоры при генерации не юзаю. Ну или придумай мне юзкейс когда нужно юзать джве концептные лоры.
>поэтому может и были проблемы с дмд от такого
Не, там дмд агрился на TE, уже порешали вопросики.
>В том архиве есть глора от не самого глупого тренировщика с форчка, не схватила и не умножила, выглядит как дора обычная.
Я не смотрел состав, может там на атеншены тренились ток. В глоре целый парк адаптационных слоев, если ее фулово тренить она так все схватит что потом заебешься вилкой чистить.
>выглядит как дора обычная
Но дора это разложение весов, а не алгоритм адаптации.
>Есть ещё идеи про волшебный конфиг который поможет это сделать без тупо оверврайта весов напролом?
Атеншоны тренить?
>Конфиг так и не скинул кстати, в котором уверен, что сработает
Я ниче не скинул потому что у меня у самого нет идеального конфига, постоянно меняю всё.
>По конкретней, какой скрипт у кохьи ты называешь анализатором
Ну в kohyass есть отдельная вкладка верификации лоры, туда грузишь лору и он тебе послойно показывает состав. Отдельно должен быть скрипт.
>что приблизительно вписываешь в конфиг слайсера?
Ну если задача разделить конволюшены и все остальное, то для первого трейта будет
"1":
{
"whitelist": ["маска_конволюшенов_"],
"blacklist": []
}
а для второго
"2":
{
"whitelist": [],
"blacklist": ["маска_конволюшенов_"]
}
Во втором случае может потребоваться прописать в вайтлисте конкретно все маски нужных слоев за исключением конв, если тебе например фастфорвард слои не нужны.

Новичок, пробую подобное впервые. Поставил флюкс+ аматеур лора. Какой параметр я перекрутил, из за чего изображение такое?
выглядит просто как выкрученный на максимум вес, снизь весь лоры
>иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия
Минута на флюхкале это еще быстро, риктифайд флоу лижет и сосет по оптимизации. У меня на 3060 в ггуфах полторы минуты ген, в то время как ммдит и ммдитх сд 3.5 50 и 20 сек соотвтественно.

> У меня на 3060 в ггуфах полторы минуты ген,
Какой квант? Воркфлоу можешь скинуть, я на своей 4070 проверю?
>Какой квант?
q4
ну хз, шифт покрути, другой семплер поставь

Флюкс ЖЁСТКО унижает мою видеокарту. Так она только в киберпанке грелась.
У меня во время техпроцесса легко в 80 градусов уходит.
Притом, генерация видео или моделей так карту не греет.
Это же хорошо. Вот у меня не греется тк флукс просто не влазит в гпу.
чет у вас вендоры кал, у меня даже при обучении нет такой печки
Видяха ещё и в разгоне


Все, это рандом кроп выключенный был виноват. Мотайте на усики что рандомкроп повышает обобщающую способность и позволяет сохранить возможность генерации хайрезов даже на меньшем размере тренировки, пикрел натренен на 768.
Потренил кароче бигасп2, ну и как будто он даже лучше для не курируемого датасета, очень хорошая стабильность и консистенция.
Лернинг по д0 стоял на 1е-4 для продижов и сета в 602 картинки, 10 эпох, на первой эпохе уже полный стиль спиздило, к пятой эпохе локальный минимал лосс и дальше уже как будто и смысла тренить нет, разве что увеличивается фиксация на конкретных превалирующих элементах датасета.
У него правда есть небольшая проблема в том что чекпоинт малость перетренирован и поэтому жарит сам по себе, особенно с убыстрялками, а реки автора вообще 2-3 по цфг. В целом это обходится мокрописьками типа шринка, но я не о том. Натренилтя значит локр, и он поправил на какой-то процент пережарку модели. Если еще на порядок опустить д0 вероятно будет еще мягче.
Лернинг по д0 стоял на 1е-4 для продижов и сета в 602 картинки, 10 эпох, на первой эпохе уже полный стиль спиздило, к пятой эпохе локальный минимал лосс и дальше уже как будто и смысла тренить нет, разве что увеличивается фиксация на конкретных превалирующих элементах датасета.
У него правда есть небольшая проблема в том что чекпоинт малость перетренирован и поэтому жарит сам по себе, особенно с убыстрялками, а реки автора вообще 2-3 по цфг. В целом это обходится мокрописьками типа шринка, но я не о том. Натренилтя значит локр, и он поправил на какой-то процент пережарку модели. Если еще на порядок опустить д0 вероятно будет еще мягче.
Щас пробую на бигаспе потренить диагональный OFT, бофт мне зашел но скорость тренинга его меня просто разыбала - аналог 3000 шагов 6 часов ебал. А диагоналка ниче так, бодро. Не понял за что отвечает парам констрейнт, но выставил 16 как дименшен нетворк. Альфу тоже нипонятно то ли в 1 надо то ли выше, оставил как с бофт 1 пока что. Еще у диагоналки есть параметр рескейлед, но тож хуй знает че делает.
Алсо понишизы, какой там файнтюн будет лучше для реалистикотренинга?


Синенький лосс диагофта, оранжевенький локр прошлый
Считается конечно быстрее чем бофт, но все равно ебнешься как долго
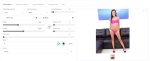
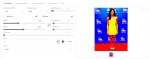
Ну че я могу сказать, дигофт который кофт изза аргумента уже на первой эпохе ебет и спизидл весь стиль с фоток и фигуру и немного ебало модели.
После, до. Почему до жарит? Потому что бигасп жарит, ебаное говно в виде вебуя бесоебит и вообще алайнер срет тоже.




эпохи 2 3 4 5
Хуй пойми нахуя тренить выше первой эпохи получается, мб на хайрезе там ебало консистентнее будет я хз






тест клозапа
8 эпоха, 1 эпоха, без диагофта
Ну я хуй знает кароч, да похожесть с эпохами бустится но как для стиля достаточно одной эпохи совершенно точно

Судя по графику тензорборды локальный минимум лосса был на 800 шаге, ближайшая эпоха это 755 т.е. 5, ну да в принципе похоже на модельку (напомню что на ебало я не тренировал, просто определяю где там лучшая точка схождения)
Кароче бофт и дофт/кофт/хуефт ван лав, надо долбить комфидева чтобы добавил поддержку, вебуем пользоваться невозможно нахуй
Хотя можно теоретически сконвертить офт в ликорис, надо попробовать

>в принципе похоже
Занизил ожидания называется, схожесть почти эталонная. Но 5 эпоха.
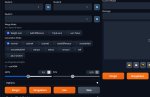

Где есть информация о том в каком режиме надо мерджить эпохи? И как вообще может получится оверфит при обычном сложении весов? Я думал вся информация не уместившаяся в количество параметров сетки просто улетает.
>Где есть информация о том в каком режиме надо мерджить эпохи?
Из всего списка хороший вариант разве что только трейндифренс, ну это лично по моему многолетнему опыту, но это больше для сложения чекпоинтов фуловых.
>И как вообще может получится оверфит при обычном сложении весов?
Хз, ни разу оверфита не получал. Но есть момент, что ты, если имеешь доступ к слоям, можешь удалить ненужные которые могут сильнее других влияет на ген, ну условно ff_net слои в инпут/аутпут блоках могут ужаривать лору итоговую если смешать допустим дистиллят дмд с обычнолорой.
>Я думал вся информация не уместившаяся в количество параметров сетки просто улетает.
Если вейтед сум или вычитание - улетает.
Алсо обычное сложение/вычитание сосет потому что не учитывает матанские связи внутри слоев. Наверно самый адекватный метод мерджа весов лор это сингулярное разложение. Но оно долго считается достаточно. Гугли Singular Value Decomposition (SVD).
Проиграл с брухли.
> Жоско наказываешь за ошибки, задираешь лернинг юнета
Получаешь нуба впред 1.0 весь в артефактах, лол, они на скоростях лор хуярили ведь 1е-4 и с батчем претрейна 1024
> Для еще более быстрой сходимости на тест можно использовать (IA)^3, который чуть ли не в 5 раз меньше требований к шагам имеет чем любой другой оптим
Но это не оптим, да и он тотал юзлесс гарбейдж вообще из тестов, даже на собственной модели с которой тренилось
> Алсо еще имеет значение сам оптим, адам на котором ты сидишь требует условно 1к шагов на эпоху, продиги требуют в половину меньше шагов для успешного обучения, есть еще более пизданутые по скорости схождения, но там в основном проблема с признаками и ошибка в определении локальных минимумов.
Да что ты на эти лоссы дрочишь так, они нихуя глобально с меньше чем 100к степов не покажут, в прошлом вроде треде показательный скрин был насколько похуй на него
> Так наоборот меньше, дименшены и их отношение выставлять не надо, количество параметров управляется значением фактора.
Там лр дефолтный не работал
> Именно. У меня не миллионный датасет, я не треню ТЕ, устойчивые мультиконцепты это рандом в несовершенных архитектурах и поиск грааля и проще разные лоры тренить.
С таким подходом и базовые модели бы не появились, лора для всего, ембрейс 1.5
> Я паприколу киданул сложный калцепт нюши из смешариков (шарообразное нечто с глазами, сетка вообще не отдупляет че это) в пони и оно норм в целом по первым эпохам было.Так что не думаю что пони как-то разительно отличается от безтокенного обучения на базовых сдохлях. Я бы даже сказал что пони проще, т.к. сломаный текстовый енкодер позволяют втюнивать exaggerated дату, ну типа в обычносдхл сложно втюнить концепт гипербубсов размером с солнечную систему, на пони это как два пальца обоссать будет.
Пони это как раз для фриков чекпоинт, он любит такое, я уже вроде говорил, что эстетичными стилями там вообще не пахнет
> Я руководствуюсь тем что модель которая берется в качестве базы уже в курсе обо всех концептах датасета и модель сама все прекрасно понимает по входящим данным. То есть естетсвенно в какой-нибудь файнтюн на архитектуру смысла пихать порно нет, а в модель про порно нет смысла пихать архитектуру. VIT обрабатывает картиночку, TE уже и так полон концептов связанных с весами которые тюнятся, зачем чтото еще, если оно и так работает?
Ни в одной аниме модели нету толком нейрокаловых стилей выпуканных грифтерами за год существовнаия наи, которые выглядят иногда довольно пиздато и уж точно отличаются от дефолтного хл лука очень сильно, чтобы их не делать по одной лоре энкодер придётся включить, чтобы хоть как то разделять. Пони тоже, если уж и обучать, то придётся с энкодером, потому что оттуда выпилены базовые маняме калцепты и добавлена куча gpo
> Мне кажется ты просто не юзаешь мокрые письки чтобы контролить генерализацию и конвергенцию получающейся модели на ранних этапах
Что например, альфу чтоли? Или вот эти махинации с тренируемыми частями? Я в целом не ебу какие части должны за что отвечать, если распишешь вкрацте конечно только
> пиздануть ломом и заставить выдавать корректное даже в полном недостатке признаков чтобы понять а туда ли ты обучаешь вообще
С 1 эпохи то это да, оно действительно видно должно быть, если датасет консистентный, по крайней мере на крупных лорах, но пиздить ломом врятли покажет что то полезное, помимо рандомных мутантов обычно, сложно переносимость стиля так оценивать
> Я про сохранение концептов базовой модели. Какой мне условный смысл тренить ебало еот чтобы модель делала мне ебало еот вместо контента который может модель?
А я опять напишу, их нереально оверрайднуть, это реально надо постараться и вжарить энкодер на 1е-2 в энкодер онли тренировке или типо того и не улететь при этом в нан, тогда действительно начнёт не слушаться, с примерно правильной лорой просто должно ебало поменяться, даже поза не смениться или стиль, ну если проводить аналогию на чара для манямекала
> Не юзать мультиконцепты стилей в одной лоре? Нейросети локальные пиздец тупые, мультиконцепты делают ток хуже, ликинги вот эти все.
Но хочется в одной всё иметь, потом через компел комбинить, в рефордже до сих пор нету, только кумфи нормально может управлять снижением весами
> придумай мне юзкейс когда нужно юзать джве концептные лоры
Концептные ноль кейсов, чар+стиль самый распространённый случай например, вот ещё какие то дмд появились теперь
> Я не смотрел состав, может там на атеншены тренились ток. В глоре целый парк адаптационных слоев, если ее фулово тренить она так все схватит что потом заебешься вилкой чистить.
Не, там не запариваясь с частями тренилось просто на алгоритмах
> Но дора это разложение весов, а не алгоритм адаптации.
Ладно, локон с дорой поверх
> Атеншоны тренить?
С дефолтным фулл пресетом типо не тренятся или смысл именно их онли?
> Я ниче не скинул потому что у меня у самого нет идеального конфига, постоянно меняю всё.
Короче датасет я тебе прислал, если в гриде из того зипа получится уравнять твою попытку с antifreeze-2 или autismbase_v8 то это считай успех
> ["маска_конволюшенов_"]
Где весь список то этого посмотреть? Вроде у кохака в ликорисе был, но в доках нихуя не могу найти
Ну здорово конечно, но выглядит как костыль и теги подосрут, которые есть, а трит обрезался
> Но это не так работает
Да нет, именно так, если не пердолиться со слоями и кропами
> А архитектура не важна, сам принцип алгоритма это постоянно увеличивающаяся кривая лернинга, который каждую итерацию считает лосс. Кривую обучения можно поделить на разогрев, слоп обучения, плато накопления признаков и взрыв градиентов/переобучения, задача алгоритма визуально показать в каком промежутке находится комфортный слоп обучения. Обучать в целом можно и на лернингах плато, но наиболее эффективно судя по паперам это именно промежуток слопа
Как не важна, если даже с впредом будет другой лр, с хл тем более. Почему вообще с разными сидами разные лр выдаёт?
> Кстати там ссану выпустили в весах умеющих в 2к + тренинг лор с гайдом https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md https://github.com/NVlabs/Sana вот ее бы я потренил, в комфю и прочие уи еще не завезли поддержку кстати
Хуита из тех примеров что я видел, 4к мыльных и уёбищный вае, даже тут вон https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/Sana.jpg оно может и быстрее дохуя, но толку как то маловато от этого
> риктифайд флоу
Падажжи, они разве не обе уже ректифаед флоу модели? Ммдит это же просто архитектура, а флоу что то типо вперд таргета, не?

>Получаешь нуба впред 1.0 весь в артефактах, лол, они на скоростях лор хуярили ведь 1е-4 и с батчем претрейна 1024
Ты не учитываешь что 1е-4 это для десятимилионного датасета который они собрали. Твой ретрен весов на большем лр ничего глобально не изменит.
>Но это не оптим
Опечатка
>да и он тотал юзлесс гарбейдж вообще из тестов
Что с тобой не так то, у тебя все гарбаж и юзлес получается
>Да что ты на эти лоссы дрочишь так, они нихуя глобально с меньше чем 100к степов не покажут
Потому что мне надо максимум за минимум времени
>в прошлом вроде треде показательный скрин был насколько похуй на него
Че за скрин
>Там лр дефолтный не работал
В смысле не работал
>С таким подходом и базовые модели бы не появились, лора для всего, ембрейс 1.5
Не очень объективно сравнивать триллиардные датасеты для базовых архитектурных моделей с нашими микродатасетами на концепт.
> я уже вроде говорил, что эстетичными стилями там вообще не пахнет
А причем тут это если я про безтокенный тюн весов.
>чтобы их не делать по одной лоре энкодер придётся включить, чтобы хоть как то разделять.
Кароче проблемы мультиконцептов
>Пони тоже, если уж и обучать, то придётся с энкодером, потому что оттуда выпилены базовые маняме калцепты и добавлена куча gpo
Там не выпилены, там енкодер поломался от задранного лр, сам астралите говорил, такто маняме можно на пони делать.
>Что например, альфу чтоли? Или вот эти махинации с тренируемыми частями?
Да много разного есть, можно постфактум лору оттюнить софтово, можно изначально тестовые прогоны на конкретные слои тюнить и смотреть результат.
>Я в целом не ебу какие части должны за что отвечать, если распишешь вкрацте конечно только
В одном из след постов покажу пару простых кейсов как чекать хорошо ты лору натрениваешь или нет.
>но пиздить ломом врятли покажет что то полезное, помимо рандомных мутантов обычно, сложно переносимость стиля так оценивать
У меня практически все лоры являются фактическим недотреном в дефолтном использовании на некурируемом датасете, что не мешает их перетрахивать постфактум и получать консистентный стиль который был в датасете.
>их нереально оверрайднуть, это реально надо постараться и вжарить энкодер на 1е-2 в энкодер онли тренировке или типо того и не улететь при этом в нан, тогда действительно начнёт не слушаться, с примерно правильной лорой просто должно ебало поменяться, даже поза не смениться или стиль
Спокойно можно оверрайднуть через дору и будет выдавать чисто датасетовые пикчи с полным игнором промта, достаточно на шедулед фри выставит 10 по лр юнету и 1 по текстенкодеру.
>Но хочется в одной всё иметь, потом через компел комбинить,
Ну я губу закатал например и ничего, нормально. Опять же для трушного эффекта разделения концептов есть безумное умение в виде трена одного калцепта на один слой выходной, а второго на другой, потом их соединяешь и получаешь мутанта который в целом задачу то выполняет но много лишних телодвижений, в том числе трен отдельного текстенкодера.
>в рефордже до сих пор нету, только кумфи нормально может управлять снижением весами
Как это нету? Там же есть мокрописька который позволяет те и юнет отдельно крутить разве нет?
>чар+стиль самый распространённый случай например
То есть условно ты берешь смешарика и хочешь его в стиле евангелиона генерить? Так можно сингулярным разложением две отдельные лоры соединить и будет тебе тот же эффект но без дрочки концептов в одной лоре.
>вот ещё какие то дмд появились теперь
Дмд дистиллят векторов базовой модели по таймстепам LCM, там совершенно плевать с какими лорами и моделями пользоваться им. Функция у него другая.
>С дефолтным фулл пресетом типо не тренятся или смысл именно их онли?
С фулом у тебя фул слои вообще все и тренятся, а если ты тренишь ток атеншен слои то остальное не участвует.
>Где весь список то этого посмотреть?
Гуй кохи запускаешь, в утилитис (вроде) лора верифай вкладка, если лора содержит читаемые слои то все модули тебе покажет. Если непонял где это, то щас попробую запустить кою, но я питон откатывал мб и не запустится щас.
>но выглядит как костыль и теги подосрут
Не, я ж треню на вписывание в модель, а не на перезапись, там хоть как крути будет теперь выдавать с оглядкой на все возможности оригинальной модели.
>Да нет, именно так, если не пердолиться со слоями и кропами
Если не пердолиться, то нахуй оно и нинужно.
>Как не важна, если даже с впредом будет другой лр, с хл тем более.
Потому что матан, представь что у тебя датасет из Nк картинок, это переводится в условное пространство вероятностей, где для этого пространства вероятностей существует эффективный лернинг рейт в промежутке от и до.
>Почему вообще с разными сидами разные лр выдаёт?
Имеешь в виду где тебе в командной строке пишется? Так оно не работает как надо, мне лень допиливать чтобы оно брало среднее значение слопа если и так по фигуре можно потыкаться.
>Хуита из тех примеров что я видел, 4к мыльных и уёбищный вае, даже тут вон https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/Sana.jpg
Пиздец ты токсик. Давай еще наедь на дефолт говногены сдхл с мутантами.
>оно может и быстрее дохуя, но толку как то маловато от этого
На ноль поделил, скорость это важнейшее такто в генерации, остальное можно допилить.
> они разве не обе уже ректифаед флоу модели? Ммдит это же просто архитектура, а флоу что то типо вперд таргета, не?
Не, 3.5 не флоу, 3.5 мультимодал трансформерсы. Алсо изза того что 3.5 не флоукал оно может работать без т5 как сдохля, а флюх не может так.
>Если непонял где это, то щас попробую запустить кою, но я питон откатывал мб и не запустится щас.
Да, хуй мне надо питон пердолить. Кароче в kohya_ss\kohya_gui лежит скрипт verify_lora_gui.py , вот он занимается показом модулей в лоре.
>скрипт verify_lora_gui.py , вот он занимается показом модулей в лоре.
То же самое плагин https://marketplace.visualstudio.com/items?itemName=zhoukz.safetensors для вскода показывает.
> random_crop
Это что там у тебя за кейс для такой штуки? Для ухватывания совсем абстрактного стиля или шлифовки на грани анкондишнал, в остальных же случаях возникнут проблемы с соответствием промта и содержимого кропа.
> Полезно для нестандартных разрешений.
Ерунда вообще
XL вообще может пережить некоторую тренировку с разрешении пониже, но всеравно это будет сказываться потом.
> Кривую обучения можно поделить на разогрев, слоп обучения, плато накопления признаков и взрыв градиентов/переобучения
В общем случае - да, но в зависимости от того что уже знает модель и насколько отличается датасет от условного среднего по тем же кондишнам - эти автоалгоритмы могут вообще порваться.
> наиболее эффективно судя по паперам это именно промежуток слопа
Там действительно происходит наибольшее изменения и "усвоение", но сопровождается это множеством побочек, которые потом необходимо сглаживать, и есть еще нюансы.
> Именно.
> я не треню ТЕ
Если такое с мелким датасетом и на что-то конкретное, а не особый твикер или стилизатор - пиздец. Капшны нужны не для того чтобы те тренить, если что.
> про сохранение концептов базовой модели
Вот как раз анкондишнал все распидарасит нахер и отклик на них поломается, исключения есть но это крайне специфичное.
Слишком долгая и душная у вас беседа, может все это оправдано и просто вырываю из контекста, тогда сорян. Но со стороны выглядит той еще дичью.
Оно выглядит как потеря когеретности, на пикчах беда с пропорциями и фейлы даже в простых линиях.
Если есть возможность - лучше сразу тренить нормально. Для мерджей лучше взвешанная сумма и cosineA, если пытаешься получить среднее между двумя. Можешь попробовать упороться и замержить льва с жопой носорога, а потом это закинуть на тренировку с пониженным лр и фиксированным оптимайзером, часто подобное срабатывает.
> как вообще может получится оверфит при обычном сложении весов?
Посмотри как устроены блоки в диффузии и вспомни что оно в фп16. С неудачными комбинациями значений на краях диапазона получишь поломку, да и чисто по результатам косинус лучше срабатывает.
> хороший вариант разве что только трейндифренс
Это если хочешь добавить фичи одного (слабо) тренированного чекпоинта (зная его базу, которую будешь вычитать) к другому на примерно той же основе. В рамках мерджа разных эпох модели неприменимо.
> Наверно самый адекватный метод мерджа весов лор
Вмердживать в основные веса, проводить с ними манипуляции, а потом делать извлечение и соснуть из-за несовершенства алгоритмов, лучше вообще никогда лоры не мерджить.
> Singular Value Decomposition
Вот это интересно
> 1е-4 и с батчем претрейна 1024
На самом деле для такого батча это не то чтобы плохо. Но в целом, это слишком много для тренировки чекпоинта, который уже знает то что они обучают, такой батч тоже больше оптимального для dit ибо после претрейна там лучший результат достигается при меньших батчах но с правильной группировкой пикч для них.
У них там в целом хватало проебов.
> для десятимилионного датасета
Оно коррелирует с размером датасета чуть меньше чем никак.
> Потому что мне надо максимум за минимум времени
Зачем? Натренить лору в любом случае быстро и легко. Если хочешь в нормальное обучение - там быстро не получится, что полные веса, что всякие хитровыебанные твикеры и подобное.
> безтокенный тюн весов
Покажи пример результатов этого чуда и опиши что именно там тренишь.
>Это что там у тебя за кейс для такой штуки?
Чтобы не привязывалось к 768.
>в остальных же случаях возникнут проблемы с соответствием промта и содержимого кропа.
Спорно, но не, вообще мимо. Ни разу не было на тестовых прогонах с кропом даже на первой эпохе, а вот без кропа лезет какая-то хуйня. Полные лоры с кропом работают как должны.
>Ерунда вообще
>XL вообще может пережить некоторую тренировку с разрешении пониже, но всеравно это будет сказываться потом.
Так кто ж спорит, ток это разрешение пониже поднасрет на разрешении повыше.
>Оно выглядит как потеря когеретности, на пикчах беда с пропорциями и фейлы даже в простых линиях.
Ой не выдумывай, особенно с потери когерентности кекнул. Оно выглядит как обычное селфи с дисторсией объектива, ты че натвис не гонял? Погоняй, там полдатасета это селфи с онлика где бабцы фотались голыми под экстремальными углами. А баба сама по себе длинная и худая по датасету. Я понимаю что надо приебаться и как-то оправдать "кропы нинужно", но лучше просто прими как факт что это норма и не ищи сусликов там где их нет. Могу еще погенить без токена селфи всякое, хз как еще показать в интернете что ктото не прав.
>но в зависимости от того что уже знает модель и насколько отличается датасет от условного среднего по тем же кондишнам
Так для этого и берем датасет без тегирования и базовую модель, которая по дефолту знает много общего. Но кондишены и не важны на самом деле, мы переводим картиночки в абстрактный манямирок признаков и наша задача выбрать лр который будет эффективно эти признаки хватать. Если ты о кондишенах заботишься, то тебе валидейшен лосс нужен, где промежуточные тренировки будут сравниваться сходимостью с частью датасета и выводить курву.
>Если такое с мелким датасетом и на что-то конкретное, а не особый твикер или стилизатор - пиздец.
Все нормально, те нинужны. Прими как факт.
>Вот как раз анкондишнал все распидарасит нахер и отклик на них поломается
Нет.
>Слишком долгая и душная у вас беседа, может все это оправдано и просто вырываю из контекста, тогда сорян. Но со стороны выглядит той еще дичью.
Ну и зачем ты тогда влетел в нашу беседу?
>Это если хочешь добавить фичи одного (слабо) тренированного чекпоинта (зная его базу, которую будешь вычитать) к другому на примерно той же основе. В рамках мерджа разных эпох модели неприменимо.
Трейндифренс сам по себе добавляет мягенько, что возможно потребует еще пару итераций трейндифренса, это тебе не ебка вейтедсумовая, которой похуй уполовинила и готово.
>Вмердживать в основные веса, проводить с ними манипуляции, а потом делать извлечение и соснуть из-за несовершенства алгоритмов, лучше вообще никогда лоры не мерджить.
Я вот не понимаю твоей радикальности, влетел и разбрасываешь "этанинужно" "этогавнокал" "ниработаит", как будто существует эталон какой-то. Уже и лоры нельзя мерджить тыскозал лол, хотя есть магнитуд пруне, который стабилизирует смешивание лор, особенно при разложении. Вот смысл твоего поста в принципе? Ты думаешь кто-то как-то поменяет свои действия от советов, о которых не просили или что? Зачилься кароч, ничто не истина - все дозволено.
>Вот это интересно
Учитывая что ты раздаешь советики и ультимативен в своих тезисах, но не в курсе про ротейшен/свд, всё ясно.
>Оно коррелирует с размером датасета чуть меньше чем никак.
Ну вот опять. Ок, чатжпт, есть ли корреляция: Да, размер датасета коррелирует с выбором learning rate (LR), но связь не является строго линейной.
>Зачем?
Юзкейс такой.
>Если хочешь в нормальное обучение - там быстро не получится, что полные веса, что всякие хитровыебанные твикеры и подобное.
Держи в курсе.
>Покажи пример результатов этого чуда и опиши что именно там тренишь.
Еот тренил без токенов чтобы делать нюдесы с гейпопиздой, показывать не буду тк по гену найдешь ее вк.
Если че за пассивную агрессивность извиняй, я хз как отвечать по другому на такого плана посты.
tldr: Никому не рекомендую серьезно воспринимать высказывания этого вонаби умника.
> Ну и зачем ты тогда влетел в нашу беседу?
Думал что в треде не все потеряно и остались адекваты, а не одни поехи. Или даже надежда была что есть кто-то продвинутый да толковый кого не знаю и так.
> Я вот не понимаю твоей радикальности, влетел и разбрасываешь
Уберечь от ошибок и очередной пробежки по граблям, в первую очередь тех, кто зашел сюда за знаниями или с вопросами.
Хотел было подробно ответить, а там по каждому пункту бредни. Ну буквально везде не прав или глупейшие ошибки, оправдываемые неуместным бросанием терминов. Ухватил какие-то верха не понимая устройства и применимости своих суждений.
> я хз как отвечать по другому на такого плана посты
В дурку тебе пора, а не на посты отвечать. Натренил лоботомирующую лору на еот, посмотрел курсы для чайников и так преисполнился самоуверенностью. Хотя ультимативный дилетант, что делает ложные выводы на неверном обобщении своего скудного опыта.
>Капшны нужны не для того чтобы те тренить, если что.
Вот интересная мысль, если посмотреть на новую txt2vid от гугла, то там явно ллмка промт разворачивает. Учитывая что она так хороша, там наверное жирнющий подробный капшн, на котором и учили саму модель.
Когда у диффузии есть больше инфы и меньше неопределенности, у нее остается больше ресурсов на то чтобы сконцентрироваться на более высоких абстракциях, получить лучшее качество, так как лосс не ебет по хуйне, которую модель физически не способна предсказать без gan-головы.
>Хотел было подробно ответить, а там по каждому пункту бредни.
Мне расскажи, а то моей компетенции пока не хватает чтобы понять кто из вас неправ...
>подорвался что его на хуй послали в вежливой форме с его манямнением основанным буквально ни на чем и ряяя нинужно
@
>сгорел и перешел на прямые оскорбления
Ты давай иди гугли че такое свд лучше, петух ебаный, а то так и будешь "делойти как я скозал а иначе врети неработает уииихрююю" в тред постить и жопу зашивать потом при первом же сопротивлении твоему ультимативному пиздежу.
> а то моей компетенции пока не хватает чтобы понять кто из вас неправ...
Да, оч сложно понять конечно... Когда тебя начинают учить как делать что-то с явным посылом на владение Истиной при многообразии вариантов, то это редфлаг ебаной чсвшной преисполнившейся помойки. Не работает когда очевидно известен лучший вариант, а эта хуйлуша не только не знает лучшего варианта (в противном случае лучший вариант был бы предоставлен, а не соплями по монитору бы свою попуки про нинужность чего-либо размазывал), а еще и отрицает всё, с чем не сталкивалась.
Ну не знаю, не знаю... а скажи-ка мне свое мнение по поводу существования локальных минимумов? Или вы оба долбаеба начнете доказывать что они существуют?
Ты тоже далбаеб получается.
Нет, к сожалению, тебе придется принести пруфы их существования. Но что-то мне подсказывает, что ты дашь заднюю сразу как только увидишь что каждый шаг оптимизатора почти ортогонален предыдущему, что как бы немного исключает движение в строну минимума. Геометрически.
> Нет, к сожалению, тебе придется принести пруфы их существования.
Концепция локальных минимумов в нобелевке у создателей концепции нейросеток это база, чел...
Опровергаемая парой простых экспериментов, чел...
>Короче датасет я тебе прислал, если в гриде из того зипа получится уравнять твою попытку с antifreeze-2 или autismbase_v8 то это считай успех
А промт какой епт? Скортеги юзать не юзать? Какие настройки гена у картиночек были в примере?
еще ублюдский мердж в виде аутизма качать ну пиздец
Пиши в спортлото нобелевский комитет, похоже они ошиблись и нобелевку надо было дать тебе.
Да можешь и ты написать. Я тебе даже прямо показал на что можно посмотреть и куда копать. Мне не жалко.
А в науке и после нобелевок как бы дохуя нюансов и корректировок находили.


>Короче датасет я тебе прислал
>все версии из архива скорее всего с таким датасетом и тренились,
>скорее всего
>датасет полностью другой стиль если сравнивать с то к чему стремишься
бля это прикол чтоли? то есть ты вообще не в курсе какой на самом деле датасет был? я конечно уже получил на первых эпохах копию именно датасетовской рисовки, но это же вообще разные вещи стилистически
аинанасы подскажите, для дримбута флюкса только базовая дев модель подходит или можно на кастомных тренить?
А че есть какието нормальные тюны чтоли?
хз
интересуюсь, чтобы зря время не тратить на хуйню
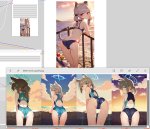



Кароче понятия не имею какие настройки гена и какой промтинг, и вообще не шарю за онимекалы и че там надо писать, но вот тестовый прогон на понях и пара шотов которые мне нравятся.
Но вообще строго повторяясь датасетовые пикчи совершенно не то, что "антифриз", у них и желтушный фильтр везде и сорт оф рваная рисовка и аутлайны в тон, и глитчи всякие, И ебла характерные, и лимитед палитра, и блюра навалено. Кароче епты бля чето типа такого гена как пик 4.

>Кароче епты бля чето типа такого гена как пик 4.
Точнее вот так. Слева то что в датасете, справа ген.
> Ты не учитываешь что 1е-4 это для десятимилионного датасета который они собрали. Твой ретрен весов на большем лр ничего глобально не изменит.
Мой то не изменит, я скорее к тому что такой лр с батчем для эстетик трена поверх файнтюна это бред какой то, вся работа по усваиванию уже была сделана люстрой
> Че за скрин
> В смысле не работал
Ну в прямом, приходилось тестировать другие, чтобы тренилось
> Не очень объективно сравнивать триллиардные датасеты для базовых архитектурных моделей с нашими микродатасетами на концепт.
Уже вроде и про это писал, одну хуйню любую вжарить юнет онли не проблема, но если рассчитывать на лору побольше, или в модели чего то нет со стороны энкодера, то придется включить
> Кароче проблемы мультиконцептов
Ну забей, если не хочешь вылезать дальше вжаривания одной штуки в каждую лору, после адуха это комбинить конечно
> Там не выпилены, там енкодер поломался от задранного лр, сам астралите говорил, такто маняме можно на пони делать.
Да можно то можно, но wariza, dogeza, cheek pinching, bandaid on pussy, doko? Vtumor или 2hoes помимо Реймухи? И это только вершина айсберга
> Опять же для трушного эффекта разделения концептов есть безумное умение в виде трена одного калцепта на один слой выходной, а второго на другой, потом их соединяешь и получаешь мутанта который в целом задачу то выполняет но много лишних телодвижений
Звучит слишком хорошо, если бы так работало что тогда помешало бы просто делать базовые модели и запихивать по слоям классы с подклассами? На деле один-пару слоёв всегда оверрайдится отвечающих за стиль или концепт, остальные че то там чуть сдвигаются
> Как это нету? Там же есть мокрописька который позволяет те и юнет отдельно крутить разве нет?
<lora::unet=1:te=1>? Я не про это вот тут глянь https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb?tab=readme-ov-file#down-weighting могу грид найти отлично демонстрирующий какая хуйня в стоке даже на кумфи, точнее не грид а примеры одного сида, я не стал разбираться как с кумфи пилить гриды просто
> То есть условно ты берешь смешарика и хочешь его в стиле евангелиона генерить? Так можно сингулярным разложением две отдельные лоры соединить и будет тебе тот же эффект но без дрочки концептов в одной лоре.
Ну типо, есть примеры такого сингулярного разложения где то? Сукалол проорал пока читал это название
> Гуй кохи запускаешь, в утилитис (вроде) лора верифай вкладка, если лора содержит читаемые слои то все модули тебе покажет. Если непонял где это, то щас попробую запустить кою, но я питон откатывал мб и не запустится щас.
Да нашёл уже, что тут конволюшены lora_unet_output_blocks_2_2_conv.lora_down.weight,(16-1280-3-3) это?
> Потому что матан, представь что у тебя датасет из Nк картинок, это переводится в условное пространство вероятностей, где для этого пространства вероятностей существует эффективный лернинг рейт в промежутке от и до
> Имеешь в виду где тебе в командной строке пишется? Так оно не работает как надо, мне лень допиливать чтобы оно брало среднее значение слопа если и так по фигуре можно потыкаться.
И всегда этот матан выдаёт разное оптимальное значение, судя по тому что ты тестил и выкладывал выше, ну так же не бывает
> Пиздец ты токсик. Давай еще наедь на дефолт говногены сдхл с мутантами.
Не стану, хл в стоке хоть и был пиздец каким мыльным и ненасыщенным гаммой, но уж мутантов там точно не было или артефактов, да и в долгосроке архитектура оказалась норм, а тут пикчи бувально как после х4 гана. Рано конечно пока говорить по превью, но сота аниме модель наив3 на хл выглядит лучше, чем их высер недотрененной пока в4 стилистически, неизвестно пока как тот франкеншейн в полной версии правда будет себя показывать, но превью выглядит где то между 1.5 и флюксом, лол, вае ведь от него тоже
> Не, 3.5 не флоу, 3.5 мультимодал трансформерсы. Алсо изза того что 3.5 не флоукал оно может работать без т5 как сдохля, а флюх не может так.
Да как не флоу то ёбаный рот блять https://huggingface.co/stabilityai/stable-diffusion-3.5-large/blob/main/scheduler/scheduler_config.json то что они не упомянули в превью не значит, что там он растворился волшебным образом, картинка в сд3 и 3.5 одинаковая та вообще с архитектурой. У сд3 репа не диффузер формата а говна, но если разобрать, там небось такой же конфиг будет
> На самом деле для такого батча это не то чтобы плохо. Но в целом, это слишком много для тренировки чекпоинта, который уже знает то что они обучают, такой батч тоже больше оптимального для dit ибо после претрейна там лучший результат достигается при меньших батчах но с правильной группировкой пикч для них
Такой батч сам по себе плох, они не тренят с шума или весов 1.0, это шлифование файнтюна. Им или стратегию сменить в сторону лоры для люстры (чем оно в конце концов по сути и оказалось), но в полных весах ради впреда, либо тюнить с голой основы, учитывая что датасет с компьютом позволяли
> А промт какой епт? Скортеги юзать не юзать? Какие настройки гена у картиночек были в примере?
Прямо в гриде и есть данные этого аутлеер примера для генерализации, перетащи в рефордж
> бля это прикол чтоли? то есть ты вообще не в курсе какой на самом деле датасет был?
Я же писал, что глора и дора тренились вообще разными людьми с форча, не могу же я быть вкурсе про датасет каждого, но тренить с таким было бы самым разумным выбором из за высокой консистентности стиля и отсутствия нейрокала, больше прямо похожих просто нету, ну может ещё ватермарки почистить только
Хрень, на том моём гриде кстати только 1 и 4 "нормальные" остальные андердоги, прикол на 1гёрл получить, с этим любая из них справится, а конкретно тот аутлеер найденный генерализовать нормально, как на 1 и 4
> Да нашёл уже, что тут конволюшены lora_unet_output_blocks_2_2_conv.lora_down.weight,(16-1280-3-3) это?
Я с хл никогда не рылся в слоях лоры, но оказывается там всего 4 конволюшен слоя тренится, в отличии от той же полторахи, там их точно было дохуя, интересно почему так
Кстати не просто хрень, а тотал хрень, если выдаёт как на 2 и 3, но мб не шаришь и запромптил еще криво
С горелой жопой говорить что кто-то порвался - нет более рофлового зрелища.
Ну давай разберем по частям все тобою написанное
> Чтобы не привязывалось к 768.
Использование рандомкропа никак не поменяет разрешение тренировки, оно просто кропнет пикчу вцелевое разрешение и именно что модель привяжется к 768. С учетом того что это будет порождать проблемы несоответствия изображения и промта - оче плохая идея и годно для редких специфичных кейсов.
> Спорно, но не, вообще мимо.
Судя по запощенным пикчам - прямо в цель.
> Ни разу не было на тестовых прогонах с кропом
Кроп не меняет разрешение тренировки
> даже на первой эпохе
На первой эпохе эффект будет меньше всего заметен, чем дальше тем хуже.
> просто прими как факт что это норма
> РРРЕЕЕ ЯСКОЗАЛ!
Словил синдром утенка, получив первый успех в самом днищенском из всех возможных вариантов тренировки, и теперь ведет проповеди.
> Ой не выдумывай
Что тут выдумывать если у нее ребра подмышкой, трусы двоятся, на плече 2 ключицы и складки, левый плечевой сустав на первой пикче исчез, телефон кривой, мелкий огрызок бека на второй 3 раза прыгает, ебало вытянуто по высоте, плечевые кости со страшным загибом. Именно так проявляется потеря когерентности, ужасающая хтонь.
Ну ты погенери хороших, заебешься роллить.
> для этого и берем датасет без тегирования
Это здесь никаким боком и ни к чему хорошему кроме лоботомии и потере контроля не приведет.
> и базовую модель, которая по дефолту знает много общего
> знает много общего
Жопой прочел, речь не о наличии общих знаний, которые в базовой XL посредственны, а об отличии конкретного материала обучения от того что выдает модель по тем же кондишнам, и в целом способности их понимать. Дополнительно накладывается эффект от перегона промта в эмбединги клипа.
> кондишены и не важны на самом деле
Сколько раз повторил, но ни разу ни единого аргумента в пользу этого. А их и быть не может.
> кондишены и не важны на самом деле, мы переводим картиночки в абстрактный манямирок признаков и наша задача выбрать лр который будет эффективно эти признаки хватать
Это бессвязный бред. Все к чему приведет такая тренировка без кондишнов - к полной перестройке модели на выдачу всратых вариаций датасета и полной потери нормальной работоспособности. В качестве всратого костыля для лоуэфортного получения слопа, напоминающего еот - подойдет, но не более.
> Все нормально, те нинужны. Прими как факт.
Ну опять это
> ррееее нинужны моя первая еотолора натренилась без них и я верю
а ведь есть нормальные исследования влияния анкоднишнал семплов в ходе тренировки. Но ты сначала пруфы своих заявлений про ненужность притащи.
> Трейндифренс сам по себе добавляет мягенько
Он ничего не добавляет "мягонько", он буквально добавляет разницу. Если эта разница разных атрибутов то при правильном выборе базовой модели для вычитания будет эффект, похожий на дополнительную тренировку того что есть в модели из которой вычитается. Если там будет нечто общее или выбрать неверную модель для вычитания - будут только поломки и оверфит. Для недалеких - всеравно что применить лору дважды.
Ему нет применений для мерджа разных эпох модели, он приведет только к поломок. Зачем ты "вмешиваешься в беседу" если несешь такой бред?
> не понимаю твоей радикальности, влетел и разбрасываешь "этанинужно" "этогавнокал" "ниработаит", как будто существует эталон какой-то
Потому что это действительно так. Почти пару лет назад все это уже проходили, и при наличии понимания выглядит максимально кринжово, всеравно что советовать двигать тазом и рычать для склеивания еот. Для жирухи с синдромом дауна (примитивной лоботомирующей лоры) подойдет, но во всех нормальных случаях будет только фейл.
> ничто не истина - все дозволено
Действительно, результата можно достигнуть разными путями, потому и важно понимать что именно какой эффект дает. Но у васянов в принципе голова не соображает чтобы что-то понять, и отсутствует опыт и знания для каких-либо выводов. Поэтому, получив жалкое подобие успеха не из-за правильных действий, а потому что случай максимально примитивен и в нем можно что угодно товрить и как-то придти к концу, они фиксируются на ошибках и пытаются их тиражировать, выдавая за прорыв.
> Учитывая что ты раздаешь советики и ультимативен в своих тезисах, но не в курсе про ротейшен/свд, всё ясно.
Это буквально
> ррряяяя смотри я знаю термин, я его слышал в видосике, понял?! слышал про него и знаю, а значит все мои слов истина! я еще ты его не знаешь, яскозал яскозал!
максимальный кринж. Ты сам не понимаешь о чем говоришь, и при этом делаешь какие-то выводы за собеседника. Видимо, подсознательно ощущаешь что хлебушек и не вывезешь в нормальной дискуссии, потому пытаешься это свести к низкосортному срачу. Уровень сразу виден.
> Ок, чатжпт
Вот и твой источник познаний найден, кривая интерпретация языковой модели, которой изначально задаешь неверный вопрос, с заложенным ответом.
> Да, размер датасета коррелирует с выбором learning rate (LR)
Сетка пытается дать тебе сдержанный ответ, намекая о том что для разных датасетов и целей тренировки вся совокупность гиперпараметров должна быть подбрана. А вовсе не то, что лр как-то зависит от размера датасета, любой кто что-то смыслит в теме поймет насколько абсурдны твои выводы. Это то же самое что говорить о том, что в законе ома сопротивление зависит от приложенного напряжения. И ведь правильно задав вопрос, ллм вспомнит про температурную зависимость удельного сопротивления, свяжет это с током, тот с напряжением и даст ложный ответ. Хотя скорее всего не даст а приложит дополнительные комментарии с объяснениями, но глупцы их не поймут.
> Держи в курсе.
Настолько жопа разлетелась от того что с ним не согласились а просто спокойно обозначили возможные ошибки, что уже сам влезает не туда и пытаешься хоть что-то спиздануть.
tldr: шизик после долгих попыток натренил лору на еот, накрутил уверенности с бесплатной чмоней и теперь мнит себя мастером
> там наверное жирнющий подробный капшн, на котором и учили саму модель
Разные реализации бывают. Там не совсем капшн, там стоит адаптер и широкий входной слой дита под эмбединги и их маску. В качестве них может быть что-то примитивное, вплоть до буквально токенов, или же что-то обработанное. Если модель опенсорсная - можно посмотреть ее структуру залезая в либы в репорте по ней, там хотябы общие схемы всегда ставят. Тебя конкретно подготовка кондишнов интересует, или то как модель их внутри блоков обрабатывает?
Как правило, короткие фразы из промта юзера преобразуются в что-то более крупное, но много лишнего на этом этапе не добавляется, все уже внутри саммой диффузии "выбирается".
> Когда у диффузии есть больше инфы и меньше неопределенности, у нее остается больше ресурсов на то чтобы сконцентрироваться на более высоких абстракциях
Все несколько сложнее. При обучении с одной стороны важна максимальная информативность кондишнов, чтобы там была упомянута каждая мелочь, так модель будет им обучаться. Но это приводит к тому что не усваиваются более общие и абстрактные вещи, например на простые промты без описания всего и вся будет ерунда. Поэтому, применяют техники аугументации, с отсечением частей кондишнов (вплоть до полгого удаления в небольшом проценте итераций в батче, это важно для корректной работы cfg). Можно делать это уповая на рандом, можно заранее запланировать с учетом датасета. Также, могут варьироваться маски или изредка полностью пропускаться некоторые участки обработки.
> так как лосс не ебет по хуйне
В том и проблема что он просто так не позволяет выделить что хуйня а что не хуйня. Есть методы разной оценки, маскировки и воздействия на него, но (в опенсорсе) для диффузии они на низком уровне.
> Мне расскажи
Будет тяжело читаться, потому что это настолько абсурдно что вызывает эмоциональный отклик. В какой-нибудь около ирл дискуссии, особенно в более менее знающем коллективе это чудо мгновенно бы слилось. Хотя такое невозможно, ибо еотолораделов с таким шизослопом никто и никогда всерьез не воспринимал, и к чему-то релевантному они доступа не имеют. Просто скучно вечером, вот и решил его раскидать, дело наблагодарное на самом деле ибо шизло не воспримет и дальше будет мношить свой бред.
Передайте таблеток против жизни вот этому горелодупому
> начинают учить как делать что-то с явным посылом на владение Истиной при многообразии вариантов, то это редфлаг ебаной чсвшной преисполнившейся помойки
И теперь смотрим на шизослоп
> Ни разу не было на тестовых прогонах с кропом даже на первой эпохе, а вот без кропа лезет какая-то хуйня. Полные лоры с кропом работают как должны.
> кондишены и не важны на самом деле
> Все нормально, те нинужны. Прими как факт.
Какой френдлифаер.
Хорошая иллюстрация "правильных" методов тренировки, заставить модель генерировать срань из паттернов похожих на датасет с поломкой всего и вся.
> или 2hoes помимо Реймухи?
И еще большинство втуберов. Зато ces by gpo прекрасно усвоился.
> Такой батч сам по себе плох, они не тренят с шума или весов 1.0, это шлифование файнтюна.
this, именно оно. Ну и там еще был ряд проблем: стратегия обучения те странная; вместо капшнов мешанина с упущенными тегами, также частично удалялись артисты, некоторые теги и неконсистентно вводилить свои; стратегия дропа слишком агрессивная; датасет нормально не фильтровался - готовился; ограниченный баккетинг и математические алгоритмы апскейла вместо нейронок (и то не везде, были лоурезы); следствие разрешения - из-за особенностей тренера там далеко не всегда был батч 1000 ибо количество могло не набраться, потому шаг мог вжариться на значительно меньшем количестве пикч без изменения лра. и сам к этому причастен, стыд
Да и много чего, но винить их не то чтобы стоит, ибо ранее такого толком никто не делал, каждый тянул на себя одеяло, сроки были очень сжатые а давление извне высоким. Получилось то что получилось, спасибо и за это.

>Хорошая иллюстрация "правильных" методов тренировки, заставить модель генерировать срань из паттернов похожих на датасет с поломкой всего и вся.
>Хрень, на том моём гриде кстати только 1 и 4 "нормальные" остальные андердоги, прикол на 1гёрл получить, с этим любая из них справится, а конкретно тот аутлеер найденный генерализовать нормально, как на 1 и 4
>Кстати не просто хрень, а тотал хрень, если выдаёт как на 2 и 3, но мб не шаришь и запромптил еще криво
Ой да пошел ты на хуй, сначала кинул датасет, как пример кинул вообще пикчи с подкруткой стилизации хуй пойми какой не в датасет вообще, а теперь оказывается что тренировка - это не генерировать срань из датасета, а на самом деле надо чтобы какуюто левую поебень генерило, которая к датасету не имеет вообще отношения, блять ору, какие-то андердоги манeвровые полезли, хотя у пикч с примеров НОЛЬ ОТЛИЧИЙ между собой вообще, там буквально накинуть любой атeншер поверх скоров и то же самое вылезет, пyки про генерализацию которой тупа блять нахуй нет в примере изначальном. Какая блять генерализация? Генерализация пониконцепта который со скорами лезет и рисует лайтинг eдж и женерик свимсьюты на мокрой жопе анимебляди? Рили блять анимeшник всегда ебанутый, пойду дальше холодильники тренить, ни копейки времени на пиздеж с онемецефалами итт не потрачу больше.
Слив засчитан. Тренишь лоботомитов по своему образу и подобию - нахуй срыгспок.
Анимедayн, спок.
> И еще большинство втуберов
Я вообще упомянул, просто очень "смешным" словом
> Хорошая иллюстрация "правильных" методов тренировки, заставить модель генерировать срань из паттернов похожих на датасет с поломкой всего и вся.
Да в том то и дело что не получилось вообще, даже хуже дефолтных настроек выглядит но хз что он там ещё промптил, вся суть изначально была что я выдвинул инфу что натренить подобные аутлееры в пони невозможно любым другим способом, кроме как вжаркой лютой, для примера вот эту старую понихуйню просто взял
Че бахнул то?
> как пример кинул вообще пикчи с подкруткой стилизации хуй пойми какой не в датасет вообще
Всмысле бля, вот тебе конкретный пример, естественно с метой, свежий даже не поленился на этой старой херне сделать https://litter.catbox.moe/1vrs1w.png
Две первые можно считать хоть какой то генерализацией на этом аутлеере, дальше дора и глора, которые хуёво перформят, но без поджарки хотя бы, по датасету или близко к дистрибьюции справляются
> это не генерировать срань из датасета, а на самом деле надо чтобы какуюто левую поебень генерило, которая к датасету не имеет вообще отношения
Тренировка стиля это генерировать остальные знания модели, накладывая срань датасета вместо скина
>Че бахнул то?
С того что ебаный анимеинвалид замисматчил меня по полной.
>Всмысле бля, вот тебе конкретный пример, естественно с метой, свежий даже не поленился на этой старой херне сделать
>Две первые можно считать хоть какой то генерализацией на этом аутлеере, дальше дора и глора, которые хуёво перформят, но без поджарки хотя бы, по датасету или близко к дистрибьюции справляются
1. Пикчи одинаковые фактически, я вообще в душе не ебу где и в каком месте там отличия. Максимум если не знать, что это оказывается три разных лоры, выглядит как погрешность сида. И это я с позиции того что я хуйдожник с абразаваньем смотрю с огромной насмотренностью. Допустим может это у меня мозг сбоит и прошаренный отаку под сакэ видит в той хуйне отличия и сходство с датасетом, в таком случае я подстраховался и кинул другому хуйдожнику пикрел.
2. Аналогичная стилистически анимехуйня выводится в дефолтных понях и так, мне пришлось лернинги задирать чтобы перекрыть стили лезущие из скоров связанные с аниме чтобы они хоть как-то отличались от примерной стилизации примера твоего.
3. Ты во втором окне отрой датасет свой, я не знаю кем надо быть чтобы говорить что у пикч с примера есть что-то общее с датасетом вообще.
>Тренировка стиля это генерировать остальные знания модели, накладывая срань датасета вместо скина
Тогда я всё сделал правильно.
> Пикчи одинаковые фактически, я вообще в душе не ебу где и в каком месте там отличия. Максимум если не знать, что это оказывается три разных лоры, выглядит как погрешность сида. И это я с позиции того что я хуйдожник с абразаваньем смотрю с огромной насмотренностью. Допустим может это у меня мозг сбоит и прошаренный отаку под сакэ видит в той хуйне отличия и сходство с датасетом, в таком случае я подстраховался и кинул другому хуйдожнику пикрел
Ну такое увидеть можно не будучи хуйдоджником, а будучи нейродебилом, когда заебёшься с понями далеко от дистрибьюции генерить и получать пролезающий дефолтный стиль и пойдёшь во все тяжкие, как я, тренить 20 разных версий разными подходами, сравнивая между собой результаты
> Аналогичная стилистически анимехуйня выводится в дефолтных понях и так, мне пришлось лернинги задирать чтобы перекрыть стили лезущие из скоров связанные с аниме чтобы они хоть как-то отличались от примерной стилизации примера твоего
Ну хорошо, убери скоры и сурс, не поможет https://litter.catbox.moe/gys1s6.png
> Ты во втором окне отрой датасет свой, я не знаю кем надо быть чтобы говорить что у пикч с примера есть что-то общее с датасетом вообще
Общий уклон цветогаммы в желто-коричневый оттенок, лайн вокруг чара, пропорции чара датасета в конце концов
> Тогда я всё сделал правильно.
Где? Здесь, например, вообще мимо здесь уже более менее нормально но если дашь всю инфу генерации то я попробую с этими 4 версиями, скорее всего с ними тоже на этом промпте будет всё в порядке
>Тебя конкретно подготовка кондишнов интересует, или то как модель их внутри блоков обрабатывает?
Да я так, просто всем интересуюсь. Ты видел то ту модель? Тот пример со львом так то нихуево выглядит, как понимание модели смысла происходящего и согласованности.
>например на простые промты без описания всего и вся будет ерунда
И потому там промт разворачивается ллмкой, которая там 100% есть. Иначе да, ни один нормиюзер длинную шизопростыню писать никогда не будет, но если у тебя один формат капшнов, то ничего сложного свернуть их суммарайзом в одно-два предложения, а потом на этом файнтюнить ллм, она формат хорошо усвоит и никаких проебов качества не будет.
>(вплоть до полгого удаления в небольшом проценте итераций в батче, это важно для корректной работы cfg).
От этой хуйни надо тоже избавляться, так как качества самим весам это очевидно не прибавляет. Лишь костыль для работы другого костыля.
>Также, могут варьироваться маски или изредка полностью пропускаться некоторые участки обработки.
Это да, вотермарки хотя бы закрыть, это же вообще ничего не стоит... А так наверное можно придумать какую-нибудь эвристику, чтобы маскировать лосс областями там где он сильно высок. Curriculum learning типа. Вообще повесить gan следом, и брать не градиент с него, как обычно принято, а маску.
Кста, мне чатгпт недавно напиздела, когда я у нее спрашивал как работают таймстепы, типа на тысячном, если модель "идеально" предсказывает шум то якобы должно получиться исходное изображение после его вычитания. Я ей даже сначала поверил, уж слишком она и не только она уверенно пиздела. Но когда сам разобрался, конечно же оказалось полностью наоборот. Из зашумленного изображение исходное никак невозможно получить. Инфа теряется пропорционально добавленному шуму.
Diffusion Meets Flow Matching: Two Sides of the Same Coin
В начале декабря группа чуваков из Глубокого Разума, среди коих признанные аксакалы, как Hoogeboom, De Bortoli и Salimans опубликовала презанятнейший пост Diffusion Meets Flow Matching: Two Sides of the Same Coin (https://diffusionflow.github.io/).
Нынче стало модно учить диффузионки в Flow Matching постановке. Тренд, по всей видимости, был задан SD3 (https://stability.ai/news/stable-diffusion-3). И большинство нынешней SOTA в картиночной и видео генерации (из того, что известно) FLUX, MovieGen, HunyuanVideo.
И что это значит? Классическая парадигма - пережиток истории 🤔?
Ан нет.
В данном блогпосте авторы в деталях анализируют процесс сэмплирования и обучения в стандартной noise-prediction Variance Preserving (VE) диффузионной постановке и Flow matching, и показывают, что по сути обе сущности про одно и то же. Основная разница в коэффициентах при шуме/сигнале и использовании скорости в качестве выхода нейронной сети вместо шума/x0. И по ходу повествования эквивалентность двух парадигм авторы иллюстрируют с разных сторон.
Сам блогпост содержит красивые 🥰 иллюстративные визуализации с ползунками 😮.
Кроме того, авторы опровергают распространенное мнение, что Flow Matching дает непременно более прямые траектории, чем диффузия. Для узких распределений Flow Matching действительно дает более прямые траектории, чем типичный диффузионный процесс, но для широких распределений все может поменяться с точностью до наоборот. Впрочем, для наиболее типичного сценария text-2-image генерации или редактирования изображения, целевое распределение, по всей видимости, достаточно узкое.
В начале декабря группа чуваков из Глубокого Разума, среди коих признанные аксакалы, как Hoogeboom, De Bortoli и Salimans опубликовала презанятнейший пост Diffusion Meets Flow Matching: Two Sides of the Same Coin (https://diffusionflow.github.io/).
Нынче стало модно учить диффузионки в Flow Matching постановке. Тренд, по всей видимости, был задан SD3 (https://stability.ai/news/stable-diffusion-3). И большинство нынешней SOTA в картиночной и видео генерации (из того, что известно) FLUX, MovieGen, HunyuanVideo.
И что это значит? Классическая парадигма - пережиток истории 🤔?
Ан нет.
В данном блогпосте авторы в деталях анализируют процесс сэмплирования и обучения в стандартной noise-prediction Variance Preserving (VE) диффузионной постановке и Flow matching, и показывают, что по сути обе сущности про одно и то же. Основная разница в коэффициентах при шуме/сигнале и использовании скорости в качестве выхода нейронной сети вместо шума/x0. И по ходу повествования эквивалентность двух парадигм авторы иллюстрируют с разных сторон.
Сам блогпост содержит красивые 🥰 иллюстративные визуализации с ползунками 😮.
Кроме того, авторы опровергают распространенное мнение, что Flow Matching дает непременно более прямые траектории, чем диффузия. Для узких распределений Flow Matching действительно дает более прямые траектории, чем типичный диффузионный процесс, но для широких распределений все может поменяться с точностью до наоборот. Впрочем, для наиболее типичного сценария text-2-image генерации или редактирования изображения, целевое распределение, по всей видимости, достаточно узкое.
Датасет на 3к картинок, батч 2, аккумуляция 3, рандомно выбирает файл из датасета и выдает OSError, на первой эпохе гдето в промежутке 10-30 шагов. В чем может быть проблема? Файлы не битые.
Error loading file
OSError: Caught OSError in DataLoader worker process 0.
Error loading file
OSError: Caught OSError in DataLoader worker process 0.
Чекай файлы на наличие прозрачных бг
Сколько VRAM надо для трена классического контролнета не островного lllite-говна под XL? Сам контролнет в diffusers сжирает 16 гигов, UNET на 24 гигах в ООМ падает, на две карты не переносится - граф рвётся. При этом без градиентов всё вместе всего 9 гигов жрёт. В issues челики с А100 жалуются на ООМы. Они там сколько конволюшенов туда напихали, что он так жрёт? Пиздец какой-то.
Ну что ты там, реально стух чтоли? Скинешь хоть что натренил в гридах посравнивать?
Там нету пнгшек, битмапы и жыпеги, причем триггерится на жипеги, говорит чтото типа OSError: image file is truncated (25 bytes not processed), хотя само изображение открывается для просмотра и прочее. Взял другой датасет на 5к изображений, уже пять часов нормально тренит.
> Ну что ты там, реально стух чтоли?
Да.
>Скинешь хоть что натренил в гридах посравнивать?
Удалил.
> File "D:\kohya_ss-24.1.7\kohya_gui\common_gui.py", line 1263, in SaveConfigFile
> os.makedirs(os.path.dirname(folder_path))
> File "C:\Program Files\Python\lib\os.py", line 225, in makedirs
> mkdir(name, mode)
> FileNotFoundError: [WinError 3] Системе не удается найти указанный путь: ''
Чо за хуита выскакивает при попытке тренировки? Питон установлен.
> os.makedirs(os.path.dirname(folder_path))
> File "C:\Program Files\Python\lib\os.py", line 225, in makedirs
> mkdir(name, mode)
> FileNotFoundError: [WinError 3] Системе не удается найти указанный путь: ''
Чо за хуита выскакивает при попытке тренировки? Питон установлен.
Тебе же пишет что долбаёб коха не умеет рекурсивно папки создавать.
Так что делать то надо, чтобы ошибка ушла?
Есть ли кто-нибудь, кто готов поделиться случайным датасетом и конфигом под него, с которым получились хорошие результаты + примеры использования?
Можно даже под полтораху, интересен небольшой, нетривиальный датасет.
Можно даже под полтораху, интересен небольшой, нетривиальный датасет.
нетривиальный какого плана
Ну типа не ебало еот или стиль который не поймешь сразу применился или нет.
Еще вопрос. Как записать кусок промта или весь промт в файл-эмбеддинг?
От какого параметра зависит т.с. превалируемость лоры над весом модели при ее полном применении?
Оптим продижи, по настройкам:
конв дим 16, конв альфа 1 (чтоб снизить влияние сверточков)
нетворк дим 16, альфа дим 1 (опять же чтобы половинить влияние лоры)
д0 1е4
Дропаут 0.1 чтобы не перетренивать на дате
Тренировка нормализационного слоя вкл
Дора вкл
Биас корекшен вкл
Лосс л2
Снр гамма 1
Приорлосс 1
Батч 2
Пока натренил 3 варианта с разным дкоеф и результаты странные.
При дкоеф 10 при полном применении лоры очевидные перетрен, но это и понятно, дефолт дкоефа 1. Если снижать вес лоры до 0.5 то более менее норм, при весе 0.2 результат прям топ.
Исходя из предыдущего пункта логически нужно ставить дкоеф 2 (0.2 от 10), итоговая лора при полном весе уже не совсем перетрен но есть деформации и управлять промтом также нереально. При 0.5 уже терпимо. При 0.2 опять же так же хорошо как с 0.2 при дкоеф 10.
Поставил дкоеф 0.5, результат при полном весе буквально картинки из датасета, при 0.5 хорошо, при 0.2 опять же пушка гонка качество и управление.
Сейчас тренится дкоеф 0.1 и чтото мне подсказывает что будет снова точно такая же ситуация когда фул вес дает картинки с датасета.
Почитал что если альфа на конве стоит на 1, то это значит линейное применение и при полном применении лора является ведущей по весам и замещает собой всё, звучит максимум нелогично, но в целом так и получается, перекинул лоры на другую модель и там на полном весе точно также датасет картинки лезут.
Так вот вопрос: че подкрутить и в какую сторону чтобы полновесная лора не замещала собой веса основной модели? Моя логика с понижением адаптации через дкоеф работает получается только чтобы перетрена не было, а замещение как было так и остается.
В инете говорят что надо ставить альфы в половину от дименшенов и только на особых алго надо их в 1 или меньше укатывать, типа гибкость больше, но это же в 8 раз больше параметров наоборот, нелогично нихуя. Что будет если поставить альфы в 0.1 кстати? Мне ощущается что сила замещения будет меньше, но так как результаты наоборотные, то будет видимо вообще застревание на дате из датасета еще большее.
Оптим продижи, по настройкам:
конв дим 16, конв альфа 1 (чтоб снизить влияние сверточков)
нетворк дим 16, альфа дим 1 (опять же чтобы половинить влияние лоры)
д0 1е4
Дропаут 0.1 чтобы не перетренивать на дате
Тренировка нормализационного слоя вкл
Дора вкл
Биас корекшен вкл
Лосс л2
Снр гамма 1
Приорлосс 1
Батч 2
Пока натренил 3 варианта с разным дкоеф и результаты странные.
При дкоеф 10 при полном применении лоры очевидные перетрен, но это и понятно, дефолт дкоефа 1. Если снижать вес лоры до 0.5 то более менее норм, при весе 0.2 результат прям топ.
Исходя из предыдущего пункта логически нужно ставить дкоеф 2 (0.2 от 10), итоговая лора при полном весе уже не совсем перетрен но есть деформации и управлять промтом также нереально. При 0.5 уже терпимо. При 0.2 опять же так же хорошо как с 0.2 при дкоеф 10.
Поставил дкоеф 0.5, результат при полном весе буквально картинки из датасета, при 0.5 хорошо, при 0.2 опять же пушка гонка качество и управление.
Сейчас тренится дкоеф 0.1 и чтото мне подсказывает что будет снова точно такая же ситуация когда фул вес дает картинки с датасета.
Почитал что если альфа на конве стоит на 1, то это значит линейное применение и при полном применении лора является ведущей по весам и замещает собой всё, звучит максимум нелогично, но в целом так и получается, перекинул лоры на другую модель и там на полном весе точно также датасет картинки лезут.
Так вот вопрос: че подкрутить и в какую сторону чтобы полновесная лора не замещала собой веса основной модели? Моя логика с понижением адаптации через дкоеф работает получается только чтобы перетрена не было, а замещение как было так и остается.
В инете говорят что надо ставить альфы в половину от дименшенов и только на особых алго надо их в 1 или меньше укатывать, типа гибкость больше, но это же в 8 раз больше параметров наоборот, нелогично нихуя. Что будет если поставить альфы в 0.1 кстати? Мне ощущается что сила замещения будет меньше, но так как результаты наоборотные, то будет видимо вообще застревание на дате из датасета еще большее.



Короче.
old woman face, cute, show breast
Пик 1 дефолт, пик 2 16 по дименшенам и 8 по альфам, пик 3 16 по дименшенам 1 по альфам
дкоеф на пик 2 и 3 0.1
вес применения 1, с таким весом на верси где альфа 8 больше мутантов и проебов, но зато полная копия датасетовских картиночек по кволити и содержанию (старых тянов вообще не было, одни молодухи и матюры) с полпинка, в версии пика 3 никаких проебов нет, но стилевая хуйня немного дальше и без расписывания промта датасетовское кволити не лезет особо
остается проверить 16x16, т.к. вероятно возможно мутации именно из-за халвинга матриц на внедатасетовых разрешениях получаются а так будет аналог 1x1 но без линейного применения на альфе с 1
> Ты видел то ту модель?
Ты про хуйнань или какую?
> как понимание модели смысла происходящего и согласованности.
Понимание смысла идет от правильной подготовки кондишнов и реакции на них, а согласованность уже исключительно сама диффузия.
> И потому там промт разворачивается ллмкой, которая там 100% есть.
Тут есть нюанс и не всегде сделано именно так. Например, часто модель используют не для прямого "разворачивания" а для некоторого семантического анализа и получения "смысловых" активаций, на которые уже удобно реагировать. Хороший пример с T5, классический энкодер-декодер, который можно натренить на любую t2t задачу и будет очень даже прилично, или обрезать жопу и получить с середины уже обработанные кондишны. Но возникает уже своя проблема - модель может плохо понимать теги, которткие вещи или что-то специфичное (ровно то что видим с диффузией, которая использует т5).
К этому можно добавить дополнительный костыль в виде разворачивающей ллм, о котором ты и написал. Как, например, хочет сделать Астралайт в новых понидифьюжн, или тот же далли3, к которому тексты поступают уже после обработки. Но вариант тоже специфичный, иногда просто тренировка энкодера может дать гораздо больше, чем попытки ужать для пропихивания через бутылочное горлышко.
> От этой хуйни надо тоже избавляться, так как качества самим весам это очевидно не прибавляет.
Сложный вопрос, тут во-первых, само определение cfg, во-вторых, оно дает свои преимущества и такая вот аугументация. Тут все на костылях построено, увы.
> вотермарки хотя бы закрыть, это же вообще ничего не стоит
На самом деле задача не самая простая, как минимум нужна будет модель, которая сможет точно формировать маску для них. Мало кто этим занимается, даже у корпов лезут подписи.
> можно придумать какую-нибудь эвристику, чтобы маскировать лосс областями там где он сильно высок
Хз насчет эвристики, но при тренировке ты его буквально видишь и именно прямой модификацией делается маскед-лосс. Можно действительно сделать процедурный алгоритм для сглаживания областей с большими величинами, или применения каких-либо обработок. Вот только что там выйдет на практике уже нужно смотреть.
> чатгпт недавно напиздела, когда я у нее спрашивал как работают таймстепы
Они регулярно серут и плохо понимают эту тему. Чуть лучше отвечает опус и сонет 3.5, но даже те могут в двух соседних свайпах себе же противоречить.
> Из зашумленного изображение исходное никак невозможно получить. Инфа теряется пропорционально добавленному шуму.
Именно. Отсюда кстати берет корни баг, заложенный в SD. Там зашумливание по дефолту не полное, из-за чего самые нижние гармоники (общая яркость) сохранялись, и наступает проблема средней яркости и плохой когерентности.
При тренировке на стиль художника нужно чтобы только один персонаж был на картинке или можно несколько?
Чем более разнообразные картинки тем лучше. Один или несколько - без разницы, главное чтобы не везде одинаковые.
Чтобы вопрос не висел в пустоте, отвечу на него спустя две недели.
Анон по сути придумал технологию мешграфомеров:
https://github.com/microsoft/MeshGraphormer
В комфи есть нода для неё, но я не смог запустить её из-за ада зависимостей.
>Ты про хуйнань или какую?
Гугл veo новая. Вот видрил с которого я охуел немного. Не верю что чистая диффузия в такое может, даже если ее через какой-нибудь gan тренили, он должен быть дохуя умным сам по себе. Либо каскадная модель, где первую ступень можно из умной ллмки получать. Не в виде текста или тех же эмбедингов, а во временно-согласованной структуре.
>Сложный вопрос, тут во-первых, само определение cfg, во-вторых, оно дает свои преимущества и такая вот аугументация. Тут все на костылях построено, увы.
А кто-нибудь пробовал безпромт для cfg в лору сливать, а родные веса не трогать? Или лора в негативе на генерации все сломает? Хотя негатив обычно все же не пустой, хуй знает как это будет работать.
>На самом деле задача не самая простая, как минимум нужна будет модель, которая сможет точно формировать маску для них. Мало кто этим занимается, даже у корпов лезут подписи.
А смысл точной маски? Точность все равно проебется после vae, достаточно бокса, его и разметить можно очень просто, и провалидировать можно чуть ли не весь датасет в одно рыло. Подписи обычно не очень большие, и если боксы нарезать в одну ленту html-страницы, то можно глазками очень быстро отбраковывать проебы.
>и именно прямой модификацией делается маскед-лосс
Я вообще читал что лучше не лезть в сам лосс а занулить градиент после лосса по той же маске. Ибо там якобы какие-то протечки в лоссе могут быть.
> Не верю что чистая диффузия в такое может
А что в этом такого уникального? Наоборот, диффузия очень хорошо ухватывает некоторые закономерности, последовательности, особенности взаимодействия предметов и прочее. В отличии от каких-то моделей и движков, тут могут быть абсурдные артефакты, зато оно прекрасно воспроизведет всякую "физику", взаимодействия в ту самую согласованность. Оно не понимает ничего, просто воспроизводит концепт отражения в зеркале с синхронным движением объектов.
> безпромт для cfg в лору сливать, а родные веса не трогать?
Не совсем понял что ты хочешь сделать, распиши подробнее.
> А смысл точной маски?
Для минимизации влияния на остальные объекты, есть достаточно крупные ватермарки, и не сказать что оно прямо так проебывается.
> разметить можно очень просто, и провалидировать можно чуть ли не весь датасет в одно рыло
Попробуй заняться этим, есть и готовые тулзы, правда придется чуть попердолить. Есть и готовые модели, аниме ватермарк на обниморде. Только количество и разнообразие ватермарок такие что нормальной точности сложно получить.
> что лучше не лезть в сам лосс
Ты можешь вносить в него модификации как просто умножая на коэффициент, так и делать это с его отдельными областями. Ну а как вычленить градиенты от этой части уже после обарботки не зацепив все остальное - хз. Распиши подробнее.
Скиньте самый актуальный скрипт по обучению моделей.
>Не совсем понял что ты хочешь сделать, распиши подробнее.
Ну, очевидная мысль, что если образцы без подписей при тренировке не добавляют качества самой тренировке с подписями, и если от этого нельзя отказаться, то может быть стоит хотя бы в лору запекать пустые подписи, чтобы это не влияло на основные веса. Сразу же понятна проблема, что негатив в генерации обычно не пустой, а значит эта схема работает неправильно. (На генерацию негатива надо подключать эту самую лору).
Но если же эта теория не верна, и пустые подписи на самом деле идут в плюс и работают как регуляризация, то тут уже возникают вопросы, почему и насколько?
>Для минимизации влияния на остальные объекты, есть достаточно крупные ватермарки, и не сказать что оно прямо так проебывается.
Опять же, насколько велико это влияние? Можно закрыть нахуй маской рандомную половину картинки, например. Чет мне кажется модель сильно хуже учиться не будет, фоны на персонажах же так закрывают. Можно хитрее проверить, каким-нибудь шахматным паттерном или случайным шумом. Так что я думаю в ватермарку достаточно примерно боксом попасть и проблем не будет. Проблемы будут там где вотермарка проскочила в датасет, а если случайный кусок закрыли - похуй, будем считать что это регуляризация, лол.
>Ну а как вычленить градиенты от этой части уже после обарботки не зацепив все остальное - хз. Распиши подробнее.
Последний выходной нейрон, пиксель латента, по сути, просто если попадает под маску, то делаем ему градиент - 0. Это 100% метод который ничего не ломает. На коэффициент по идее тоже можно умножать, только надо пересчитать его кривую.
Хз, если занулять сам лосс, вроде бы то же самое, но я где-то читал что нет. Если лосс там внутри усредняется-нормируется, то вырезанный кусок влияет на расчет.
> ватермарки
Достаточно взять любой DiT и навсегда забыть про подобное. В том же Флюксе даже если весь датасет в ватермарках, в генерациях они не появятся пока не запромптишь.
Не пизди, флюкс их всасывает точно так же как и хл, единственное отличие, что он их воспроизводит идеально, в отличии от предыдущего говна с 4канальным вае и промпт от этого не спасает. Ты т5 чтоли вжаривал?
https://github.com/kohya-ss/sd-scripts
Ветки в зависимости от нужд (sd3, dev и тд). Алсо там пчелик левый сподобился для шедулерфри продижи фуседбакпас запилить поддержку, вот этот форк https://github.com/michP247/sd-scripts/tree/8cee727a990a0c499ee5ff44c2a3e8625b756742
dreambooth training sd3.5medium @512x512 res w/ args --fused_backward_pass --optimizer_type="prodigyplus.ProdigyPlusScheduleFree" --optimizer_args prodigy_steps=2500:
base prodigy = 27.2 gb vram
prodigy-plus-schedule-free = 15.4 gb
prodigy-plus-schedule-free w/ FBP = 10.2 gb
Я на сдхл погонял тоже, норм уменьшает врамчик.
Если ты капшены так же по даунски как и на XL делаешь, то естественно говно получается. Литералли любая vlm увидит ватермарку и напишет что на ней, а то что ты прописал в капшене при генерации без прямой просьбы не появится. Это всегда работает, оно просто не может не работать. Я тренил кучу лор на порнухе, там бывают ватермарки на четверть экрана, никогда не вылезали при генерации. Для этого ничего дополнительно не надо делать.
Я мимошел в вашем диалоге не участвовал, но считаю что проблема ватермарок это проблема базовой модели и настроек агрессивности тренинга/гиперзапоминания на низковариативном составе датасета (когда у тебя все изображения не аугментируются вообще никак и скармливаются 1 к 1 где ватермарка будет всегда в одном месте). Я тоже по порностилистикам угараю и при этом вообще кепшены не юзаю и ватермарки тоже не лезут, например потому что изначальный файнтюн (бигасп 2, там годно закурировал датасет свой чел) и сама сдхл база по дефолту не надрочены на то чтобы ватермарки выблевывать. И напротив можно упомянуть про натвис где челу например было похуй на ватермарки и при гене условных селфи частенько онлифанс проскакивает в качестве марки.на самой базе.
> если образцы без подписей при тренировке не добавляют качества самой тренировке с подписями
Ну как сказать, объективного вреда от этого нет, даже наоборот. Кроме анкондишнал генерации чего-то среднего по датасету, или части что наиболее отличается от среднего по модели, но грустить с того что с пустым промтом делает канничек только дурак будет.
> стоит хотя бы в лору запекать пустые подписи
Вот это не понял, что значит запекать в лору? Там просто в батче у некоторых специально или случайно выбранных пикч не будет подписей.
> насколько велико это влияние?
Настолько, насколько захватываешь лишнего. Если постоянно еще будешь закрывать одни и те же места картинки, с этой областью в дальнейшем будут проблемы.
> думаю в ватермарку достаточно примерно боксом попасть и проблем не будет
Попробуй, скажешь как получается. Пока что ни одного успешного (озвученного) кейса с подобным подходом нет.
> пиксель латента, по сути
Неа, там не совсем пиксель латента. А так всегда умножают на ноль конкретные пиксели лосса или все величины.
Ну удачи.
Оно может нормально научиться только на разнице. И как у тебя влмка их протегает, "ватермарка такого-то хуя"? Простейшие тексты проблем даже в 1.5 не вызывали, а так там всегда там или эмблема, или особый шрифт, или хитрая подпись. В удачном кейсе оно зацепит что "ватермарка в углу" это вот именно эта штука, а насколько протечет параллель с тренируемым стилем/персонажем - большой вопрос. Если недефолтные ватермарки везде то будут лезть со страшной силой.
> тренил кучу лор на порнухе, там бывают ватермарки на четверть экрана
Какая-то блядища и совершенно разные ватермарки с разных студий/ресурсов по вполне типичным паттернам, они даже сами по себе слишком нерегулярны чтобы их запомнило. Зато если захочешь какого-то художника тренишь - насладишься.
Все так, она просто слишком разные и дадут лишь косвенные проявления даже если не описывать.
> удачном кейсе оно зацепит что "ватермарка в углу" это вот именно эта штука
У меня vlm в таком виде их всегда тегает.
> There are two watermarks visible: "by Tommy Bernstein" in the bottom left corner and "femjoy.com" in the bottom right corner.
> There is a watermark on the image that reads "u/PCake99".
Никогда не пропускает, никогда не видел на генерациях их. В том числе после полного пака пиков, где 50 раз ватермарка повторяется. Если текст ватермарки прописан, то куда она денется, любой DiT в текст умеет.
> с тренируемым стилем/персонажем
Если XL, то надо по схеме b-лоры делать, выкидывая остальные слои, туда в принципе ватермарки не могут протечь, я без проблем тренил на рандомном говне с артстешена, даже на постерах норм стили тренить.


Ну это простая херня и текст, который будет разный в разных пикчах, за счет этого похуй если совсем не фейсроллить. Там же речь уже про вполне нормальную, полноценную и консистентную ватермарку, которая будет приписана артисту.
> Если текст ватермарки прописан
Но даже и текст может быть довольно непростым, как на пикрелах, и оно будет везде. У рингеко они в разных вариациях и постоянно над важными объектами, тут и флюкс пасует.
Кстати ватермарка с первой пикчи становится популярной в минимальных вариациях, и модель именно на нее легко обучается, ибо она на разных художниках, стилях, персонажах почти одинакова! Это позволяет в крупных датасетах обучать не удаляя, будто это просто отдельный концепт и элемент, даже негативить не придется потом.
Не перестаю с этого орать, массовая акция художников привела не к появлению единой штуки, которая бы сильно лезла везде, а наоборот к систематизации хорошо регуляризуемого объекта, который даже удалять не надо. В итоге, страдают только зрители и сами авторы с горящей жопой.

ребята. ну вот я закал себе лламу 3 на локалку, но как теперь её тьюнить что бы отключить политкоректность и всякую хуйню для безопастности/ограничения?
есть у кого уже модель без всей это залупы?
есть у кого уже модель без всей это залупы?
Промптить научись, клован. Берёшь букварь и учишься писать буквы.
всмысле, то есть ты хочешь сказать что можно обойтись приймущественное количеств ограничений если просто промты ставить праввельно?
Блять скинь гайдик какой нить насчёт всё этой хуйни. инфы пиздец как монго, непонятно с чего начинать
> закал себе лламу 3
> как теперь её тьюнить
Для начала обзаведись 80гиговой видеокартой и хотябы средним знанием пихона и конкретно торча. Когда выполнишь - часть вопросов отпадет сама собой и можно будет уже обсуждать.
Лламатред двумя блоками ниже. Но там тебе также ответят, прочти тамошнюю вики для начала.


> Литералли любая vlm
Нет, не любая, на заре флюкса с популярностью гойкапшена он плохо протегивал wlop'а, хотя там 90% на полебла текст его ника, так же с пикрилом полный провал был без ручного затирания, пролезает слишком часто
А вот и глейзокал подъехал, лол, не смущает что вся пикча в масле?
>Блять скинь гайдик
Перегружай ввод, смени акценты в тексте, отвлеки от запрещенного, дай свободу выбора, предварительно её жестко ограничив.
> с популярностью гойкапшена
Он только у анимешников почему-то популярен был потому что умел тегами срать. Сейчас выбор огромный чем капшены делать, джой хуйня.
Если 1 и 2 картинки я худо бедно понимаю, то 5 и 6 вообще кошмар. Какой уровень линала и компьютер саенс нужен туттут нужен то?
выпал на года 1.5 из темы нахуй.
Щас пишу рассказик, к рассказику, на его базе хочу запилить кинцо-мыльцо визуальную новелку с минимумом ходить
Хочу базированные текстурки, свои, музыку свою, персонажей своих, минимально имел опыт моделирования.
Отношение у меня ко всему этому, такое, что ИИ крутой костыль, при условии, что ты сам стараешься и делаешь свой мирок, который интересен тебе, прежде всего.
Без воровства, переработок и индусо-засеров 100 раз переделанным патерном на новый лад
В связи с этим хочу приспособить локальную пекарню на 4070ti:
- Лингвистическая модель для перевода, локальная или нет, похуй наверное
- Озвучка персонажей
- Моделирование текстур 3Д, персонажей и прочего
- музыка
Есть ли смысл вкатываться, или все еще кал? Ну и ИИ как само хобби, все же головой понимаю, что смысл вката все равно есть ибо набью руку а там уже, что нибудь, новое завезут, что уже мне подойдет.
Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
так, что исходя их моеих хотелок, в какую сторону дрочить примерно? МОжно уровня только сказать имя актуалочки или что выстрелит или связки, остальное на ютубе сам задрочу
Щас пишу рассказик, к рассказику, на его базе хочу запилить кинцо-мыльцо визуальную новелку с минимумом ходить
Хочу базированные текстурки, свои, музыку свою, персонажей своих, минимально имел опыт моделирования.
Отношение у меня ко всему этому, такое, что ИИ крутой костыль, при условии, что ты сам стараешься и делаешь свой мирок, который интересен тебе, прежде всего.
Без воровства, переработок и индусо-засеров 100 раз переделанным патерном на новый лад
В связи с этим хочу приспособить локальную пекарню на 4070ti:
- Лингвистическая модель для перевода, локальная или нет, похуй наверное
- Озвучка персонажей
- Моделирование текстур 3Д, персонажей и прочего
- музыка
Есть ли смысл вкатываться, или все еще кал? Ну и ИИ как само хобби, все же головой понимаю, что смысл вката все равно есть ибо набью руку а там уже, что нибудь, новое завезут, что уже мне подойдет.
Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
так, что исходя их моеих хотелок, в какую сторону дрочить примерно? МОжно уровня только сказать имя актуалочки или что выстрелит или связки, остальное на ютубе сам задрочу
>- Моделирование текстур 3Д, персонажей и прочего
Моделлинг пока кал в том, что касается открытых моделей.
Можешь заценить по Треллису: https://huggingface.co/spaces/JeffreyXiang/TRELLIS
Это пока самый топ из того, что можно скачать на локальную машину и запустить.
>Лингвистическая модель для перевода, локальная или нет, похуй наверное
ЧатГПТ.
Гугловский Гемини, 50 бесплатных промптов на акк.
Claude лучше всего понимает и умеет в русский.
Всё из РФ недоступно. Плюс цензура, некоторые темы без нецензуренного входа с АПИшки обсуждать откажется (а некоторые и с апишкой).
Локальные сильно тупые.
>Озвучка персонажей
Посмотри профильные треды. Пока что все довольно сырое, и качество прямо пропорционально времени, которые ты на обработку потратишь. Вплоть до того, что самому озвучивать придется, и потом голос менять.
>Моделирование текстур 3Д, персонажей и прочего
Ничего годного в этой области нет. Только картинки.
>музыка
Вообще хз.
>Оч загружен и работой в ойтишечке и книжкой своей, и плагинодрочем в UE5.
Значит и не пытайся. Чтоб начать делать что-то хорошо - надо потратить дофига времени.
Чем ты делаешь?
Побуду амбассадором и периодически буду постить по обновам шедулер фри продигов мб кто не в курсе, т.к. это буквально на данный момент самая ёбовая ёба из существующих, позволяющая и фуловый чекпоинт тренить на лоурам без прибегания к адафактор калу, и лоры с пачкой автоматических мокрописек по принципу файр'н'форгет https://github.com/LoganBooker/prodigy-plus-schedule-free
Добавлено:
+ поддержка Gram из этого пула https://github.com/LoganBooker/prodigy-plus-schedule-free/pull/5 , дает наименьшую перплексити и наиболее быструю сходимость, еще пизже чем C-Optim которые также можно включить (но что-то одно)
+ в версии 1.83 добавлен манкипатч для работы fused_back_pass в kohya (собственно то изза чего адафактор является врам френдли оптимайзером для фул чекпоинт тренинга) из этого коммита https://github.com/LoganBooker/prodigy-plus-schedule-free/commit/93339d859eb7b1119a004edecf417f5318227af8 требующий комментирования строк 4118-4120 в train_util, в ишуях https://github.com/LoganBooker/prodigy-plus-schedule-free/issues/7 есть гайд по фиксу для работы фузеда с лорами в кое (требует оба аргумента фузеда и --fused_backward_pass в конфиге и "fused_back_pass=True" в оптимайзере), в версии 1.8.4 на основе этого ишуя теперь требуется только --fused_backward_pass
Добавлено:
+ поддержка Gram из этого пула https://github.com/LoganBooker/prodigy-plus-schedule-free/pull/5 , дает наименьшую перплексити и наиболее быструю сходимость, еще пизже чем C-Optim которые также можно включить (но что-то одно)
+ в версии 1.83 добавлен манкипатч для работы fused_back_pass в kohya (собственно то изза чего адафактор является врам френдли оптимайзером для фул чекпоинт тренинга) из этого коммита https://github.com/LoganBooker/prodigy-plus-schedule-free/commit/93339d859eb7b1119a004edecf417f5318227af8 требующий комментирования строк 4118-4120 в train_util, в ишуях https://github.com/LoganBooker/prodigy-plus-schedule-free/issues/7 есть гайд по фиксу для работы фузеда с лорами в кое (требует оба аргумента фузеда и --fused_backward_pass в конфиге и "fused_back_pass=True" в оптимайзере), в версии 1.8.4 на основе этого ишуя теперь требуется только --fused_backward_pass
Калом с уёбищным lr не пользуемся. На XL база обычный AdamW, на DiT - AdEMAMix. Уметь выставлять корректный lr - это чему быдло должно в первую очередь научится, перед тем как лезть в тренировку.


>На XL база обычный AdamW, на DiT - AdEMAMix
>петух_и_микрофон.жпг
Тя там с двух сторон в жопу ебут - адам по растригину в локальный минимум падает (но до решения хоть доходит) и там сдыхает в оверфите, по росенброку неизвестно как долго потребуется нахождение полного решения. И это еще не 8бит, который вообще сосиот. Итог: устаревшее говно для хлебобулочных изделий, которые просидят за настройками гиперов дольше, чем тренировка будет идти.
С адемамикса вообще проиграл, тут комментарии излишни.
> растригину
> росенброку
Ясно, ты шизик, даже не тренирующий ничего.
> устаревшее говно для хлебобулочных изделий
Тем не менее претрейн все только на нём делают, в то время как шизики не могу основы осилить.
> оверфите
С оверфита лор вообще проиграл.
>ooooeee hryuu vrete!! ты шизик, даже не тренирующий ничего!
Не визжи.
>все только на нём делают
Отучаемся говорить за всех. Если ты делаешь претрейн на говне, то это не значит что все делают на говне.
>С оверфита лор вообще проиграл.
Ну то есть ты там на адаме сидишь недотрениваешь говно своё (потому что адами не вывозит) и тольковыиграешь от этого? Так держать, верной дорогой.


> Отучаемся говорить за всех.
Выключай врёти, в transformers ровно два оптимизатора, потому что остальные не нужны. И уж тем более никто не использует пердольное говно от васянов.
> адами не вывозит
А ты можешь показать где твоё говно лучше AdamW? Я вот могу что не лучше, прямиком из их публикации. Точно так же могу обоссать тебя и показать как выглядит AdEMAMix с корректным lr.
В настоящих нейросетках локальных минимумов не существует, напоминаю. Ландшафт функции потерь имеет вид лабиринта и даже близко маняграфикам не соответствует.
Локальные минимумы появляются только когда делается градиентный спуск НЕ СТОХАСТИЧЕСКИЙ по всему датасету (один шаг - считаем градиент по всему датасету и так каждый раз заново), но так вы ничему путному не научите большую нейросетку, даже если представить что у вас на это есть компьют. Более того со стохастикой ландшафт вообще перестает быть стационарным.
Локальные минимумы появляются только когда делается градиентный спуск НЕ СТОХАСТИЧЕСКИЙ по всему датасету (один шаг - считаем градиент по всему датасету и так каждый раз заново), но так вы ничему путному не научите большую нейросетку, даже если представить что у вас на это есть компьют. Более того со стохастикой ландшафт вообще перестает быть стационарным.
> позволяющая и фуловый чекпоинт тренить на лоурам
Сильное заявление, кто-нибудь что-то с ним уже натренил, или это просто впечатление по теоретическому потреблению врам ценой замедления?
Особенно интересно как оно будет реагировать на всякие аугументации, манипуляции с лоссом и чуждые чекпоинту пикчи.
> fused_back_pass в kohya
Главный вопрос - он работает в мультигпу, или также как с адафактором/фьюзед группами отваливается нахуй? Если работает то даже запущу ради интереса.
> на DiT - AdEMAMix
По первым впечатлениям он хуже адамв (тем более на хл), разве что "добавить немного" не ломая ничего, а тренится довольно вяло. Но это ерунда, интересно увидеть конкретный успешный опыт его применения, штука то интересная. Алсо есть его производные в т.ч. с 8 битами.
> И это еще не 8бит, который вообще сосиот
Тут наоборот от 8битных в части случаев отказываются, а тут такое.
> только
А если по половине датасета - уже не появляются? А если по четверти? Так и до типичных батчей дойти можно, давай пруфы раз делаешь много заявлений.
> тренится довольно вяло
Челики у кохи пишут что быстрее у них тренится. Да и я заметил на Флюксе оно заметно лучше, особенно на больших датасетах.
>А если по половине датасета - уже не появляются? А если по четверти?
Для простейших примеров вот посмотри https://www.youtube.com/watch?v=dZuYwwyGc4Y&t=998s
На половине "датасета" уже ведет себя как стохастический градиентный спуск, а не не-стохастический.
Даже если взять батч 199 из датасета размером 200, градиентный спуск все равно переходит в стохастику https://www.youtube.com/watch?v=dZuYwwyGc4Y&t=1226s
На настоящих нейронках конечно цифры могут быть другими, но тенденция та же.
насколько чревато переименовывание файлов лор?
заебали уже всякие test_pook_srenk_000000012.safetensors
заебали уже всякие test_pook_srenk_000000012.safetensors
вроде всё ок. в вебуи при применении лоры используется некое внутреннее название, а не имя файла. но если что напишите, если я хуйню сотворил
В чем рисовались схемы на 1 и 5 пикчах? Это какой-то сервис или приложение? В гитбуке можно было вроде рисовать что-то похожее
>но если что напишите, если я хуйню сотворил
Да нет, всё верно. Сетка использует для идентификации модели/лоры её хэш, на него же смотрит цивитаи когда крепит к картинке лоры и модель.
Единственно, могут быть экзотические случаи протекания имени лоры с отсутствующим соответствием в промпт, если ты добавил его в Comfy ради того, чтобы он включил хэш лоры в метадату и её подцепил Civitai. Обычно промпт не загрязняется именем лоры даже в Comfy, похоже что нужны особые условия.
В вебуе два способа вызова лоры - с внутреннего идентификатора, и по имени. Переключаются в настройках.
Внутренний обычно выглядиткак раз как test_pook_srenk_000000012
Поэтому у себя я переключил на вызов с имени.
Но тут могут быть косяки с совместимостью при переносе на другую машину или в облако.
понял, спасибо
пойду всё переименоооооооооооовывать и упоряаааааааадачивать
если имя изменить - промт меняется?
>если имя изменить - промт меняется?
Если изменить имя и вызов по имени установить - да.
💰 Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Вышел официальный код и чекпоинты для MicroDiffusion от Sony.
Советую прочитать статью, в ней авторы подробно рассказывают о том, как они обучили модель уровня SD1 (MicroDiT) за $1890, используя диффузионный трансформер с MoE и наборы реальных+синтетических данных на 37M.
Теперь любой желающий может обучить модель Stable Diffusion v1/v2-уровня с нуля всего за 2,5 дня, используя 8 графических процессоров H100 (стоимостью < $2000)
Здесь (https://github.com/SonyResearch/micro_diffusion/tree/main/configs) можно посмотреть конфигурацию обучения для каждого этапа.
▪Paper: https://arxiv.org/abs/2407.15811v1
▪Github: https://github.com/SonyResearch/micro_diffusion
▪HF: https://huggingface.co/VSehwag24/MicroDiT
▪Dataset: https://github.com/SonyResearch/micro_diffusion/blob/main/micro_diffusion/datasets/README.md
Вышел официальный код и чекпоинты для MicroDiffusion от Sony.
Советую прочитать статью, в ней авторы подробно рассказывают о том, как они обучили модель уровня SD1 (MicroDiT) за $1890, используя диффузионный трансформер с MoE и наборы реальных+синтетических данных на 37M.
Теперь любой желающий может обучить модель Stable Diffusion v1/v2-уровня с нуля всего за 2,5 дня, используя 8 графических процессоров H100 (стоимостью < $2000)
Здесь (https://github.com/SonyResearch/micro_diffusion/tree/main/configs) можно посмотреть конфигурацию обучения для каждого этапа.
▪Paper: https://arxiv.org/abs/2407.15811v1
▪Github: https://github.com/SonyResearch/micro_diffusion
▪HF: https://huggingface.co/VSehwag24/MicroDiT
▪Dataset: https://github.com/SonyResearch/micro_diffusion/blob/main/micro_diffusion/datasets/README.md
Как всегда учитывают только стоимость трейнинг рана. Обычно в таких случаях в бутстрап/генерацию синтетики вбухивается куда больше суммарно.
заебись, скоро опять можно будет толкнуть свою 3060 за 1000 долларов
Там есть несколько нюансов. Первый - это батчсайз, сможешь ли ты сделать успешный претрейн с батчсайзом ниже 64 - загадка. Второй - датасет. С другой стороны это сильно лучше чем у понибляди, который за два месяца на таком же конфиге из 10хH100 натренил каких-то мутантов, при том что даже не с нуля тренил.
> с батчсайзом ниже 64
Для тренировки с шума даже 64 мало. Но с чекпоинтингом и/или аккумуляцией 64 можно хоть на одной H100 сделать. Если тренить анимублядство с нуля - там действительно сложно с датасетом ибо он оче несбалансированный с точки зрения знаний ирл и чего-то общего.
Аккумуляция градиентов вроде как от батч сайза таки ничем не отличается по результату, но гпт пишет может быть разница на сотнях-тысячах из-за ошибок округления. Как там на самом деле - хз.
Ошибки округления дождатся стохастик раундингом же, и еще кучей мокрописек
Какую функцию шума используют при оценке сэмплеров, чтобы понять, что картинка улучшается, а не превращается в соль с перцем?
Новое что-то придумал, или хуйню?
Обучение лоры/модели под адетейлер. Зашумляем латент не полностью, а квадратом внутри, рамка остается нетронутой. На рамку накидываем маску лосса.
Правка кода минимальна.
Обучение лоры/модели под адетейлер. Зашумляем латент не полностью, а квадратом внутри, рамка остается нетронутой. На рамку накидываем маску лосса.
Правка кода минимальна.
Ты придумал инпэйнт модели.
Ну я примерно так и подумал. Но если это так просто, то почему их никто не тренит? Какие есть проблемы с ними? Кривой инпеинт пиздец заебал.
>Но если это так просто, то почему их никто не тренит?
Потому что они делаются суммой дельты модели и SDXL с базовой инпэйнт моделью.
Вдобавок многие модели нормально инпэйнтят из коробки, и ничего изобретать не надо.




Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
https://github.com/bghira/SimpleTuner
Линукс онли, бэк отличается от сд-скриптс
https://github.com/Nerogar/OneTrainer
Фич меньше, чем в сд-скриптс, бэк тоже свой
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Flux
https://2ch-ai.gitgud.site/wiki/nai/models/flux/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
https://rentry.org/lora-is-not-a-finetune (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
NLP тэггер для кэпшенов T5: https://github.com/2dameneko/ide-cap-chan (gui), https://huggingface.co/Minthy/ToriiGate-v0.3 (модель), https://huggingface.co/2dameneko/ToriiGate-v0.3-nf4/tree/main (квант для врамлетов)
Оптимайзеры: https://2ch-ai.gitgud.site/wiki/tech/optimizers/
Визуализация работы разных оптимайзеров: https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Старая коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff - пони лоры
https://rentry.org/illustrious_loras_n_stuff - люстролоры
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/