


Сразу вопрос. Каким образом можно удалить знаки препинания из строки?
Есть ли что-то похожее?
SELECT функция(атрибут, знак препинания)
FROM таблица
СУБД oracle
Replace (stroka, ',')
sudo apt-get install mysql-server
он устанавливает, но не просит пароль, и я не могу войти под root. что не так?
он устанавливает, но не просит пароль, и я не могу войти под root. что не так?
У тебя полномочия администратора может быть?
Как я помню там не из под рута, а из под ассоциативного пользователя необходимо заходить или из под mysql
>он устанавливает, но не просит пароль, и я не могу войти под root. что не так?
sudo service mysql stop
sudo mysqld --skip-grant-tables --user=root
mysql -u root
и меняешь пароль.

Анон можешь дать пару советов и гайдов как вкатиться в sql?
Из скилов только знания уровня дауна С++ типа решения не сложных задач, которые были получены 10 лет назад и успешно забыты.
А сейчас короч мне нужно сделать базу данных для стоматологии похожую на оп пик, это реально ? скок времени это может занять?
Из скилов только знания уровня дауна С++ типа решения не сложных задач, которые были получены 10 лет назад и успешно забыты.
А сейчас короч мне нужно сделать базу данных для стоматологии похожую на оп пик, это реально ? скок времени это может занять?
>Анон можешь дать пару советов
Alan_Beaulieu-Learning_SQL-EN.pdf
Learning PostgreSQL by Salahaldin Juba.pdf
sql-ex.ru
>дауна С++
При чем тут это? Тебе сказали БД сделать или прямо все приложение с кнопочками и свистоперделками на пике?
>скок времени это может занять?
Это от тебя зависит
>Word не был активирован
лол
Откуда вообще тебе дали это задание и почему? забрал пик себе, тоже сделаю, для самопрактики
спасибо анон
> с кнопочками и свистоперделками на пике
было бы то что надо
>Откуда вообще тебе дали это
дали по работе, подробностей пока нету тк сам их не знаю надо звонить

О чем они? Я про последнее предложение. Почему 4 бэкслэша? При single quote это был бы один слэш, т.к. их не надо эскейпить вообще, при E'yoba' пришлось бы написать 2 слэша, т.к. в Е строках \ значит начало escape sequence. Но откуда 4 то блять. В обычной 'строке' ? Это документация постгреса если че

Внимание, господа бездельники и позеры, есть всем известное хранилилище редис и для чего его только не используют из-за его производительности.
Собственно, у меня как раз таки проблема с его производительностью скорее не его как хранилища, а его сетевой подсистемы, есть такая необходимость, читать и писать в него в много потоков с разных инстансов, а так как спроектирован он как однопоточное приложение, о конкурентном доступе можно забыть.
Соответственно, вопрос к господам знатокам, а если ли концепиуально похожее, легковестное in-memory хранилище не имееющее такого врожденного недостатка, как блокировка всего сервиса, пока выполняется один запрос?
Собственно, у меня как раз таки проблема с его производительностью скорее не его как хранилища, а его сетевой подсистемы, есть такая необходимость, читать и писать в него в много потоков с разных инстансов, а так как спроектирован он как однопоточное приложение, о конкурентном доступе можно забыть.
Соответственно, вопрос к господам знатокам, а если ли концепиуально похожее, легковестное in-memory хранилище не имееющее такого врожденного недостатка, как блокировка всего сервиса, пока выполняется один запрос?
имея нормальные требования - проектирование бд где-нить день, лучше два, реализация бизнес логики, гуйни на веб технологиях html+js+css python/go/php неделя-две в плюсах и десктопных технологиях у меня нет компетенций для оценки сроков.
Но, так как нормальных требований не будет да и меняться они будут по сто раз на дню, то от полугода до бесконечности.
tarantool?
Александр?
>tarantool
оно может быть и подойдет, но не хотелось бы держать такого монстра в проде только ради по сути большой хеш-таблицы (опционально распределенной).
смотрю пока на reindexer и кажется, что лучше ничего не найду
Сап, бигдаты. Я JS макака, вкатываюсь в бэкенд на node.js ага, я еще питон знаю - но это позже, да и не суть
Хочу освоить SQL.
Скажите с чего начать совсем нубарю? Какой учебник? Какая СУБД?
Как мне облегчить жизнь и обучение себе? GUI какое юзать?
Я вообще лошара в БД.
Хочу освоить SQL.
Скажите с чего начать совсем нубарю? Какой учебник? Какая СУБД?
Как мне облегчить жизнь и обучение себе? GUI какое юзать?
Я вообще лошара в БД.
POSTGRESQL
O
S
T
G
R
E
S
Q
L
Иди скачай книжку ицыка бен-ган, основы T-SQL.
Накати MS SQL, если нужно, напиши сюда, я скину тебе скрипт учебной базы лучше сам на торренте найди. После того как прочтёшь главу о подзапросах, пиздуй выполнять упражнения на сайте sql-exe. Дальше сам разберёшься.
Если тебе нужна реляционная теория больше чем просто одна глава, то читай Дейта.
>https://pastebin.com/rC3RAGTJ
>TABLE "thread"
>TABLE "thread_post"
>TABLE "post_answer"
что-то тут лишнее
>TABLE "user"
>TABLE "user_role"
- Регистрацию вводишь?
>TABLE "attachment"
>TABLE "post_attachment"
Зочем тут 2 таблицы? У тебя аттачменты всегда уникальные. Или ты собираешься проверять на уникальность при загрузке?

Посоветуйте годные видеоуроки mysql на ютупе желательно где больше практики показано.
работаю десять лет в DWH/ETL
спрашивайте ответы
спрашивайте ответы
тоже хочу работать, какой минимум нужен для работы ?
В какой сфере работаешь? Какая зп?
Пиздунок итт
минимум - это хорошо знать SQL и уже можно начинать вкатываться.
если не знаешь БД вообще, то читать какие-нибудь основы (дейт или чо там) дрочить sql-exe.ru. Скачать какую-нибудь Oracle(лучше), MS SQL. Почитать их документацию, потыкаться в них. Знать какие индексы есть нахуа они нужны. (хотя они зачастую в DWH не нужны, но долбоебы любят спрашивать). Чем OLTP база отличается от аналитической. Про етль можно почитать в data warehouse etl tookit кимбалла. Но лучше это делать с практикой, просто так туго будет заходить.
Проще всего, если в Рахе, то с одним SQL вкатиться в интегратор. Они набирают на эту тему пиздюков толпами. И потом уже на работе читать ньюансы, хоть понятно о чем будет речь.
Если погромист в душе, то лучше вкатываться в жабу. Там больше бабла и разнообразия.
делаю в телекомах и банках. Разный оракел/ексадату/терадату и прочий mpp задорого. Просто быдлокодер. Получаю оклад 165к и если с премией через год, то средне в месяц будет 210+.
Но такие зп у обычных ETL почти не бывают. Не стоит обольщаться. Больше 200 это уже у архитекторов, погоняльщиков рабов, РП-шек. Можно полуперекатиться в банке на полубизнес - отчетность, фрод, розничная аналитика, риски. Сидеть по сути клепать те же отчеты, только со знанием прикладной области, называться типа директор направления и получать до 250к. Ну это если более менее софт скилы есть.
В целом работа не матан. Местами примитивная. Хотя есть места, где на экспертизе можно выезжать из толпы. Если сыч и чисто технарь, лучше вкатываться в general purpose языки. Там больше бабла и веселей.
Какой лвл? Банковскую сферу долго осваивал? Видишь какие-нибудь перспективы?
35. Когда работаешь с двх так или иначе осваиваешь. Кто-то быстрее, кто-то нихуя.
Управлять рабами никогда не стремился. Если по тех стязе смотреть, можно стать арихтектором. Я им был некоторое время. Но он в банках в основном занимается тем, что долго хуесосится на митингах с дебилами, доказывая очевидные вещи. Пишет в ворд, рисует в визио и поверпейнт. зп 250-300к может быть. (столько может жаба кодер получать). Вакансий мало очень.
планы заниматься тем же за 200к. (основной план)
либо перекат в мл
либо перекат в жабу (если схуято уволят, что очень маловероятно)
либо перекат в гермашку
Тянок много было?
только трапы

sql sql slq slq slq slq slq slq slq slq
Привет!
помогите пожалуйста!
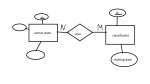
я хочу создать базу данных для сенсорных данных и классификаторов на них.
я создала entity сенсорные данные и entity классификатор, они соединены relationship "использует", n:m.
У сенсорных данных свои свойства, а у классификатора есть ещё свойство "тренировочные данные", где я планирую сохранять список id использованных сенсорных данных. Как 'то пометить? И я правильно всё сделала?
помогите пожалуйста!
я хочу создать базу данных для сенсорных данных и классификаторов на них.
я создала entity сенсорные данные и entity классификатор, они соединены relationship "использует", n:m.
У сенсорных данных свои свойства, а у классификатора есть ещё свойство "тренировочные данные", где я планирую сохранять список id использованных сенсорных данных. Как 'то пометить? И я правильно всё сделала?
>Использует
Лол
Только что написал тебе развёрнутый ответ, а потом увидел "сделала".
Скинешь сиськи?
только что сфоткалась красиво, а потом увидела, что ты анон с двача и.. напишешь как надо рисовать ер модель?

Перешёл на новое место работы как data ANALyst. Сразу же посадили хуярить репортинг (используется mysql + excel, больше нихуя). И тут стало известно что будут имплементировать Zeppelin (т.к. просто и бесплатный). Установил дома на локалку, почитал документацию, остались такие вопросы:
Насколько эта приблуда перспективна в плане отчётности и аналитики на уровне "мы вчера всё проебали\заработали"?
Насколько эта приблуда перспективна в плане отчётности и аналитики на уровне "мы вчера всё проебали\заработали"?
судя по стэку вы вчера заработали нихуя
надо работать там, где в репортинге используется ПО задорого. Там и бабла больше платят.
Это не отменяет самого вопроса.
Где успел поработать? Где больше всего платят?
посоветуйте книгу по mysql чтоб через 4 дня на интервьюшке не обосраться, плиз
Вот да очень интересует, что за 4 дня выучить, чтобы на интервью казаться неказуалом
делал хд в 4 банках из топ 5 кроме колхоза, в двух телекомах. работал в 2х интеграторах, в штате 2х банков и в телекоме. Больше платят в сбере сейчас.
Что хорошего посоветуете для вката в SQL
Хочу, по заветам пасты, написать свою борду.
Насколько для каждого раздела обоснованно создавать свою таблицу? Вроде это и поиск ускорит, и еблю с айдишниками постов снизит значительно (для каждого раздела свой счетчик номера поста).
Или лучше сделать составной первичный ключ из раздел+номер_поста?
Насколько для каждого раздела обоснованно создавать свою таблицу? Вроде это и поиск ускорит, и еблю с айдишниками постов снизит значительно (для каждого раздела свой счетчик номера поста).
Или лучше сделать составной первичный ключ из раздел+номер_поста?
Ето платиновый вопрос плоские таблицы vs таблицы со связями.
Коли хочеш изучять SQL -- выбирай второе.
Няши, поясните, а то сам не могу выбрать. Использую postgresql. Есть два стула:
1)Разбить все данные по схемам, в которых будет много-много небольших таблиц
2)Использовать одну схему, а данные разбить по таблицам, соответственно их будет не так много (несколько сотен), но они будут ОЧЕ большими - десятки (а то и сотни) тысяч строк.
Что лучше?
1)Разбить все данные по схемам, в которых будет много-много небольших таблиц
2)Использовать одну схему, а данные разбить по таблицам, соответственно их будет не так много (несколько сотен), но они будут ОЧЕ большими - десятки (а то и сотни) тысяч строк.
Что лучше?
> Насколько для каждого раздела обоснованно создавать свою таблицу?
Отвратительно. Разделы с точки зрения постов абсолютно одинаковые.
Таблица Board. В ней все разделы. К каждому разделу цепляются правила раздела типа размера картинок и прочей дрисни что надо. Также к каждому разделу делается сиквенс чтобы новые посты их дергали.
К Board один ко многим таблица Post. В ней суррогатный PK и номер поста в борде и FK к разделу. Это позволит делать нормальные ссылки на посты на других бордах без писек.
Кто не согласен, того обоссу.
Можешь юзать разные схемы если у тебя разные приложухи и реально они не пересекаются. Если приложуха одна, то не еби мозг и делай одну схему с нормальными таблицами и нормализацией.
> они будут ОЧЕ большими - десятки (а то и сотни) тысяч строк
Это вообще не размер. Просто вообще.
Шардирование для больших таблиц с идемпотентной аффинити-функцией от ключа если дорастешь до миллионов и миллионов, а на оракл денег не дают. Про бигдату же узнаешь если дорастешь.
> Это вообще не размер. Просто вообще.
Для какой-нибудь компании - вполне возможно, а у меня приложение для личного пользования. И когда я вижу что постгрес жрет 90% проца и 6 гб рамы, мне становится печально.
Но спасибо, не стал запариваться со схемами.
> 6 гб рамы
У каждого второго браузер жрет больше.
> постгрес жрет 90% проца
Что у тебя жрет 90% проца? Селекты? Нехуй фуллсканы по неиндексированным колонкам делать. Исправь и будет нормально работать.

> У каждого второго браузер жрет больше.
Ну так то на рабочем компе, где меньше 16 гигов по определению не бывает. А на домашний сервак, где и крутится дб, пришлось докупить еще 8 гб, а то он в своп уходил сразу же.
> Нехуй фуллсканы по неиндексированным колонкам делать.
В каком плане "неиндексированным"?
У меня колонки как на пике, и когда я делаю самый обычный запрос типа
"SELECT board, url, tag, notInteresting, dead FROM interesting_threads WHERE url = '"+num+"' AND board = '"+board+"';" хотя бы раз в секунду, начинаются просадки. Я конечно понимаю, что проблема еще и в том, что там стоит пень с 2 ядрами, но не на столько же все плохо должно быть.
> В каком плане "неиндексированным"?
В чем у тебя проблема я написал и слова для гуглинга тоже написал. Пиздуй гуглить и тогда решить свою проблему или иди нахуй и страдай.
Мать твою ебал.
Кекнул с дурачка.
мимокрокодил

Зарепортил шитпостинг.
Не забудь поставить минус в карму, долбоеб. Как можно использовать бд, но не знать про индексы? Уму блять непостижимо.

Бан.
Помог анонам выше забанить твою мать.



Анон нид хелп, это почти правильный код, где ошибки точно не знаю.он типа выдает результаты, но где то с нулами. Скажите на пальцах как это понимать и где можно посмотреть информацию по таким сложным техническим запросам или какие главы учебника почитать чтобы это понять и какого учебника?
я проходил только лоу уровень где связь только 2 таблиц джоинами, а тут их много и еще вложенные селекты ...
Это типа надо сделать отчеты для врачей по времени и по определенным случаем лечения, фотка задания на третьем пике. вторая это почти тоже задание только меньше столбцов и лучше видно таблицу сверху.
я проходил только лоу уровень где связь только 2 таблиц джоинами, а тут их много и еще вложенные селекты ...
Это типа надо сделать отчеты для врачей по времени и по определенным случаем лечения, фотка задания на третьем пике. вторая это почти тоже задание только меньше столбцов и лучше видно таблицу сверху.
Еще часть однотипных темповых таблиц по середине я удалил чтобы помещалось на скрине
быстрофикс
Аноны, работал кто-нибудь с монго дб?
У меныя тут запрос, который делает много lookup'ов, сторонних коллекций в основную. К сожалению пока я их не могу убрать, так что ищу советов по по оптимизации. К счастью все эти лукапы не зависят друг от друга и могли бы выполняться параллельно. Я перепробовал несколько решений, пока единственное работающее было - через $facet, но оно оказалось в 2 раза медленнее обычной последовательности лукапов. Может кто помочь?
> У меныя тут запрос, который делает много lookup'ов, сторонних коллекций в основную.
Ничего личного, но еще один пример когда ужа натягивают на ежа реляционные по природе данные натягивают в нереляционщину.
Сам знаю, но от осознания этого факта ничего не меняется. Изменение схемы данных займет слишком много времени и это никто не одобрит (да и насколько я вижу - это не особо возможно). ТАк что пока работаем с тем что есть.
>сложным техническим запросам
В каком месте они сложные?
для меня сложные, я 5 дней сикуэль изучаю. анон помоги плс, скажи где ошибки ?
хм может использовать Coalesce, чтобы не считал пустые значение, это поможет ?
Сап, анончики. Знаю, платина нахуя нужен apply? Чтоб понятнее, сколько гуглил - ниасилил.
мимо веб макака и не тяну SQL дальше оконных функций
мимо веб макака и не тяну SQL дальше оконных функций
Платиновый вопрос: кого можно называть разработчиком SQL, а кого аналитиком?
Я вот вообще просто работаю СПЕЦИАЛИСТОМ в банке. Но по факту строю витрины данных, пилю скрипты на PL для правильного переноса из одной системы в другую, иногда заливаю данные с помощью sqlldr, разрабатываю функции всякий парсинг, pipeline, пилю мониторинг систем рассылки там на почту при пиздецоме, пару раз проектировал всякую ебанину для новых проектов в БД. Ну и конечно сопровождаю все что написал. Работаю на оракле. И кто я? Разраб или аналитик все таки?
И сколько получают в среднем в ДС разрабы SQL? На hh забанили, хочу услышать мнение анонов
Я вот вообще просто работаю СПЕЦИАЛИСТОМ в банке. Но по факту строю витрины данных, пилю скрипты на PL для правильного переноса из одной системы в другую, иногда заливаю данные с помощью sqlldr, разрабатываю функции всякий парсинг, pipeline, пилю мониторинг систем рассылки там на почту при пиздецоме, пару раз проектировал всякую ебанину для новых проектов в БД. Ну и конечно сопровождаю все что написал. Работаю на оракле. И кто я? Разраб или аналитик все таки?
И сколько получают в среднем в ДС разрабы SQL? На hh забанили, хочу услышать мнение анонов
Бамп
С каким минимумом можно найти работу в дс2?
Съебись с треда, пожалуйста.

Получи сертификат на sql-ex.сру и можешь вкатываться
Или что?

Двощик, выручай! Есть постгрес установленный в сраный шиндоус. Тут вы меня захотите закидать тряпками, но это не я так хочу, юзер моего говнософта не сможет в линакс. Короче, я запустил инсталер, несколько раз нажал далее, инсталер сам создал юзера postgres, мой козырный пароль 1234, добавил в PATH каталог с бинарями C:\Program Files\PostgreSQL\10\bin. Теперь мне надо запилить тестовую базу данных шоб оттестировать работу на шинде, а она нихуя не создается. Двощик, помогай-выручай, что я делаю не так?
>что я делаю не так?
прова админа?
mysql_secure_installation
> юзер моего говнософта не сможет в линакс
А ты не умеешь в виндас. Кто из вас хуже, как ты думаешь?
Прив. Я совсем нуб, вкатываюсь фронта JS.
Развернул Microsoft SQL server, поставил SQL Server Management Studio.
Кое как прицепил к ней какую то учебную базу. И нихуя не понял.
Что куда и откуда.
НА этапе установки базы я задал (а точнее дефолтное оставил ) некоторое имя: MSSQLSERVER.
И где его юзать?
Когда запускаю SSMS - появляется окошко "Соединение с сервером" - и там ток из вариантов имя моей учетки компа. Короче пустой сервер.
Потом я подгрузил туда учебную базувыполнил скрипт ф5 нажал, лол и у меня во вкладке "Базы данных" появилась новая БД.
Я не оч понимаю менеджмент баз. У меня один сервер называющийся по моей учетке, да? В него я могу подгрузить самые разные БД, и все они отобразятся в вкладке "Базы данных"? И все они независимы будут?
Развернул Microsoft SQL server, поставил SQL Server Management Studio.
Кое как прицепил к ней какую то учебную базу. И нихуя не понял.
Что куда и откуда.
НА этапе установки базы я задал (а точнее дефолтное оставил ) некоторое имя: MSSQLSERVER.
И где его юзать?
Когда запускаю SSMS - появляется окошко "Соединение с сервером" - и там ток из вариантов имя моей учетки компа. Короче пустой сервер.
Потом я подгрузил туда учебную базувыполнил скрипт ф5 нажал, лол и у меня во вкладке "Базы данных" появилась новая БД.
Я не оч понимаю менеджмент баз. У меня один сервер называющийся по моей учетке, да? В него я могу подгрузить самые разные БД, и все они отобразятся в вкладке "Базы данных"? И все они независимы будут?
Такс, с тем что я выше написал - я разобрался. Сижу, пишу первые запросики.
Поясните за HDF5 и за перспективу замены баз данных ей
Ставь linux/mac nvm yarn и все остальное. А то ты не релевантный опыт получаешь
Держи нас в курсе, аноним.
Всем привет.
Какие вопросы по mysql вы можете задать, чтобы отличить сеньора от не-сеньора?
Я пока придумал три.
1) В чём отличие движков разных БД? InnoDB vs Mysql (trollface), Mysql vs MariaDB и причём тут Postgres? В чём отличия каждого из них при репликации?
2) Как устроен внутри поисковый индекс? Как он работает? Как это связано с составными ключами?
3) Есть колонка в таблице, в ней численные значения (1,5,6,10,xxx). Написать запрос, который выведет отсутствующие промежутки (1-5,6-10).
Какие вопросы по mysql вы можете задать, чтобы отличить сеньора от не-сеньора?
Я пока придумал три.
1) В чём отличие движков разных БД? InnoDB vs Mysql (trollface), Mysql vs MariaDB и причём тут Postgres? В чём отличия каждого из них при репликации?
2) Как устроен внутри поисковый индекс? Как он работает? Как это связано с составными ключами?
3) Есть колонка в таблице, в ней численные значения (1,5,6,10,xxx). Написать запрос, который выведет отсутствующие промежутки (1-5,6-10).
Да бля, я тут с SELECT WHERE ковыряюсь. Большего пока не нужно. На работке есть большая база на 5 млн. лиц. Моя работа прямо связана с работой в этой базе, и прогой что ею управляет. В перспективе я должен овладеть мастерством SQL, но жопу никто не жжет, поэтому вкатываюсь равномерно.
Лучше скажи - у меня на nodejs сайт есть, учебный. Хочу к нему прикрутить базу. MS SQL Server чет монструозно для этих целей выглядит. ЧТо легкое юзать?
Нахуй тебе в это вкатываться? У тебя есть писька, просто найди себе по богаче кого-нибудь и заделай личинок.

Ща найс трольну тред ИТТ.
ORM
ORM
There are No Girls on the Internet
Предполагаю, что чтобы найти кого-нибудь побогаче писка у него должна быть сильно побольше.
гайз, хелпа нужна. Есть допустим запрос.
select
from table
where 1=1
and field in (value1, value2, value3)
;
Можно ли как-нибудь заебенить:
set @variable = (value1, value2, value3);
select
from table
where 1=1
and field in @variable
;
????
select
from table
where 1=1
and field in (value1, value2, value3)
;
Можно ли как-нибудь заебенить:
set @variable = (value1, value2, value3);
select
from table
where 1=1
and field in @variable
;
????
Это в пхп тред.
Анон, как в PostgreSQL замутить следующее:
Есть article и article_tag.
Есть поисковик статей по тэгам.
Нужен запрос, чтобы найти статьи, у которых присутствуют все выбранные тэги.
Например:
article1 имеет tag1, tag2, tag3
article2 имеет tag1, tag2
в поисковике выбраны tag1, tag3
через оператора IN найдется и 1 и 2 статья, но у второй нет tag3, ее надо исключить.
вопрос: какой оператор нужен в условии?
Есть article и article_tag.
Есть поисковик статей по тэгам.
Нужен запрос, чтобы найти статьи, у которых присутствуют все выбранные тэги.
Например:
article1 имеет tag1, tag2, tag3
article2 имеет tag1, tag2
в поисковике выбраны tag1, tag3
через оператора IN найдется и 1 и 2 статья, но у второй нет tag3, ее надо исключить.
вопрос: какой оператор нужен в условии?


slow fix

А можно еще вот так, кажется, что так по-проще.
Постгрес накати. Лучше мускула, хуже промышленных гигантов типа оракла и мс, но быстрее в развертывании.
Сколько обычно платят ETL/DWH в ДС?
7,5 дошиков и стакан урины чтобо ополоснуть ебало
100-180к
спасибо! ключевое условие - подсчет приджойненых тэгов - помог.

Как вкатиться в БД и написать свою собственную?
зачем?
Он просто шизик, не обращай внимания.
ты просто пидор, я не обращаю внимания
зачем вопрос на вопрос отвечать?
бамп, "зачем?" - это не ответ на вопрос.
Просто хочу, надо вообще, показать куну, какой я крутой итд. Нужное сами выбирите.
Он либо шизик, либо жирный тролль.
я шизик-жирный-тролль.
Народ, какая БД используется в Вики-движке?
mariadb/postgres
Но можно и без движка?
ёп, без БД имел ввиду
Вряд ли.
затем, что если бы ты имел хоть малейшее представление о базах данных и о том как они устроены, ты бы не задавал этот дебильный вопрос.
>Zeppelin
Хуета хует так то. Накати хотя бы Tableau, спирать ее, думаю в твоей шараге похуй на это
table(article_id, article_tag)
select article_id
from table
where article_tag in ("tag1", ..., "tagN")
group by article_id
having count(*) = N
Что почитать по графовым БД?
Бля а где у вас шапка? С чего начать-то?
Собираюсь "для портфолио" подучить базы и лучшим вариантом будет PostgreSQL. С какой литературы начать?
Собираюсь "для портфолио" подучить базы и лучшим вариантом будет PostgreSQL. С какой литературы начать?

по литературе ап. тоже любопытны советы что почитать в начале
Давайте. Раз уж зашёл такой кутёж, то поделюсь тем, что я читал и советую всегда.
Мат.часть:
Гарсиа-Молина Г., Ульман Дж. Д., Уидом Дж.-Системы баз данных. Полный курс
есть книга "Проектированные Объектно-Ориентированных баз данных"
Oracle
Книги Тома Кайта ( есть книги для совсем новичков, есть книги про тонкости)
Gupta S. - Oracle Advanced PL SQL Developer Professional Guide
Хочешь обмазаться Oracle по полной и не замараться в говне и своих ошибках?
Фейерштейн С., Прибыл Б. - Oracle PLS.QL. Для профессионалов
Для богатеньких, и чтоб совсем обмазаться:
Покупайте книги Burleson'а ( потому что в интернете их обычно нет, особенно новых и самых нужных ( типа Advanced Oracle SQL Tuning))
Postgress:
Bartolini G., Ciolli G., Riggs S. - PostgreSQL Administration Cookbook ( средненькая такая книга для тех кто хочет обмазаться бэкапами и тонкими настройками)
Ibrar Ahmed, Gregory Smith, Enrico Pirozzi - PostgreSQL 10 High Performance ( тюнинг)
пограммирование на postgres -
Pavel Luzanov, Egor Rogov, Igor Levshin PostgreSQL for beginners
Regina Obe and Leo Hsu - PostgreSQL: Up and Running
Обмазаться основами:
так как дико модно молодёжно это Postgres
то, пусть будет
Е.Моргунов - Язык SQL. Базовый курс
ну, бля, проебался с разметкой.
А так кто будет шапку пилить, то добавьте всякие
hackerrank
sql-ex-шарашка
и оф.документация на русском и английском на доки постгресс( там практически все ответы на типичные вопросы, кроме ебучих задачек)
Еще нужно вбросить туда книги ицыка бен гана по мс скл.
+ Дейта
>Давайте.
На Тома Кайта дрочат в основном в рахе. Так как в издательстве пидер его стали певодить и выкидывать на развалы вот эти вот книжки в мягком переплете. В мире он просто какой-то Том. Нигде такой дрочи на него на англоязычных сайтах не видел. Хотя книги, наверное, неплохие.
Бурлесон это чувак со свинорылой аватарой, у которого его дрочь сайт почему-то вылезает в результатах гугола по запросу оракла. На сайте на тривиальные даются так себе ответы. У чувака образование - психолог. (это написано на его сайте же). Всегда считал его и его сайт каким-то смешным недороразумением в интеренте.
С Pavel Luzanov я работал в одном интеграторе. Он был манагером по какому скажут ИТ. Ничего о его великих познаниях в БД не слышал. Может он их скрывал. После того как он устроился в постргепрофешнл к Бартунову, стал вот книги писать. Ну ладно чё.
зы. Сам(я) ни одной книги по Ораклу не читал, кроме документации и интернетов. Мимокрокодил 200+к, был в том числе архитектором.
Спасибо тебе добрый человек.
Мне 27 и я экселедрочер, надеюсь это всё еще не поздно
А в двх хцфб не участвовал?
>хцфб
хомяк шоле?
нет
половина новичков надрачивает на Кайта, так как у него есть сайт asktom и он неебаца интегратор оракла был, потом стал каким-то директором в корпорации.
Свинорылый Бурлесон не сам пишет свой сайт, у него же целый комплекс идиотов, которые пишут ему и консультирует других, я Бурлесона не очень люблю, но иногда у него есть нужный материал.
Я вот не добавил, но можно добавить русскоязычные ораклдба и прочее, хотя сайты уже давно убил рак.
>потом стал
Кайт уволился из Оракла два года назад. Был он там типа вайс президентом - таких там штук двести может быть. На сайт асктом он не пишет лет десять. Его ведут какие-то нанятные редакторы из левых стран.
Оракл хотя и пока силён, теряет позиции. Могу говорить за двх. Его место медленно но верно занимают мпп, ин-мемори системы и прочие богомерзкие хадупы.
ну банковские системы и ИС пока любят оракл, хотя есть постгре, но второй не всегда в нагрузку может.
Аноны-ораклисты, а доводилось писать хранимки на Java? Уж больно стремный этот PL\SQL. Как там в 12 версии, работу с XML ускорили? Не нужно больше сохранять XML во временную таблицу чтобы он пободрее шевелился?
Банковские системы с DB2/Симетрикс/бигайронZ не слезают, правда только крупные от самого ZOG.
очнись. В этом году уже 18 версия будет.
Пиши на pl/sql. Он нихуя не страшный, это просто ты даун.
>>Как там в 12 версии, работу с XML ускорили?
Ты можешь xml инсертить без парсинга прямо в таблицу. Зачем что-то ещё?
Анонче, я в тебя верю
OCCI кто-нибудь курил?
Нужен способ реализации bulk collect для clob в ResultSet::setdatabuffer - а то некрасиво фетчить 5+к строк по одной и обрабатывать каждую.
В гугле полторы статьи и те для апдейта строк.
Или это делается через getvectorofclobs? Если да, то как в этом разобраться? Он же принимает строку коннекта, а не запрос.
Единственный случай в моей практике, когда в документации оракла нихрена нет практически, а приложениями на плюсах для оракла, видимо, три извращенца вроде меня занимаются, потому не могу найти годных примеров использованияя дурачок и не хочуне могу в джаву
OCCI кто-нибудь курил?
Нужен способ реализации bulk collect для clob в ResultSet::setdatabuffer - а то некрасиво фетчить 5+к строк по одной и обрабатывать каждую.
В гугле полторы статьи и те для апдейта строк.
Или это делается через getvectorofclobs? Если да, то как в этом разобраться? Он же принимает строку коннекта, а не запрос.
Единственный случай в моей практике, когда в документации оракла нихрена нет практически, а приложениями на плюсах для оракла, видимо, три извращенца вроде меня занимаются, потому не могу найти годных примеров использованияя дурачок и не хочуне могу в джаву
Про 18с слышал, но заказчик сидит на 11g.
На PL/SQL пишу много лет, я не говорил что он страшный - он стремный и примитивный, не развивается.
Вот и стало интересно, есть ли у кого опыт использования встроенной Java.
Но ты прав насчет дауна, вроде и опыт нормальный, но о 200+к я могу только мечать
Про XML вот пример:
https://pastebin.com/kEnbhLXM
В двух словах - если делать запрос из PL/SQL переменной xmltype, то он будет в разы медленнее чем запрос, который получает предварительно сохраненный xml из таблицы с колонкой xmltype.
Вот результат для XML из 5000 записей на 11g:
Запрос из переменной: 00:00:03.953000000
-------------
Запрос из таблицы: 00:00:00.062000000
В этом примере для таблицы время вставки не учитывается, с учетом вставки оно работает вдвое дольше, но все равно на порядки быстрее запроса из переменной.
Чем объемней xml, тем более впечатляющая разница.
Даже мелкобанки которые не даже в ТОП 100 по капитализации тоже на Оракле. Ебаться с постгресами нет времени и сил, когда есть обтесанный напильником Оракле.
Господа, а есть ли встроенный в эскуль способ сделать так, чтобы каждое значение в определённой таблице повторялось не более двух раз? Мускуль, если это важно.
На 3 пике все выглядит слишком сложно.
Есть. Having count(%column%) < 3.
Только правильно укажи группировку.
Ну у него скоро лицуха кончится.В этом году,например.
Пробовал xml-ку как базу соедтинять?
то есть file-db
Окей, спасибо большое.
Блджад, InnoDB не поддерживает инструкцию CHECK? О таком, чёрт побери, надо большими красными буквами поверх названия писать, зря только ебался. Придётся на уровне приложения реализовывать. Ссаное говно.

Сап аноны, есть одна сущность таблица.
Там есть два атрибута столбца. Один - действие, второй - отмена действия.
Подскажите алгоритм, который выведет последнее неотменённое действие.
Там есть два атрибута столбца. Один - действие, второй - отмена действия.
Подскажите алгоритм, который выведет последнее неотменённое действие.
select from (select from table
Where cancel is null
Order by counter desc)
Where rownum = 1;
Ну либо select top 1 with ties, если субд поддерживает.


Анонче, на первом пике процедура, на втором запрос к ней.
Вопрос, что это за конструкция такая N'O'?
Я в sql не особо шарю просто, но нужно к этой процедуре через entity framework обращаться, и поэтому нужно понять, как работает.
Подскажите, пожалуйста.
Вопрос, что это за конструкция такая N'O'?
Я в sql не особо шарю просто, но нужно к этой процедуре через entity framework обращаться, и поэтому нужно понять, как работает.
Подскажите, пожалуйста.
В табличке инфа о многих людях. Также действие может быть не отменено.
Сразу об этом надо писать, я откуда знаю, что тебе с группировкой надо.
Если оракл - то keep first агрегатный или row_number().
Если нет - то группировка по людям с having count = max (count) с условием cancel is null.
Что значит твое "действие может быть не отменено"?
Не отмененное действие - null в строке, такой гарантированно будет как минимум один для человека, судя по твоей таблице, потому что назначение действия соответствует null.
Если ты слегка перепутал клавиши и "действие может быть отмененно" в последней строке, то я не вижу проблемы - либо ничего не надо выводить (фильтрацию по null вводишь запросом сверху), либо надо вывести предыдущее - тогда ничего не надо менять.
А ещё бы лучше оригинальный текст задания дал.
Анон, помоги написать запрос. Я только только вкатился и никак не могу написать запрос под такое задание:
Нужно вывести информацию о велосипедах у которых 6 скоростей И на которых можно ездить вдвоем.
Высрал примерно следующее, но естесна это не работает:
SELECT DISTINCT
FROM Tab1
JOIN Tab2 ON Tab1.ID = Tab2.CarID
WHERE Count = 6
AND
EXISTS (SELECT ID, COUNT() FROM Tab1 GROUP BY ID) = 2)
Нужно вывести информацию о велосипедах у которых 6 скоростей И на которых можно ездить вдвоем.
Высрал примерно следующее, но естесна это не работает:
SELECT DISTINCT
FROM Tab1
JOIN Tab2 ON Tab1.ID = Tab2.CarID
WHERE Count = 6
AND
EXISTS (SELECT ID, COUNT() FROM Tab1 GROUP BY ID) = 2)
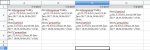
Есть табличка в excel'е, там sheet примерно такого вида (пик). Много колонок, много строк. Каждый день приходит выхлоп, который туда заносится в новую колонку.
Хочу все это дело перенести в sqlite.
Использовать собираюсь python и pandas.
Нужно будет запрашивать инфу по номеру и рисовать графики.
Например: сегодня у нас в 0098 g123, а месяц назад было g87, нарисовать график того, как изменялось за месяц в 0098, сколько номеров с выросшим g за 3 месяца и пр.
Или
Вывести список номеров где вчера было g меньше 100, но у которых в названии есть Test.
1) для каждого номера table (0023, например), внутри rows с date,
и columns с распарсеной инфой (num, name, ip etc)
2) для каждого числа table, а внутри уже данные?
Как в панде сделать индексом первую row колонки?
Времени читать книжу о том как дизайнить базы правильно нет.
Хочу все это дело перенести в sqlite.
Использовать собираюсь python и pandas.
Нужно будет запрашивать инфу по номеру и рисовать графики.
Например: сегодня у нас в 0098 g123, а месяц назад было g87, нарисовать график того, как изменялось за месяц в 0098, сколько номеров с выросшим g за 3 месяца и пр.
Или
Вывести список номеров где вчера было g меньше 100, но у которых в названии есть Test.
1) для каждого номера table (0023, например), внутри rows с date,
и columns с распарсеной инфой (num, name, ip etc)
2) для каждого числа table, а внутри уже данные?
Как в панде сделать индексом первую row колонки?
Времени читать книжу о том как дизайнить базы правильно нет.
Может ли в MYSQL триггер активироваться и от UPDATE и от INSERT, или нужно лепить два разных триггера?
всем привет, я тут новенький
а что вы здесь делаете?
а что вы здесь делаете?
В шапку https://pgexercises.com/
Оказывается эта N означает Unicode. Пидарасы, сказать не могли? Или вы настолько ничтожные, что даже этого не знаете?

Можно еще как-то вот так через массивы извратиться
чтобы джойнить функции с таблицей

анон помоги
есть приложение для бд
рабочее
но
при добавлении новых данных все данные дублируются
удаление прописано но не работает
https://pastebin.com/w12JcR9Y
есть приложение для бд
рабочее
но
при добавлении новых данных все данные дублируются
удаление прописано но не работает
https://pastebin.com/w12JcR9Y
Да
что исправить?
Ебани триггер.

Анончик, а есть какие-то отказустойчивые SQL решения, но что бы это не овердорогущий Oracle, и не дорогущий MS SQL Server?
Наш заказчик очень хочет что бы у него было всем прям мега отказоустойчивым, поэтому сует Кассандру в каждую дырку, аргументируя это тем, что она спокойно переживает внезапные падения узлов.
Но хранить в кассандру данные, для которых явно нужна реляционка - та еще боль. Пикрилейтед.
Посему вопросец: если ли какие-то реляционные решения, толерантные к падению? Вот что бы прям можно было потерять узел, и не заметить этого с точки зрения клиента. Посгрес и мускуль не имеют нормальных мастер-мастер связок. А для варианта мастер-слэйв, насколько я знаю, нужен сторонний механизм мониторинга и переключения узлов, что как бы тоже анально.
Вроде как RDS че-то умеет, но это клауд решение.
Наш заказчик очень хочет что бы у него было всем прям мега отказоустойчивым, поэтому сует Кассандру в каждую дырку, аргументируя это тем, что она спокойно переживает внезапные падения узлов.
Но хранить в кассандру данные, для которых явно нужна реляционка - та еще боль. Пикрилейтед.
Посему вопросец: если ли какие-то реляционные решения, толерантные к падению? Вот что бы прям можно было потерять узел, и не заметить этого с точки зрения клиента. Посгрес и мускуль не имеют нормальных мастер-мастер связок. А для варианта мастер-слэйв, насколько я знаю, нужен сторонний механизм мониторинга и переключения узлов, что как бы тоже анально.
Вроде как RDS че-то умеет, но это клауд решение.
Вот потому Oracle столько и стоит, что это нифига не просто сделать.
> отказустойчивые SQL решения
Постройте отказоустойчивый кластер с живой миграцией. Делов то. Только придется потратиться на vmware esxi, vCenter и кучу другого. Либо на попен сорсе выезжать, но там боль.
>если ли какие-то реляционные решения, толерантные к падению
Посмотри в сторону индеец зажигай. Поддерживает реляционку, джоины (как локал, так и дистрибьютед) и как кассандра мастер-мастер хуячит. Фактор репликации решаешь для каждого кэша (таблицы) сам, хоть полный репликейтед. И в отличие от кассандры нет диких проблем, что должно быть 50% свободного места быть, или рипейр фейлед. Ну и порешали проблемы с получением неконсистентных данных при развале кластера.
Но это все же не оракл и не поддерживаются констрейнты и если у тебя ехал джоин через джоин по сабквери, то лучше потеститься.
Алсо можешь посмотреть в сторону тараканбд, но не юзал.
Поясните пожалуйста где я не прав в 16 упражнение на sql-ex
Вот пишу такое, на первой бд проходит, но второй нет.
select p.model, k.model, p.speed, p.ram from pc p inner join pc k on p.speed = k.speed and p.ram = k.ram and k.model < p.model
Прочитал их хелп топики, но там ничего толком не сказано.
Вот пишу такое, на первой бд проходит, но второй нет.
select p.model, k.model, p.speed, p.ram from pc p inner join pc k on p.speed = k.speed and p.ram = k.ram and k.model < p.model
Прочитал их хелп топики, но там ничего толком не сказано.
В голос с дебила
distinct ты забыл
Зы, ОП ты ещё тут сидишь ? Как дела?




Хелп, пытаюсь освоить SQL, есть такие задания ,
Всё норм, я тут.
Зачем нужна монга?
Зачем нужно что-то, когда есть постгрес?
> Зачем нужна монга?
Чтобы смузихлебы с разработанными и отбеленными анусами чувствовали себя комфортно и могли писать запросы на жабоскрипте.
Да уж, от жса меня сначала знатно перекосоебило. Но я про подходящие модели данных. Не могу представить ни одной, где не нужна реляционность.
>где не нужна реляционность
Там где данные, внезапно, неоднородны.
Например, хранение метаданных (ключ-значение) у некоторых сущностей.
Не, накрутить реляционность можно и в таком случае. Но нужно ли?
Давай конкретные примеры.
Ты ебобо?
>Например, хранение метаданных (ключ-значение) у некоторых сущностей.
Еще конкретнее.
google: EAV
Спасибо, а я прочитал первый ответ и расстроился, пошел смотреть уже опять книжки читать, видео смотреть..
умеет в шардирование, в отличии от постгреса
Двош помоги. 1 как происходит добавления новых индексов? Они же типа хранятся отсортированные и получается чтобы добавить новый нужно смешать все остальные? 2 если в таблицы поменять один тип колонки на другой который требует больше места ( int - bigint например ) происходит смещение данных во всей таблицы? Поясните за эти вопросы аноны или дайте где почитать
> Двош помоги. 1 как происходит добавления новых индексов? Они же типа хранятся отсортированные и получается чтобы добавить новый нужно смешать все остальные?
Да, потому вставка в таблицы с несколькими индексами замедляется, потому что приходится перестраивать его сегменты
>2 если в таблицы поменять один тип колонки на другой который требует больше места ( int - bigint например ) происходит смещение данных во всей таблицы? Поясните за эти вопросы аноны или дайте где почитать
Думаю, зависит от реализации - оракл, например, не даст тебе сменить тип данных не пустого столбца (следовательно - у не пустой таблицы). А так - да, скорее всего перестроит начальный сегмент таблицы, чтобы запись влезала в блок
Есть у меня база MSSQL с таблицей с кучей говна данных, порядка 1488 GB. Структура Id, A int, B bit и куча других. Так вот, мне нужно сделать поиск говна данных по A, у которых B = 1. Я добавил индекс на A, есть ли смысл делать его и на B? Или нужно сделать один индекс, который включает в себя два столбца? Помогите, с меня как всегда нихуя
>следовательно - у не пустой таблицы
Тип у пустого столбца можно спокойно менять в непустой таблице:
create table yoba as
select cast (null as number) a, level b from dual
connect by level < 11;
-- Add/modify columns
alter table YOBA modify a varchar2(12);
Partial index.
Посоветуйте с чего начать изучать базы данных? Какие книги? Важно ли изначально определиться с СУБД или это не так важно? Может курсы есть какие-нибудь?
sql-ex.ru
postgers
Анон, есть таблица, в которой около 150 столбцов. я делаю из нее селект и потом должен сформировать строку аля
"UPSERT INTO "tabl"."prod" VALUES (values for record 1);
...
UPSERT INTO "tabl"."prod" VALUES (values for record n);
"
Как мне это все дело перебирать? Нашел курсор, но там нужно ему задать столбцы, по которым идет переборка, а мне 150 вручную бить не охота.
в sql полный ноль, всю жизнь на шарпе писал, а сейчас решили процедуру для говнонода заебошить.
"UPSERT INTO "tabl"."prod" VALUES (values for record 1);
...
UPSERT INTO "tabl"."prod" VALUES (values for record n);
"
Как мне это все дело перебирать? Нашел курсор, но там нужно ему задать столбцы, по которым идет переборка, а мне 150 вручную бить не охота.
в sql полный ноль, всю жизнь на шарпе писал, а сейчас решили процедуру для говнонода заебошить.
Бен Форта "Освой самостоятельно SQL за 10 минут". Для начинающих самое то
Спасибо. А какую СУБД выбрать? Макрософт - это нормальный выбор?

ЧЯДНТ?
хочу создать таблицу, занести в нее пару значений, вывести все в аутпут.
код пикрилейтед.
пишет "саксесфулли", нихуя не происходит. (рефреш таблиц делал)
хочу создать таблицу, занести в нее пару значений, вывести все в аутпут.
код пикрилейтед.
пишет "саксесфулли", нихуя не происходит. (рефреш таблиц делал)

пиздец, скобки после varchar не поставил. блять это невыносимо. нет ли какой нибудь номальной проги чтобы с пострес работать? эта даже синтаксис не проверяет блять ссука.

Почему бы не использовать ОРМ того языка на котором ты говнокодишь с использованием этой базы?
Например на Питоне есть отличный SQLAlchemy.
Ты не очень сообразительный, да?
Тебе же написали: postgres.
Все, забил хуй, сделал выгрузку из базы и скрафтил все через js. Ебал я эти базы.


Есть два select-a которые возвращают таблицы с одинаковыми(кроме последнего) столбцами, которые надо объединить в одну таблицу сгруппированную по полю name.
Пикрелейтед - результат выборки, результат второго селекта такой же, только там "col_2" вместо col_1.
Пикрелейтед 2, то что я получаю используя FULL OUTER JOIN second_table ON first_table.name = second_table.name , но проблема в том что оно джоинит не все записи из второй таблицы (т.е. есть строки где col_2 = <nul> но нету где col_1=<nul>, а они должны быть), где я проебался, не тот join использую или что ?
Бд - postgresql
Пикрелейтед - результат выборки, результат второго селекта такой же, только там "col_2" вместо col_1.
Пикрелейтед 2, то что я получаю используя FULL OUTER JOIN second_table ON first_table.name = second_table.name , но проблема в том что оно джоинит не все записи из второй таблицы (т.е. есть строки где col_2 = <nul> но нету где col_1=<nul>, а они должны быть), где я проебался, не тот join использую или что ?
Бд - postgresql
А все, сам разобрался уже

Помогите, пытаюсь выбрать максимальное значение из таблицы, но их там несколько, и sql выбирает только первое максимальное, на остальные ему пофиг, как это можно поправить?
ya dolboyob, zachem to napisal price vmesto speed...
Анон мне надо поставить точки в конце разных фраз разных строк. Как это можно сделать в майсикуэле?
Как ты определяешь, что фразе пришёл конец?
А разве не должен выбирать одно?
Ты даже в постановке задачи на Дваче написал
>пытаюсь выбрать МАКСИМАЛЬНОЕ ЗНАЧЕНИЕ из таблицы
Сформулируй номрально задачку.
Датагрип, сычуш

В моем случае, если после символа(буквы) во фразе не стоит другой символ или пробел, то это конец фразы.
Не понял, я тебе помочь хочу, ответь нормально.
Что такое датагрип, в терминах май скл, непонятно.
>после символа не стоит другой символ или пробел
Приведи пару примеров, ни хуя непонятно
Ну например есть столбец text varchar 512. В нем фразы по типу 'Сап, двач'. Эта фраза состоит из букв, символов(,) и пробелов. Буква "ч" в слове двач- конец фразы, потому что после нее нету ни пробела, ни буквы, символа.
я правильно понимаю, что тебе надо поставить точку после последнего символа?
Если да, то
>select concat(text, '.') from t_data
Если нет, то ты крайне хуево умеешь выражать свои мысли.
> Всем привет.
> Какие вопросы по 2ch вы можете задать, чтобы отличить ньюфага от долбаеба?
> (trollface)
В общем, долблю сайт в задний конец на PHP. Есть таблица с пользователями, таблица некоторых актов, связанных с этими пользователями, и рейтинги участия пользователя в акте, идущие отдельной таблицей. Подскажите, к можно на Секелях выбрать среднее значение рейтинга для конкретного пользователя и отсортировать их по нему?
>таблица с пользователями - d_usr (id, name)
>таблица некоторых актов - d_act (id, name)
>рейтинги участия пользователя в акте - t_usr_act (usr_id, act_id, usr_rating)
>SELECT
>u.id,
>u.name,
>avg(ua.usr_rating) as avg_usr_rating
>FROM d_usr u
>LEFT JOIN t_usr_act ua ON u.id = ua.usr_id
>GROUP BY
>u.id,
>u.name
>ORDER BY avg_usr_rating DESC
Премного благодарен, буду пробовать.

Базач, помоги оптимизировать запрос.
Есть запрос с двумя JOIN, который отрабатывает за доли секунды. Понадобилось мне еще одно поле из другой таблицы, дописал еще LEFT JOIN по двум полям.
Запрос стал выполняться 25 секунд. Все таблицы небольшие, по 2000-5000 строк в каждой. В результирующем наборе 5к строк.
Был запрос такой, быстрый:
SELECT ma.answer_id, m.date, ma.percentage FROM measuring_answers ma INNER JOIN answers a ON a.poll_id = АЙДИ_ОПРОСА AND a.id = ma.answer_id LEFT JOIN measurings m ON m.id = ma.measuring_id ORDER BY date;
Стал такой, медленный:
SELECT ma.answer_id, m.date, ma.percentage, mp.votes FROM measuring_answers ma INNER JOIN answers a ON a.poll_id = АЙДИ_ОПРОСА AND a.id = ma.answer_id LEFT JOIN measurings m ON m.id = ma.measuring_id LEFT JOIN measuring_polls mp ON mp.measuring_id = ma.measuring_id AND mp.poll_id = a.poll_id ORDER BY date;
Я с базами на вы, поэтому во всех базах первичный ключ - это просто id. Теоретически в таблице measuring_polls первичным ключом может быть связка measuring_id + poll_id - эта комбинация всегда уникальна. Но я такое еще не умею, и не знаю, будет ли так быстрее.
Есть запрос с двумя JOIN, который отрабатывает за доли секунды. Понадобилось мне еще одно поле из другой таблицы, дописал еще LEFT JOIN по двум полям.
Запрос стал выполняться 25 секунд. Все таблицы небольшие, по 2000-5000 строк в каждой. В результирующем наборе 5к строк.
Был запрос такой, быстрый:
SELECT ma.answer_id, m.date, ma.percentage FROM measuring_answers ma INNER JOIN answers a ON a.poll_id = АЙДИ_ОПРОСА AND a.id = ma.answer_id LEFT JOIN measurings m ON m.id = ma.measuring_id ORDER BY date;
Стал такой, медленный:
SELECT ma.answer_id, m.date, ma.percentage, mp.votes FROM measuring_answers ma INNER JOIN answers a ON a.poll_id = АЙДИ_ОПРОСА AND a.id = ma.answer_id LEFT JOIN measurings m ON m.id = ma.measuring_id LEFT JOIN measuring_polls mp ON mp.measuring_id = ma.measuring_id AND mp.poll_id = a.poll_id ORDER BY date;
Я с базами на вы, поэтому во всех базах первичный ключ - это просто id. Теоретически в таблице measuring_polls первичным ключом может быть связка measuring_id + poll_id - эта комбинация всегда уникальна. Но я такое еще не умею, и не знаю, будет ли так быстрее.
Приложи лучше планы запросов до и после.
Эх, спасибо за удочку.
Убил джва часа, но разобрался с explain, почитал про индексы, настроил логирование медленных запросов.
Сделал CREATE INDEX measuring_id_polls ON measuring_polls(measuring_id, poll_id); и теперь запрос выполняется за десятую долю секунды.
Аноны, разбираюсь с бд, конкретно с postgresql. Вот у меня есть таблица с id пользователей в базе (допустим, это мои друзяшки из вкшки, которых я вчера вытащил из апи). Сегодня я, допустим, часть их удалил, часть добавил, вот я снова вытаскиваю список id из api и хочу его актуализировать в базе. Как это лучше сделать? Удалить все записи и внести их заново?
Или вот я хочу удалить часть записей каких-то с определенными id. Как это лучше сделать? Тупо в цикле по запросу на id? Или писать один запрос, а в него подставлять в цикле по условию на id, чтобы результат был типа
... WHERE user_id = 1 OR user_id = 2 и т.д.
Гуглю и не могу найти таких примеров что-то, только по диапазону идентификаторов.
Или вот я хочу удалить часть записей каких-то с определенными id. Как это лучше сделать? Тупо в цикле по запросу на id? Или писать один запрос, а в него подставлять в цикле по условию на id, чтобы результат был типа
... WHERE user_id = 1 OR user_id = 2 и т.д.
Гуглю и не могу найти таких примеров что-то, только по диапазону идентификаторов.
Секелюшники, подскажите, хули MySQL выёбывается на это:
ALTER TABLE Хуи AUTO_INCREMENT = (SELECT MAX(номер) FROM Хуи) + 1
Короче, удаляю элемент и хочу немного поубавить автоинкремент, если он пропускает лишние значения в конце.
ALTER TABLE Хуи AUTO_INCREMENT = (SELECT MAX(номер) FROM Хуи) + 1
Короче, удаляю элемент и хочу немного поубавить автоинкремент, если он пропускает лишние значения в конце.
Спешите видеть, макака не может в сиквел.
>Удалить все записи и внести их заново?
Очевидно, глупое решение.
В целом, если у тебя вкшный id - PRIMARY, либо хотя бы UNIQUE, то можешь просто добавить всех друзей заново в существующую таблицу. Старые просто не добавятся, ибо такой id уже существует. Новые - добавятся.
В случае же если требуется еще сделать UPDATE старых друзей (например, мало ли сменилось имя), то делаешь UPDATE, если INSERT закончился неудачей.
>то делаешь UPDATE, если INSERT закончился неудачей
Открой для себя ON CONFLICT DO UPDATE ...

При чём тут "не может"? Вопрос был о том, почему автоинкременту можно присвоить только число.

Анчоусы, у меня опять траблы с производительностью.
Я настроил логирование медленных запросов (более секунды), и периодически вижу там COMMIT, занимающий 3 секунды, или даже простой INSERT INTO measuring_polls (measuring_id, poll_id, votes) VALUES('чиселко', 'чиселко', 'чиселко'), занявший полторы секунды.
За COMMIT скрывается около десяти простеньких INSERT, типа такого, что повыше. Инсерты идут из цикла foreach, потому что похапешный PDO не умеет мультиинсерт на массиве неизвестной длины, как я понял. Некоторые заканчиваются фейлом из-за дублирующегося UNIQUE, так было задумано.
Далеко не каждый коммит и тем более инсерт попадает в лог, только некоторые. Это как-то фиксится или это просто лаги жесткого диска при записи?
Я настроил логирование медленных запросов (более секунды), и периодически вижу там COMMIT, занимающий 3 секунды, или даже простой INSERT INTO measuring_polls (measuring_id, poll_id, votes) VALUES('чиселко', 'чиселко', 'чиселко'), занявший полторы секунды.
За COMMIT скрывается около десяти простеньких INSERT, типа такого, что повыше. Инсерты идут из цикла foreach, потому что похапешный PDO не умеет мультиинсерт на массиве неизвестной длины, как я понял. Некоторые заканчиваются фейлом из-за дублирующегося UNIQUE, так было задумано.
Далеко не каждый коммит и тем более инсерт попадает в лог, только некоторые. Это как-то фиксится или это просто лаги жесткого диска при записи?
ALTER TABLE Хуи AUTO_INCREMENT = SELECT MAX(номер) + 1 FROM Хуи
попробуй
До пизды (в т. ч. со скобками, в которые берётся подзапрос):
> #1064 - У вас ошибка в запросе. Изучите документацию по используемой версии MySQL на предмет корректного синтаксиса около '(SELECT MAX(номер) + 1 FROM Хуи)' на строке
Вы не охуели мешать DDL и DML в одном запросе? В переменную и EXECUTE IMMEDIATE
Так пишешь, будто в этом есть что-то плохое. Секелям не похуй ли, в одном я запросе это сделаю или так:
> $последний_номер = $БД->Запросить_ячейку('SELECT MAX(номер) FROM Хуи');
> $БД->Выполнить_запрос('ALTER TABLE Хуи AUTO_INCREMENT = ' . ($последний_номер + 1));
Результат тот же, только кода больше и запроса два.
Ты сейчас сделал 2 запроса к БД, вместо одно, как было до этого. Дебил.
Дебил тут ты, а не я. По-моему, я об этом и пишу. Или ты думаешь, тот запрос выполняется? Долбоёба слепошарого кусок.
> Очевидно, глупое решение.
Да я тоже не в восторге, но это первое что пришло в голову.
> просто добавить всех друзей заново в существующую таблицу.
id уникальные, но не primary. С добавлением всё более-менее понятно, только вот при конфликтах primary key инкрементируется всё равно. Почитал интернеты, оказалось, что так и задумано, только вот не понял, стоит ли с этим бороться или забить.
Вопрос больше про то, как лучше удалить сразу несколько записей по id, которые не идут друг за другом.
Пока вот такую конструкцию придумал:
> DELETE FROM friends WHERE friends.user_id IN (SELECT * FROM unnest(%s))
И вторым аргументом в execute() список id пользователей, которых хочу из таблицы убрать. Он лист преобразует в array постгрес и подставит в запрос. Вроде работает, но правильно ли так делать?
Представь себе, не похуй. Потому что dml запрос будет выполнять движок, который о ddl знает ровно столько же, сколько ты о базах данных. Естественно он нижняя тебе не посчитает и пошлёт нахуй с ошибкой синтаксиса.
> нижняя
Ничего
Еще вопрос: вот у меня есть таблицы:
> users: id (pk), vk_id, name
> artists: id (pk), name, genre
> users_artists: user_id, artist_id, tracks_num
То есть, я собираю таблицу с друзяшками, таблицу с исполнителями из аудиозаписей всех друзяшек и таблицу, в которой содержится инфа у какого пользователя какие исполнители в аудиозаписях и сколько треков этих исполнителей. Естественно в последней таблице ни одно поле не является уникальным, но уникальным зато является сочетание (user_id, artist_id). Я хочу при одновременном совпадении обоих полей обновлять поле tracks_num, но INSERT ON CONFLICT выдает ошибку
> there is no unique or exclusion constraint matching the ON CONFLICT specification
Я так понимаю, ON CONFLICT работает только с теми полями, у которых есть аттрибут UNIQUE. Помоги, анон, пожалуйста. Никак не могу сообразить как в моем случае написать запрос, чтобы не было дублирующихся сочетаний. То есть, если в последней таблице уже есть пользователь с id n и у него уже есть исполнитель с id m, то не вставлять еще одну запись, а у существующей обновить поле tracks_num.
> users: id (pk), vk_id, name
> artists: id (pk), name, genre
> users_artists: user_id, artist_id, tracks_num
То есть, я собираю таблицу с друзяшками, таблицу с исполнителями из аудиозаписей всех друзяшек и таблицу, в которой содержится инфа у какого пользователя какие исполнители в аудиозаписях и сколько треков этих исполнителей. Естественно в последней таблице ни одно поле не является уникальным, но уникальным зато является сочетание (user_id, artist_id). Я хочу при одновременном совпадении обоих полей обновлять поле tracks_num, но INSERT ON CONFLICT выдает ошибку
> there is no unique or exclusion constraint matching the ON CONFLICT specification
Я так понимаю, ON CONFLICT работает только с теми полями, у которых есть аттрибут UNIQUE. Помоги, анон, пожалуйста. Никак не могу сообразить как в моем случае написать запрос, чтобы не было дублирующихся сочетаний. То есть, если в последней таблице уже есть пользователь с id n и у него уже есть исполнитель с id m, то не вставлять еще одну запись, а у существующей обновить поле tracks_num.
Что за СУБД? По идее, за исключением случаев блокировок, сам commit должен выполнятся мгновенно(данные уже на диске/в буфере).
Нет, дело лишь в хуёвой реализации языка запросов.
Аноны, каким простым запросом можно удалить из таблицы все записи, где данные повторяются в одной колонке?
MySQL 5.6.40
>Select id from tbl_table_with_id where id = (select max(id) from tbl_table_with_id)
Поясните что не так?
А что не так? Кроме того, что достаточно одного подзапроса.
если в кратце, MariaDB Это тоже самое, что MySQL
Что перспективнее ставить на свои проекты- MySQL или PostgreSQL?
Что перспективнее ставить на свои проекты- MySQL или PostgreSQL?
Сап, аноны. Не пинайте сильно, поясните, будьте добры, за принципы ACID в бд.
Если происходит транзакция, допустим на изменение, затрагивающая множество связанных данных, и в этот момент параллельно происходит запрос, допустим на чтение, какого-то подмножества из этих данных, что должно происходить
1) Запрос на чтение будет ожидать окончания транзакции?
-- 1.1) А если транзакция выполняется ну пиздец как долго (в теории), часы-сутки-недели?
2) Запрос на чтение не будет ожидать окончания транзакции и
-- 2.1) Окончится ошибкой
-- 2.2) Получит данные, которые были до начала транзакции
Если происходит транзакция, допустим на изменение, затрагивающая множество связанных данных, и в этот момент параллельно происходит запрос, допустим на чтение, какого-то подмножества из этих данных, что должно происходить
1) Запрос на чтение будет ожидать окончания транзакции?
-- 1.1) А если транзакция выполняется ну пиздец как долго (в теории), часы-сутки-недели?
2) Запрос на чтение не будет ожидать окончания транзакции и
-- 2.1) Окончится ошибкой
-- 2.2) Получит данные, которые были до начала транзакции
Ты хоть бы в вики заглянул. Зависит от уровня изоляции транзакций.
>MySQL или PostgreSQL?
BUMP
Postgres
Oracle
Тупой вопрос от новичка.
Есть две таблицы:
FUNDS с полями id, name, comment
BALANCE с полями id, fund, balance
Поля BALANCE.fund и FUNDS.id связаны по primary-foreign key (в балансе fk, в фунде - pk)
не могу найти, как мне делать селеет так, чтобы в запросе типа
SELECT fund,balance FROM BALANCE у меня вместо айдишников было FUND.name. Я подозреваю, что это какой-то типа JOIN но я тупой и не могу составить запрос. Возможно ли это вообще?
PostgreSQL, есличо
Есть две таблицы:
FUNDS с полями id, name, comment
BALANCE с полями id, fund, balance
Поля BALANCE.fund и FUNDS.id связаны по primary-foreign key (в балансе fk, в фунде - pk)
не могу найти, как мне делать селеет так, чтобы в запросе типа
SELECT fund,balance FROM BALANCE у меня вместо айдишников было FUND.name. Я подозреваю, что это какой-то типа JOIN но я тупой и не могу составить запрос. Возможно ли это вообще?
PostgreSQL, есличо
select name, balance
from balance
inner join funds
on balance.fund = funds.id;
join разных типов бывает, посмотри, какой подходит тебе
Этого более чем достаточно!
Огромное тебе спасибо, добрый анон!
Я пока ковырялся, пришел к такому вот решению:
SELECT id,(SELECT name from funds where funds.id = balance.fund) as balance FROM balance;
Так нельзя сделать? Чем Join лучше?
Блин, криво вставил кусок, правильно так:
SELECT id,
(SELECT name from funds where funds.id = balance.fund) as fund,
balance FROM balance
SELECT id,
(SELECT name from funds where funds.id = balance.fund) as fund,
balance FROM balance
Это тоже джойн, по факту.
Но лучше переделай на джойн и все будет так красиво
Ок, спасибо за науку!
Вообще в оракле, например, построится план запроса как для джойна обычного - то есть что ты сделаешь через поздзапрос, что через левое соединение - разницы не будет
Только твой вариант упадет, если вдруг нарушено ограничение целостности в таблице funds и найдется несколько записей на один id
Так как у тебя свзяка pk/fk ничем, план скорее всего одинаковый построится, но вообще, такие подзапросы могут возвращать не одну строку, а несколько, и тогда всё поломается. Плюс он более трудный для понимания.
он же ПЛАТНЫЙ? не?
Нищий что ли?
А в этом ИТТ только реляционки?
Зачем какой-то конторе тратиться на платную БД, когда можно развернуть элитный проект на PostreSQL - и ничего не потерять?
Да, я нищук. Но даже будь у меня большие деньги на проект, я бы не стал просто так тратиться на БД

Сап, pr
Может кто-нибудь простым языком объяснить суть уровней изолированности объяснить, чтобы решать такие задачи как на пикрил. Ну и посоветовать годноту по теории, конечно.
Пиздец блядь, 2 года с базами работаю, а теорию не знаю, стыдно.
Может кто-нибудь простым языком объяснить суть уровней изолированности объяснить, чтобы решать такие задачи как на пикрил. Ну и посоветовать годноту по теории, конечно.
Пиздец блядь, 2 года с базами работаю, а теорию не знаю, стыдно.
Все от СУБД зависит. В книжках Тома Кайта и Ицыка Бена Гана всё это расписано.
Вторую бегло читал, шоб писать код и чтобы получать 150к/нс мес. Видимо пропустил.
Сможешь простыми словами это объяснить?
Там целая глава.
Пиздос. Пойду ковырять мсскл. А ответ какой должен быть на задачу?
Не слушай его.
От СУБД зависит то, какие поддерживаются уровни изоляции, но теория - она одна.
Очень просто.
Грязное чтение(read uncommitted) - твои изменения видны всем в любой момент, даже если они не зафиксированы.
Обычное чтение(read committed) - всем видны только зафиксированные данные.
Повторяющееся чтения(я бы сюда и фантомные отнес, repeatable/phantom reads) - если в пределах транзакции ты делаешь агрегированный запрос в момент времени т1, потом другая транзакция в момент т2 меняет какие-то данные и фиксирует их, то если ты запускаешь этот же запрос в момент т3, ты должен получить такой же результат, будто никаких изменений не было. Фантомные чтения - то же самое, только без агрегации: селект всех строк в т1 и в т3 абсолютно идентичен, даже если в момент т2 кто-то добавил новую строку и закоммитил инсерт. То есть одна штука за апдейты отвечает, вторая за инсерты, а смысл один - во время транзакции одинаковые селекты в разное время дают одинаковый результат.
Сериализованные транзакции - всегда пишут, что якобы транзакции выстраиваются в ряд и система становится однопользовательской, а все зависит от базы. Оракл, например, образно говоря, делает тебе снэпшот базы на момент начала транзакции и кто бы что не делал, ты будешь видеть ее только в таком виде до конца транзакции, но нюансы связаны с оракловской реализацией, так что в общем сказать не могу.
Притом, если две транзакции не будут трогать одни и те же строки, то вставка в таблицу на основании ее же данных становится очень интересной, инфу об этом я нарыл вроде в оракловской документации.
Вроде понятно описал, если что - постараюсь объяснить подробнее и понятнее.
Спасибо, стало намного более понятно, именно этого и хотел.
А как такие задачи решать с этими знаниями?
Столкнулся с тем, что надо будет перетягивать базу оракла в mssql раз в неделю. Какой самый простой путь? Сделать пакет шоб тащил, думаю несложно, но на сервак наверное кучу аддонов надо нахуярить? (2014 стоит). Алсо, можно ли в оракле права доступа на селект для сервака с мс прописать?
Представлять то, о чем написано.
Открылась транзакция, поменяла данные и до коммита две другие транзакции читают эти же данные.
Read uncommitted увидит единицу, а read committed увидит ноль. Почему - я расписал выше.
Я понял, спасибо. Само задание на уровни первый раз вижу, с запросами проблем не было.

ИТТ Батя Т-Скуль, овер 12 лет в профессии
Задавайте ваши ответы, если есть желание.
Читни Ицика Бен Гана, пидор.
Задавайте ваши ответы, если есть желание.
Читни Ицика Бен Гана, пидор.
Какой наиболее простой по нагрузке способ в MSSQL заменить значения на выводе, если они меньше X?
Насколько использование CTE для повышения читаемости тормозит запросы? Стоит злоупотреблять?
Алсо посоветуй гайдов как работать с R в MSSQL.
Как перекатиться с этого всего на бигдату?
>Для повышения читаемости
если сравнивать подхапросы и cte, то это одно и то же.
злоупотреблять не стоит, конечно, как начнёшь большой сте с другим сте дожойнить, хотя бы 50 000 строчек в каждом, то поймёшь, что что-то не так.
Спасибо, анон
Как научиться оптимизировать запросы, чтобы понимать как их ускорить?
Научиться разбирать план запроса
Мои собственные изыскания показали, что на бигдату перекотиться можно только по случаю и по знакомству. Я так пони, что в Мск биг дата тема хайповая, и тут половина людий сами не знают что за биг дата и что с ней делать. Я, в итоге, забил на бигдату и покатился в фулстак.
Торадиционного варианта с "читни книг катай видосы" тут нет, хотя бы потому, что БИГ дату ты у себя на коферарке дома не поднимешь. Для БИГ даты нужны БИГ компании. А им, в свою очередь, нужны готовые спецы которые будут делать работу сдесь и сейчас, а не чуваки которые может и перспективны, но на отрезке полгода-год.
Обзаводись знакомствами, гоняй на семинары и конференции, может через расширение круга знакомств ты и придешь к успеху.
Я не работаю с Р
Что значит "заменить значения на выходе", обизян, а?
Учись внятно формулировать свой вопрос; правильно
составленный вопрос -- половина ответа на него.
>Насколько использование CTE для повышения читаемости тормозит запросы? Стоит злоупотреблять?
Зависит какое ЦТЕ. Лично я считаю, что использовать ЦТЕ "для повышения читаемости" ебаное дно.
ЦТЕ нужно для очень конкретных вещей, например для рекурсии. Если ты что-то другое хочешь делать через ЦТЕ, остоновись и ПОДУМОЙ почему. Если ты делаешь это не внутри инлайн фунции, с вероятностью 99% ты делаешь это напрасно.
В оставшемся проценте случаев ты пишешь ЦТЕ, потому, что задачу вменяемо можно решить только через него.
Ставишь просмотрщик планов от скульсентри
https://www.sentryone.com/plan-explorer
В отличие от ебаной параши, которая встроена в SSMS, сразу тебе показзывает нагрузку, потоки данных, узкие места и миллион метки.
Дальше смотришь какие операции жрут у тебя максимум от твоих запросов
Дальше смотришь свой код, и ДУМОЕШЬ как можно избежать этих узких мест.
Ну посмотри какие нить базовые видосики по "Understanding a SQL Server execution plan"
>если сравнивать подхапросы и cte, то это одно и то же.
Я включу зануду, и отмечу, что для протокола. С огромной долей вероятности интерпретатор построит для НЕРЕКУРСИВНОГО ЦТЕ и для соответсвующего подзапроса абсолютно одинаковые планы. Но бати пишут, что бывают случаи, когда планы получаются разные.
Лично я с таким эффектом не встречался, по краней мере не помню, чтоб были какие-то спецэффекты, которые заставили бы меня делать выбор между цте и подзапросом.
Однако нюансы, всеже, важны.
Есть тут спецы по DB2? Имеется множество таблиц и один MQT. Этот MQT построен на джойнах этих таблиц. Поставили в продакшен, и теперь, если обновляется одна из таблиц, входящая в MQT, то этот MQT не обновляется сам.
Собсна, 2 вопроса.
1. Какого хрена не обновляется и зачем эта фича тогда вообще нужна?
2. Как решить проблему? Неyжели нельзя просто сделать виртуальную таблицу, которая обновляет информацию вместе с реальными?
Прошу прощения за неровный почерк, я не дб админ, а всего лишь ДЖЕЗВА девелопер.
Собсна, 2 вопроса.
1. Какого хрена не обновляется и зачем эта фича тогда вообще нужна?
2. Как решить проблему? Неyжели нельзя просто сделать виртуальную таблицу, которая обновляет информацию вместе с реальными?
Прошу прощения за неровный почерк, я не дб админ, а всего лишь ДЖЕЗВА девелопер.
Сколько раз херил инфу без бэкапа?
Аноны, есть таблица в БД, и мне нужно добавить к 2 столбцам ON DELETE SET NULL;. Как мне это сделать не снося таблицу к хуям и не создавая заново?
p.s. PostgreSQL 10.
p.p.s. Хотя бы подскажите как загуглить ибо ничего не нашёл.
p.s. PostgreSQL 10.
p.p.s. Хотя бы подскажите как загуглить ибо ничего не нашёл.
>Как мне это сделать не снося таблицу к хуям и не создавая заново?
А этот вариант чем не устраивает? Сколько данных в таблице?
Данных немного, но они постоянно в движении, новые приходят/уходят и т.д.
Короче разобрался как сделать.
ALTER TABLE ..... ALTER CONSTRAINT ...и тут вот определил ON DELETE SET NULL;
Совсем без бэкапа ни разу, парочку раз были острые проебы которые успел восстановить из параллельных источников.
Кто-нибудь знает как подключить R/Python к MS SQL шоб можно было простейший мл хуярить?
Select from tbl_table_with_id where id = (select max(id) from tbl_table_with_id)
Посоны, такое можно упростить как-нибудь?
inb4 select , max(id) from tbl_table_with_id
Посоны, такое можно упростить как-нибудь?
inb4 select , max(id) from tbl_table_with_id
Select звездочка from tbl_table_with_id where id = (select max(id) from tbl_table_with_id)
inb4 select звездочка, max(id) from tbl_table_with_id
Зелект топ (1) ид фром парашанейм оедер бай айди деск
Откуда блдяь вы такие беретесь?
рассыпалася на групбаях из за звездочки, ебобо
Как называется такая архитектура?
1
В одной базе около 10 таблиц, в них содержится
dbo.users, dbo.items, dbo.something, dbo.else и тд
2
Во второй базе около 9000 таблиц, названия которых содержат:
dbo.users, dbo.items429219_0, dbo.items231452_1, dbo.items23125252, dbo.items_myitem и так далее
На какую сам сядешь, на какую мать посадишь?
1
В одной базе около 10 таблиц, в них содержится
dbo.users, dbo.items, dbo.something, dbo.else и тд
2
Во второй базе около 9000 таблиц, названия которых содержат:
dbo.users, dbo.items429219_0, dbo.items231452_1, dbo.items23125252, dbo.items_myitem и так далее
На какую сам сядешь, на какую мать посадишь?
Мне в идеале надо конвертировать все таблицы 2го типа в таблицы 1го вида...
В плане оптимизации и выборок может 2я лучше, но 1я удобнее для разработки
Так у тебя во втором случае партицированые таблицы, как я понимаю? Там же доступ к ним ничем не отличается от обычных, это просто вопрос хранения, не?
>партицированые таблицы
спасибо, это слово я искал
Ладно, теперь встала проблема в оптимизации.
в программе, условно, 9 кнопок. Каждая кнопка выплевывает по 1000 селектов, естественно с задержками.
Как правильно делать селекты, чтобы пользователь не ощущал задержек?
в программе, условно, 9 кнопок. Каждая кнопка выплевывает по 1000 селектов, естественно с задержками.
Как правильно делать селекты, чтобы пользователь не ощущал задержек?
Читать планы запросов, мониторить нагрузку на систому ввода вывода, переписывать свои ебаные селекты чтобы они вменяемо работали, ИНДЕКСЫ накрутить
Делать ПРЕДРАСЧЕТЫ
Ты сейчас реально очень глубокий вопрос задал, в режиме "хочу чтоб было заебись"
Что за пользователи, что за каналы связи? Что за хранилище данных?
>Читать планы запросов, мониторить нагрузку на систому ввода вывода, переписывать свои ебаные селекты чтобы они вменяемо работали, ИНДЕКСЫ накрутить
>Делать ПРЕДРАСЧЕТЫ
>
>Ты сейчас реально очень глубокий вопрос задал, в режиме "хочу чтоб было заебись"
>
>Что за пользователи, что за каналы связи? Что за хранилище данных?
MSSQL standalone :)
Каналы 100мбит\с
Пользователи - макаки
Не,я не кокнретно хотел ответ услышать. Мне там похуй какие у тебя каналы.
И вообще может у тебя и сто мегабит, а читаешь ты с ебаного китайского харда с иолатчем 70
Или крутится твой стандалоне на каком нибудь пентиум ммх
Я просто тебе хотел ПОКАЗАТЬ, что вопрос "ой чет у нас медленно , а надо быстро" требует пиздец какой глубокой проаботки
Но вообще, начни вот с чего
Ебани аналитику от Глена Берри по отсутствующим индексам и статистике топовых ЗАДЕРЖЕК системы
http://sqlcom.ru/dba-tools/express-diagnostic-ms-sql-server/
Умный какой. А на оракле что делать?
В оркале ордербаи и топ отменили? Это спецификация языка, макак
>
>Не,я не кокнретно хотел ответ услышать. Мне там похуй какие у тебя каналы.
>
>И вообще может у тебя и сто мегабит, а читаешь ты с ебаного китайского харда с иолатчем 70
>
>Или крутится твой стандалоне на каком нибудь пентиум ммх
>
>Я просто тебе хотел ПОКАЗАТЬ, что вопрос "ой чет у нас медленно , а надо быстро" требует пиздец какой глубокой проаботки
>
>Но вообще, начни вот с чего
>
>Ебани аналитику от Глена Берри по отсутствующим индексам и статистике топовых ЗАДЕРЖЕК системы
>
>http://sqlcom.ru/dba-tools/express-diagnostic-ms-sql-server/
>
Спасибо, за вечер не разобрать. ._.
>А, лол, оракл макаки не могут в топ
Зато у нас (+) вместо километров join лапши.
И да, where rownum=1 order by ;
> В оркале ордербаи и топ отменили? Это спецификация языка, макак
Как вы живёте, блядь?

сап анон
такая проблема
на мой замыленный взгляд написал join корректно, но ide почему-то ругается на ключевое слово select, я хз что это может быть
небольшое описание:
MySQL
две бд и три таблицы
1) db_default -> tb_user, tb_logins
2) db_billing -> tb_operations
такая проблема
на мой замыленный взгляд написал join корректно, но ide почему-то ругается на ключевое слово select, я хз что это может быть
небольшое описание:
MySQL
две бд и три таблицы
1) db_default -> tb_user, tb_logins
2) db_billing -> tb_operations
Ничего не знаю о SQL, но попробуй первый аргумент писать на той же строке.
У тебя гроуп бай по одному полю, а без формул ты выводишь 3.
если совсем убрать grop by, то проблема не уходит
Ну значит у тебя там выше залупа какая то
Поставь ; перед SELECT
А меня вот, например, в 11 строке запятая в конце смущает
а блядь, и точно
какая запятая между джойнами? рука лицо
В современном проектировании БД используются триггеры? Просто учусь в шараге по методичке 2005 года, и сервер тоже старый.
Зависит что проектируешь.
Если говорить о МС скульсервере, есть задачи, которые принципиально не решить без триггера.
Прежде всего это всяческое логирование.
Но вообще взрослые дяди стараются свести использование триггеров по минимому, потому, что это все довольно непрозрачные механизмы. Особенно те,которые INSTEAD OF
В общем, административные задачи в триггеры _можно_ если иначе никак.
НУ например DDL логи.
Все остальное лучше делать без триггеров. Особенно все то, что относится к модификации данных.
О! Есть еще один хитровыебанный кейс, когда ты делаешь механизм, который позволяет прервать и откатить батч по свистку, типа IF (1=2) EXEC dbo.AbortAll
Там тоже нужен триггер-шмиггер
мимо-батя-скуля
Перепощу из ньюфаг-треда, может, кто-то сможет ответить, и да, я осознаю, что этот тред о SQL, но он единственный тематический.
Изучаю NoSQL на PouchDB, что-то не очень понимаю, как работают коллекции. Давайте с простым примером и-магазина, есть коллекции заказов и товаров, разумеется, они должны быть связаны, и насколько я понимаю, в документах заказов уже имеет смысл хранить товары, потому что заказ без товаров сам по себе бесполезен. Я правильно понимаю, что в NoSQL БД не существует некоего волшебного механизма, который при изменении документов товаров автоматически обновит документы в коллекции заказов? В RxDB и Mongoose есть population, если знаете, как это работает (в поле документа одной коллекции указывается отсылка на конкретные документы в другой коллекции, и при конкретном запросе БД их подтягивает в первую коллекцию), но я не уверен, что правильно так делать.
Изучаю NoSQL на PouchDB, что-то не очень понимаю, как работают коллекции. Давайте с простым примером и-магазина, есть коллекции заказов и товаров, разумеется, они должны быть связаны, и насколько я понимаю, в документах заказов уже имеет смысл хранить товары, потому что заказ без товаров сам по себе бесполезен. Я правильно понимаю, что в NoSQL БД не существует некоего волшебного механизма, который при изменении документов товаров автоматически обновит документы в коллекции заказов? В RxDB и Mongoose есть population, если знаете, как это работает (в поле документа одной коллекции указывается отсылка на конкретные документы в другой коллекции, и при конкретном запросе БД их подтягивает в первую коллекцию), но я не уверен, что правильно так делать.
Вот я хочу добавить запись вида (первое поле, второе, третье). Но оно добавится, только если первое поле уникальное. Как можно сделать такой запрос? И, если желательно, в одну строку.
Причем тут запрос? У тебя констрейнт уникальности на поле
первое_поле нужен.
Блин, ну я ж помню, что как то через запрос делал. А сейчас, к сожалению, все проебал.
Еще рас, сукА, селект это ОПЕРАЦИЯ ПРОЕКЦИИ, ты не управляешь в селекте проверками на уникальность и прочее
Ты можешь заказать
"инсерт инто залупа_тейбл селект хуйня, молофья фром парашатейбл вере ... (и вот тут параметры отбора)"
но это _не_ ограничения вставки
ПыСы
Если тебе нужно проверить что запись только одна
SELECT
T1.WannaBeDistinct as Field1
, T2.Field2
, T3.Field3
FROM
Table1 T1 ... Table2 T2
... WHERE
NOT EXISTS (
SELECT 1 FROM Table1 TT WHERE TT.PkID = T1.PkID
)
Жаль конечно, что так получается, ну да ладно. Спасибо!

анон, подскажи как можно запихнуть символ рубля в таблицу?
создал таблицу с полем CurrencySign:
CurrencySign VARCHAR(20) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
пытаюсь вставить символ в виде кода U+20BD - а нихрена не появляется символ
как решить проблему?
создал таблицу с полем CurrencySign:
CurrencySign VARCHAR(20) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
пытаюсь вставить символ в виде кода U+20BD - а нихрена не появляется символ
как решить проблему?
Аноны, расскажите как кто-нибудь из этого треда к успеху пришел, начав с нуля.
СУБД какая?
> Аноны, расскажите как кто-нибудь из этого треда к успеху пришел, начав с нуля.
Всё зависит от того, что для тебя успех.
Все просто: выучил с нуля, грубо говоря и смог устроится.
CSV файл через ODBC на ХР.
mysql и hsqldb
>>128156
Привет, какую абс пилишь? Что так поздно за приказ цб схватился?
Привет, какую абс пилишь? Что так поздно за приказ цб схватился?

Еще вопрос все по тем же СУБД
Могу ли я создать таблицу, где Person будет выводиться как конкатенация FirstName и Surname из другой таблицы? Если да, то как это сделать?
DROP TABLE PERSONS IF EXISTS CASCADE;
CREATE TABLE PERSONS (
ID BIGINT GENERATED BY DEFAULT AS IDENTITY (START WITH 1 INCREMENT BY 1) NOT NULL,
FirstName VARCHAR(20) NOT NULL,
Surname VARCHAR(20) NOT NULL,
PRIMARY KEY (ID)
);
DROP TABLE BOOKS IF EXISTS CASCADE;
CREATE TABLE BOOKS (
BID BIGINT GENERATED BY DEFAULT AS IDENTITY (START WITH 1 INCREMENT BY 1) NOT NULL,
PersonNumber BIGINT NOT NULL,
Person VARCHAR(40) NOT NULL, /PERSONS.FirstName + PERSONS.Surname/
PRIMARY KEY (BID),
FOREIGN KEY (PersonNumber) REFERENCES PERSONS(ID) ON DELETE CASCADE
);

Ну я выучил с нуля и пришел к успеху. Если конечно считать за успех 160 к/мес и функцию архитектора КХД
Фест нейм варчар 20
Ласт наейм варчар 20
мидлнейма нет
Откуда вы такие уебки лезете, а?
Вот придет к тебе Муххаммад ибн Мусса ибн Федайкин Абу Аль Хорезми и что ты делать будешь, уеба, со своими варчар 20?
> Вот придет к тебе Муххаммад ибн Мусса ибн Федайкин Абу Аль Хорезми и что ты делать будешь
Я охуею и выбегу из здания.
Миддл нейм не нужен. Мухаммад Хорезми он, жи есть.
Не можешь ты сделать таблицу такую. Сделай вьюху из 2 своих таблиц.
Если извращенец, то напиши функцию, которая по айдишнику персоны достает из таблицы персон нужные тебе фио и создать в саоей таблице вычислимое поле на основе айдишника персоны и этой функции. Но работать все будет медленно.
Что нужно читать, чтобы понять структуру DWH?
Инмана и Кимболла, конечно же.
А так - что ты хочешь узнать из их утверждений? Реальное хранилище не будет полностью повторять описанную структуру.
Чтобы понять, нужно знать, что есть транзакционная система, данные из которых ты грузишь в хранилище и преобразуешь к такому виду, чтобы бизнесу было удобно их читать.
А как ты их там держишь - это уже полет твоей фантазии, хоть в нереляционной базе или переписываешь на бумажки и отправляешь ящиками в архив.
Если серьезно - один предлагает хранить данные в ядре в нормализованном виде и отдавать бизнесу в денормализованных витринах(читай: OLAP-кубы), а второй - в денормализованные витрины грузить из OLTP систем.
На самом деле, можно что-то среднее между теориями Инмана и Кимболла использовать - грузить данные сразу в нормализованные витрины.
Кимбала читай, Имана не читай.
У Кимбала две книжки , одна более обзорная другая более конкретная с приемами чо почем
Kimball & Ross : The Data Warehouse Toolkit
Kibmall: The Data Warehouse Lifecycle Toolkit

PS
Если ананас подскажет мне анонимную файлопомойку, могу скинуть обе пдфки туда.
Я в свое время знатно поебался, чтоб найти их в хорошем какчестве.

>На самом деле, можно что-то среднее между теориями Инмана и Кимболла использовать - грузить данные сразу в нормализованные витрины.
Братишко, скажи подалуйста, как у тебя в голове укладываются в одном словосочетании противоположенные по смыслу термины?
По мне, так "нормализованнные витрины" это такой же оксюморон как "женская логика" или "политическая порядочность"
Рыгхост

Можно подробней пожалуйста.
Аноны, а подскажите, что почитать, чтобы быстро выучить основы бд?
Так вышло, что прогал не используя бд вообще, а сейчас на любой вакансии их требуют.
Алсо хотелось бы разобраться в разнице sql и nosql, когда какие стоит применять и тд.
Так вышло, что прогал не используя бд вообще, а сейчас на любой вакансии их требуют.
Алсо хотелось бы разобраться в разнице sql и nosql, когда какие стоит применять и тд.
https://github.com/codedokode/pasta/blob/master/db/databases.md
Главным отличием sql и nosql является соответствие ACID.
sql должен соответствовать всегда, nosql может соответствовать "в перспективе" (данные доедут, но потом).
>Главным отличием sql и nosql является соответствие ACID.
>sql должен соответствовать всегда, nosql может соответствовать "в перспективе" (данные доедут, но потом).
Мне бы понять разницу в применении. Условно говоря, для каких задач можно только nosql, для каких только sql, для каких оба подходят, но что-то больше
Анонасы, вопросик есть. Вот написал я небольшое веб-приложение Java+Spring+Hibernate с постгресом, БД и таблицы создавал в pgAdmin. Ну и по стандарту сделал application.properties и в нём прописал url/username/password. Запуск с IDE и jar-ника у меня работает нормально.
Но что делать другому человеку, который скачает мой репозиторий и захочет у себя из IDE запустить? Что мне нужно прописать в таком случае? Ему ведь нужно будет изменить url/username/password на свои, но ведь у меня есть таблицы, а у него, получается, их не будет? Я немного не понимаю этот момент.
Но что делать другому человеку, который скачает мой репозиторий и захочет у себя из IDE запустить? Что мне нужно прописать в таком случае? Ему ведь нужно будет изменить url/username/password на свои, но ведь у меня есть таблицы, а у него, получается, их не будет? Я немного не понимаю этот момент.
Не в том треде вопрос задаешь.
В доке по спрингу все расписано https://docs.spring.io/spring-boot/docs/current/reference/html/howto-database-initialization.html
Hibernate может создать таблицы автоматически hibernate.hbm2ddl.auto=create, но это НЕ рекомендуется делать на реальных проектах (хотя я делал в своей говнокоторе ибо всем похуй).
Можно просто положить в ресурсы файлик schema.sql, если используешь spring boot.
Можно использовать инструменты миграции такие как Flyway или Liquibase.
Спасибо, няш.
Ну после института взяли подмастерьем в банк, там стал более менее скуль погромистом, потом двигался от конторе к конторе, растил скилл и кругозо по предметным областям. Мотал на ус как разные айти конторы решают определенные спектры задач.
В 2006 работал за 45 в 2009 за 65 в 11 зв 85 ну и так далее до посейчас за 160+- четотам. Пошел на проект где людям надо было поднимать КХД, убедил их что справлюсь, ну и вот ...

Обращайся

Репост из реквест треда, потому что тут фундаментальных дедов побольше.
Вот есть разные вебфреймоврки.
Но все они так или иначе реализуют шаблон MVC.
Вопрос. Можно ли что то изучить непосредственно по мвс, оторванное от конкретной реализации, что бы потом было менее болезнено менять технологию?
Вообще что можете посоветовать изучить что бы смена языка, фреймворка, или технологии была менее болезнена.
Так то заметил что ООП везде более или менее одинаково.
Структуры данных почти везде одни и те же.
Алгоритмы вообще от языка не зависят и им десятки лет.
Может есть какой то фундаментальный труд который опишет все от и до как в ойти устроенно с технической точки зрения, аки капитал маркса?
Вот есть разные вебфреймоврки.
Но все они так или иначе реализуют шаблон MVC.
Вопрос. Можно ли что то изучить непосредственно по мвс, оторванное от конкретной реализации, что бы потом было менее болезнено менять технологию?
Вообще что можете посоветовать изучить что бы смена языка, фреймворка, или технологии была менее болезнена.
Так то заметил что ООП везде более или менее одинаково.
Структуры данных почти везде одни и те же.
Алгоритмы вообще от языка не зависят и им десятки лет.
Может есть какой то фундаментальный труд который опишет все от и до как в ойти устроенно с технической точки зрения, аки капитал маркса?
Конечно, дорогой, гугли "Паттерны проектирования".
Модель-представление-контроллер всего лишь один из них.
https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F

>Можно ли что то изучить непосредственно по мвс, оторванное от конкретной реализации, что бы потом было менее болезнено менять технологию?
И конкретно на этот вопрос, ответ скорее всего нет. Потому, что зависит, что считать за "безболезнено".
Вот к примеру React реализует MVC и Angular реализует MVC, и MVC-проект на дотнете реализует, но с одного на другое переходить я ебал.
Вот со скуля на скуль (например с мускула на т-скул) переходить будет просто потому,что это, грубо говоря, реализация одного стандарта. А вот в мире веб макак никакой стандартизации нет, и там каждый дрочит как хочет. Поэтому ты конечно можешь (и должен) подсекать на уровне понимания концепций чо такое там синглтон сервис, что такое фасад, что такое МВЦ, но на уровне конкретной реализации это будет всегда попоболь.
>React реализует MVC
А создатели Реакта об этом знают?)
Реакт просто для внещнего вида библиотека. А ангуляр да.
Просто меня пугают эти истории "Вышел новый фреймворк - 100 тыщ ссмузихлебов потеряли работу потому что не смогли пересеть." Хотя по факту они там будут строить тот же МВС и теже самые вебморды, просто средствами фреймворка.
Да, про паттерны в курсе, просто думал есть талмуды охватывающие все.

Алсо
>о с одного на другое переходить я ебал.
Так просто я получаю опыт на питоне, и собираюсь вкатываться вджангу.
Но мне очень нравится си #, в будущем хотелось бы работать на нем.
Но сейчас надо учить джангу для карьеры.
Ребят, нужно ли чего-то там нормализировать или можно подзабить пинуса и повторить структуру xml/json? Речь о БД, которая будет пользоваться тупо для хранения данных и изредка отчётов-поисков.
Можно ли postgreSQL заставить автоматом повторить набор элементов того же xml а потом закинуть в него все подходящие файлы как строки?
Прогугли хорошие талмуды по ЯП и CS, но для энтрилевельных. На русском даже не думай смотреть.
Там вполне будут описания именно того что хорошее-доброе-вечное. Ну, или так будет подано что когда с новым столкнёшься то сам поймёшь где тут каких плюшек наделали.
Но это вопрос не фреймворков, а более серьёзных абстракций. Как те же структуры данных.
У фреймворков одна задача обычно стоит, которую реализуют через IoC. Переход с конкурирующих фреймворков и даже просто библиотек - это всегда боль. Ты либо наткнёшься на две хорошие реализации, но которые зачем-то годами не приводят к обоюдопонятному стандарту, либо с тем что у одних есть хорошая писька, а у других такого даже в проекте не предвидится, либо огрызок какой-то позорный. Да и бестпрактисы порой разнятся, в том числе и из-за внутренней кривизны фреймворка.
Возвращаясь к фундаментальному - читай теорию ЯП и как вообще компьютер работает. Если ты поймёшь как v8 работает, то это даст тебе куда больше понимания нодоблядства, чем дрочение очередного бичпакета из npm.
бамп вопросу, субд - hsqldb и mysql
Я вообще по ораклу, но там с национальным символами есть нюансы: помимо того, что в твоей базе должна быть такая кодировка, ещё и твой клиент (чем ты вставляешь строку в таблицу) тоже должен иметь этц кодировку.
То есть если база у тебя с win1251, клиент с win1251, а ты хочешь в нее с этого клиента воткнуть символ в utf8, то он приведется к win1251 и вставится в базу. И всякие там a, B, C и прочие в базу влезут нормально, а вот символы, для кодирования которых нужно два и больше байт, в нее нормально не вставятся.
Проверь, может, у тебя тоже есть что-то в таком роде.
учу MySQL. Почему в блядском mysql workbench нет автодополнения кода? Мне что все по памяти писать нужно?
Вообще-то есть. Сходи ради приличия хотя бы на stack.
Спасибо, и правда есть. Но почему так медленно работает? И вообще весь гуи медленный какой-то. Пека вроде на воркстешн тянет. Или надо сразу учиться все через консоль пилить?
сап, делаю гуи для работы с бд. Не могу придумать, как сделать адекватную реализацию удаления: при удалении может вылететь ошибка
>UPDATE или DELETE в таблице "таблица_нейм" нарушает ограничение внешнего ключа "ключ_нейм" таблицы "таблица2_нейм"
как можно проверить, можно ли удалять элемент, чтобы обработать эту ошибку? в голову приходит только сделать SELECT по всем таблицам, у которых внешний ключ содержит эту таблицу, но чувствую, что изобретаю велосипед.
>UPDATE или DELETE в таблице "таблица_нейм" нарушает ограничение внешнего ключа "ключ_нейм" таблицы "таблица2_нейм"
как можно проверить, можно ли удалять элемент, чтобы обработать эту ошибку? в голову приходит только сделать SELECT по всем таблицам, у которых внешний ключ содержит эту таблицу, но чувствую, что изобретаю велосипед.
Прогугли про определение целостности и каскадное удаление.
Т.е. ты хочешь, чтобы пользователь, встав на запись, видел, можно ли ее удалять или нельзя?
Для какой бд манюнь? Для каждого конкретного движка будет свое воплощение этой фичи.
Мне 25 лет и я не умею ничего кроме SQL. Задавайте ответы.
Нахуй так жить?
Как же я надеюсь, что не стан тобой в 25.
Мимо 23х летний sql разработчик
АЛСО, господа, скажите, пожалуйста, что более перспективно - DBA или DBD.
>что не стан тобой в 25
Но судя по твоему вопросу ты уверенно идешь к этому.
советую sqlzoo. Там задачи не такие ебанутые как на sql-ex и в принципе нарешав их основные вещи более-менее будешь понимать
Бери питон и Java/Scala и ради своего блага вкатись в бигдату дата-инженером или бигдата-аналитиком. Да, это хайп и баззворды, но постепенно, маневрируя между расплывчатыми вакансиями и должностями, ты сможешь получить более-менее интересную работу. Главное не сдаваться и не бояться брать сложные задачи, где ты не знаешь больше половины используемых технологий.
Что бы там не говорили, бигдата в лице связки дата инженер+дата саентист никуда не денется. Я дата инженер, ебашу на спарке в основном. Если говорить про дата инжиниринг, то это концептуально похоже на pl/sql или типа tsql разработку. Но ощущения у меня лично всё-таки другие, метафизический хуй немного вырос от осознания того что делаю. Но это так, личное
востребованы спецы по конкретным субд, в основном в банках, телекомах, госструктурах и тех кто выполнят для них заказы. Я бы рекомендовал на хайпе и баззвордах вкатиться в дата инжиниринг, пока это возможно.
Ты вроде один человек, так что отвечу а два поста сразу. Я так понимаю, что мне нужно прямо сейчас начинать учить какую-нибудь статистику и R python? По каким словам вакансии искать, чтобы я хоть немного оценил стек, трудозатраты и личный интерес?
Короче смотри - недавно(буквально на днях) собеседовался для поддержания тонуса и "разведки" в нескольких местах: модный смузи-стартап, унылая "традиционная" компания и средняя компания по разработке мобильных игр. Вывод таков: блогеры были правы и действительно сформировалось разделение ролей, а именно - дата саентист и дата инженер. Ознакомься с этими ролями, почитай, поищи. Потом выбери.
Теперь = все написанное ниже нужно воспринимать с оговоркой на конкретные вакансии. ОЧЕНЬ ПОДРОБНО РАССПРАШИВАЙ ПРО СТЭК И ДОЛЖНОСТНЫЕ ОБЯЗАННОСТИ. Ты теоретически можешь попасть в компанию, где саентисты и инженеры - по сути просто sql-разработчики. Это реальность. И вообще все это основано только на моем скромном опыте.
Если ты хочешь быть дата инженером, то статистику, R, эконометрику и т.п. можно знать поверхностно или вообще не знать. Тут такова - ты помогаешь саентистам, аналитикам и другим товарищам создавая им "инфраструктуру данных", т.е. пайплайны(как традиционные etl-процессы, так и риалтайм фильтрация-аггрегация и так далее). Это значит, что тебе будет легче делать свою работу, если ты хоть немножко понимаешь нахуя люди от тебя это хотят. Питон ты испольуешь чтобы пользоваться спарком(pyspark), поглощать данные со всяких источников - API соцсетей, API каких-то приложений, всякие логи, всякие Кафки, всякие БД, и чтобы использовать модные планировщики вроде Airflow и Luigi. Java/Scala - когда требуется риалтайм(хотя питон и здесь начинает быть актуальным) и/или крутая производительность(pyspark всё же проигрывает). Кроме того, все инструменты бигдата экомистемы написаны на JVM языках; это значит, что ты лучше их сможешь понимать, если сам ориентируешься в таких языках.
Если ты хочешь быть саентистом, то из ЯП необходимо знать только питон, опционально - R, а также углубленные знания статистики и машинного обучения. Грубо говоря, нужно уметь выбирать модели, понимать плюсы-минусы для конкретной ситуации. Где хватит линейной регрессии, а где нужна нейросеть. Тут я тебе меньше советчик, могу просто рассказать только то что со стороны видел.
Ищи Data Scientist и Data Engineer.
Теперь пара оговорок.
Как я уже написал, всё дико зависит от вакансии и от реального положения дел в компании.
Ты можешь поднять себе ЗП, получив хайповую должность, а по сути делать то же самое, т.е. sql запросы. Т.е. стагнация,поскольку когда захочешь пойти дальше, уже будут всё-таки ожидать от тебя, что ты прошаренный или по бигдате, или по дата саенсу, или по и тому, и тому.
Поэтому основная сложность сейчас - это правильно себя поставить, отожрать тебе интересные задачи, которые тебя реально разовьют.
И напоследок чутьчуть конкретики, а именно - вкратце что спрашивали на собесе в той компании где я сейчас нахожусь
1. базовые знания python, bash; например, как работать с файлом если он слишком большой чтобы зажрать его в память целиком
2. базовые знания написания хранимых процедурок - естно говоря не знаю нахуя, редко всплывало потом.
3. базовое понимание бигдаты - говорили про хайв, хадуп, кафку, спарк. Я рассказал как разворачивал у себя локально миникластер из одного узла и что я там делал
Дали потом задачки на дом, там был парсинг апи Твиттера, филтрация, трансформация этого датасета, затем загрузка в реляционную базу данных, написание sql-запросов.
Затем был вопрос - как бы ты решал эту задачу, если бы твитов было бы в 10,100,1000 раз больше.
Мне по
...везло с интервьерами, по-моему я им понравился как человек, или же я просто сильно себя недооцениваю. хуй знает!
Спасибо тебе большое.
>могу просто рассказать только то что со стороны видел
Я бы почитал, если я тебя этим не сильно отвлеку. АЛСО, было бы интересно почитать про твой предыдущий бэг грунд.
>Дали потом задачки на дом, там был парсинг апи Твиттера, филтрация, трансформация этого датасета, затем загрузка в реляционную базу данных, написание sql-запросов.
А более подробное ТЗ ты скинуть можешь?
саентисты пришли с бэкграундом а-ля "я делал линейную регрессию в SAS и прошла курсы на курсере". Выросли из аналитиков, разработчиков, sql-чуваков. Так что это реально.
А сейчас их рабочий процесс такой: ставится задача, например - сделай мне модель по предсказанию оттока наших B2B клиентов. Начинается выясняловка: че за клиенты, че за данные у нас есть, какие мы можем получить новые данные и из каких источникво; короче брейншторм, какие у нас будут фичи(т.е. переменные). Исследовательный процесс. Написание скриптов на питоне - 10% времени.
У меня бэкграунд был в основном PL/SQL+Python(отжал себе задачку написать простенькое десктоп приложение для нанесения патчей на БД)+ETL-инструменты вроде Информатики. Все что с бигдатой связано, изучал дома сам. Установил вирутальную машину убунту, скачал хадуп, скачал спарк, кафку. Развернул все это дерьмо, попутно учась писать башскрипты. Поделал туториалы.
>Поделал туториалы.
А где взять?
я гуглил на английском языке.
На русском я ничего нормального не находил. Хотя и не особо искал.
Спасибо, няш.
>>2410511
Запусти fs_usage в терминале да полюбуйся как оно даже когда ничего не "чистит" лазит у тебя по диску
Ах да, ты наверное даже терминал открыть не сможешь, ведь ты и есть целевая аудитория таких программ
Запусти fs_usage в терминале да полюбуйся как оно даже когда ничего не "чистит" лазит у тебя по диску
Ах да, ты наверное даже терминал открыть не сможешь, ведь ты и есть целевая аудитория таких программ
промахнулся тредом, сорри

Есть вопросик.
Вот БАЗА ДАННЫХ.
В ней много таблиц от документов до пользователей.
В каждой таблице есть поле created типа Дата, куда заносятся дата создания строчки в таблице.
Вообщем вопрос. Имеет ли смысл выносить даты в отдельную таблицу, и проверять просто при содании записи, есть ли в этой таблице такая дата, и присваевать в нужной таблице айди этой даты Это же нормализация, да?
Или это излишний заеб и нинужно?
Вот БАЗА ДАННЫХ.
В ней много таблиц от документов до пользователей.
В каждой таблице есть поле created типа Дата, куда заносятся дата создания строчки в таблице.
Вообщем вопрос. Имеет ли смысл выносить даты в отдельную таблицу, и проверять просто при содании записи, есть ли в этой таблице такая дата, и присваевать в нужной таблице айди этой даты Это же нормализация, да?
Или это излишний заеб и нинужно?
Ради одной только даты хуярить - звучит странно.
Тоже интересно ответ услышать.

Зависит от задач.
Есть вообще EAV модель когда ты делаешь одну таблицу для сущностей. Другую для атрибутов сущностей. Третью для значений этих атрибутов, и толькой айдишники вставляешь по такой иерархии.
Кошмар если нет Нормальной ORM а чистый SQL, но дает возможность тебе написать информационную систему где заранее неизвестно сколько будет сущностей, сколько у них буедт атрибутов, и каких будут типов их значения.
Это все можно переложить на пользователя. Пусть своим сранным сапогам в своем сранном интернет магазине хоть сто характеристик отдельно напишет,цвет, размер, запах, какого цвета была жопа у той твари с которой кожу содрали для этих сапог, итд. А в соседнем товаре аля Шарф этих характеристик не будет.
Какая, к чертям, нормализация? Нормализацию у тебя в мозгу провести надо.

Аноны-sqlщики, подскажите по ситуации плиз. Сам учусь примерно полгода уже, чтоб работать в анализе данных, из последнего вот только что закончил курс по sql на юдасити. Немного рассылал резюмеху, в итоге получилось так, что прошел собес на должность инженера техподдержки 2 уровня, и как я понял надо будет много ворочать sql, потому что перед тем как берут на работу, компания (it компания видимо среднего размаха в ДС/ДС-2 и Европе) они короче сначала гонят тебя на оффлайн курс по SQL от них, который идет 40 часов и растянут на пару недель.
Короче скоро начинаю ходить на эти курсы, и мне интересно короче кто что думает про такую тему. Опыта работы у меня нет в IT, и хоть это будет и не работа аналитиком, но по идее вход в индустрию уже будет после такой работы? И sql полезная штука как я понимаю в анализе ведь
И по курсу, насколько наличие в резюме такого интенсива будет ништячно? Я так думаю за 40 часов можно ух нагоняться, ни у кого не было подобного опыта?
Короче скоро начинаю ходить на эти курсы, и мне интересно короче кто что думает про такую тему. Опыта работы у меня нет в IT, и хоть это будет и не работа аналитиком, но по идее вход в индустрию уже будет после такой работы? И sql полезная штука как я понимаю в анализе ведь
И по курсу, насколько наличие в резюме такого интенсива будет ништячно? Я так думаю за 40 часов можно ух нагоняться, ни у кого не было подобного опыта?
>
>(2994Кб, 1920x1080)
>
>Аноны-sqlщики, подскажите по ситуации плиз. Сам учусь примерно полгода уже, чтоб работать в анализе данных, из последнего вот только что закончил курс по sql на юдасити. Немного рассылал резюмеху, в итоге получилось так, что прошел собес на должность инженера техподдержки 2 уровня, и как я понял надо будет много ворочать sql, потому что перед тем как берут на работу, компания (it компания видимо среднего размаха в ДС/ДС-2 и Европе) они короче сначала гонят тебя на оффлайн курс по SQL от них, который идет 40 часов и растянут на пару недель.
>
>Короче скоро начинаю ходить на эти курсы, и мне интересно короче кто что думает про такую тему. Опыта работы у меня нет в IT, и хоть это будет и не работа аналитиком, но по идее вход в индустрию уже будет после такой работы? И sql полезная штука как я понимаю в анализе ведь
>
>И по курсу, насколько наличие в резюме такого интенсива будет ништячно? Я так думаю за 40 часов можно ух нагоняться, ни у кого не было подобного опыта?
когда получишь работу, попробуй РЕАЛЬНО прокачаться в sql и брать себе побольше сложных задач связанных с его использованием.
SQL - основная рабочая лошадка аналитиков, это факт.
и все пробелы, которые не охватил выполняя работу, заполни сам. Грубо говоря, основной багаж знаний - это джойны, работа с NULL(есть нюансы, например тот факт что любое сравнение null с null это false, и то как null себя ведёт при попадании в сумму), подзапросы (когда селектишь из другого селекта), мудрое использование стандартного пакета агрегирующих и неагрегирующих функций и аналитические/оконные функции.
Эзотерику вроде grouping sets можешь игнорировать, она не очень часто используется. Вопросы на sql-собеседованиях, даже на продвинутые позиции, на моей практике все упираются в хорошее понимание того что я упомянул выше.
Если знаешь англ, читай англоязычные туториалы и из упражнений рекомендую sqlzoo.
>
>>>1287876
>и все пробелы, которые не охватил выполняя работу, заполни сам. Грубо говоря, основной багаж знаний - это джойны, работа с NULL(есть нюансы, например тот факт что любое сравнение null с null это false, и то как null себя ведёт при попадании в сумму), подзапросы (когда селектишь из другого селекта), мудрое использование стандартного пакета агрегирующих и неагрегирующих функций и аналитические/оконные функции.
>
>Эзотерику вроде grouping sets можешь игнорировать, она не очень часто используется. Вопросы на sql-собеседованиях, даже на продвинутые позиции, на моей практике все упираются в хорошее понимание того что я упомянул выше.
>
>Если знаешь англ, читай англоязычные туториалы и из упражнений рекомендую sqlzoo.
>
и ещё не забывай про повсеместность excel. Все аналитики,с которыми я работал - настоящие визарды экселя и это им реально помогает, т.к. их "клиенты" как правило результат труда хотят в виде красиво оформленной экселины.
спасибо большое за инфу!! про эксель как то забыл уже, буду шерстить курсы по нему, вспоминать что знал
за упражнения тоже благодарочка
недавно вот статистику начал изучать, теперь даже не уверен что это нужно будет в ближайшее время, хех :/
Я вопрос задал, дебил.

Делать отдельно таблицу дат с айди и проставлять ссылки на даты, это без, сомнения, нормализация.
Однако сценарий, где на дату надо _ссылаться_ я могу себе представить с большим трудом. Хотя не, пизжу. Не могу.
Я помню, что при построении КХД бывают кейсы, когда такой ход - разумен, но не помню кокнретных деталей.
В 99,95% случаев мы дату чего либо (в данном случае дату создания) прикапываем в той же табле что и описываемая сущность или процесс.
мимо-архитектор
>это без, сомнения, нормализация
Хуёвый ты архитектор.
Блядь манюнь, не еби мозги, а?
Ты через это приводишь отношение к доменно-ключевой нормальной форме.
Вопрос только в том - нахуйя?
Хуитектор, id-шник тоже в отдельную таблицу занеси, а то что это они в разных таблицах одинаковые? Это не нормализация, а хуйня, и вопрос зачем даже не стоит.
Ты ебанутый совсем? Тебе говорят про ограничения домена
У тебя есть справочник городов
1 Москва
2 Урюпинск
3 Саратов
Соответственно, все поля "Город" будут ограничены доменом городов? Ок? Поменял по id 3 Саратов на Saratov, у тебя во всех представлениях, процедурах, функциях подтянется обновленное зхначение, без необходимости править _каждую_ таблицу с полем
"Город"
Ровно тоже ты можешь сделать с датами. Вопрос только в том- нахуя?
Ровно тоже ты можешь сделать с id-шниками. Или с возрастом людей или счетчиком скачиваний или %любое поле-значение%. И это очевидный пиздец, как и с датами. Так что ебанутый здесь только ты. Ну и ещё тот идиот, что это предложил, но он хоть архитектором себя не называл.

Во-первых, тут никто этого не предлагал, а спросил стоит ли так делать.
Я ответил, что не стоит.
И, таки да, так можно сделать с любым пулом значений, который можно загнать в домен.
И это всего-лишь один из способов нормализации, который можно использовать, а можно не использовать.
Короче, студент, ты лучше впитывай, что тебе тут бесплатно взрослые дяди рассказывают, а не воюй с голосами в голове.
Какой пул значений ты в датах создания записи узрел? Это же не праздники, например, которые ограничены и на них это бы работало. Дата создания может быть любая. Любая. Ты понимаешь это? И это архитектор. Говно ты, а не архитектор.
Спасибо за разъяснение.
А вы, месье, хам и грубиян.
Мимо спросивший.
а ты дату не отличаешь от датавремя? Ок
Дата у нас теперь конечная? Когда там уже конец света? Скажи, не томи!
Студент, не тупи.
В рсубд постоянно генерят даты на несколько лет вперед для разного.
Для какого разного, одаренный ты наш? Ситуация обозначена:
>В каждой таблице есть поле created типа Дата, куда заносятся дата создания строчки в таблице.
Ты утверждаешь что можно (не в смысле физической возможности) эту дату вынести как отдельную сущность. Я утверждаю, что это полнейшая глупость и не имеет смысла. Так что заканчивай манёвры, архитектор хуев, и иди пиши заявление по собственному, пока контора не накрылась от твоего профессионализма.
Сука пидарас, ты мне это в лицо сказать сможешь, ГАНДОН блядь ебаный?? Давай нахуй встретимся и ты блядь ответишь за свой гнилой базар, гнида! Ты где живёшь нахуй?
Или ты блядь только в интернете такой смелый, сучара ебаная?
Малолетний дегенерат блядь, у тебя ещё молоко на губах не отсохло, чтобы так пиздеть!
Как в mysql выбрать ячейку текущей выбранной строки?
Например update table set meta = name_c_текущей_строки + " всем привет я Толян Пивас"
Например update table set meta = name_c_текущей_строки + " всем привет я Толян Пивас"
Привет, нужен небольшой совет.
Предположим есть таблица с двумя полями на внешние ключи - адрес магазина и тип товара ну и разные другие. Надо собрать другую таблицу где для каждой пары адрес-тип будет количество товаров, т.е. просто количество строк в той таблице. Я это могу сделать в лоб в приложении, но может есть какой-то быстрый способ в sql это сделать? Тут декартово произведение получается как никак.
Предположим есть таблица с двумя полями на внешние ключи - адрес магазина и тип товара ну и разные другие. Надо собрать другую таблицу где для каждой пары адрес-тип будет количество товаров, т.е. просто количество строк в той таблице. Я это могу сделать в лоб в приложении, но может есть какой-то быстрый способ в sql это сделать? Тут декартово произведение получается как никак.
select address, item, count(*)
from table
group by address, item

Не подскажите в чем дело может быть?
Поставил MS SQL server.
Захожу в студию. Жму там Создать новую базу данных SQL server...
Но кнопка Обновить не показывает мне мой сервер. Ну ладно. Ввожу руками название. Жму подключить.
Он появляется. Жму треугольник, чтобы раскрыть список. Жму еще раз и этот треугольник просто исчезает.
Создают новую таблицу, заполняю там все, сохраняю.
Обновляю базу данных.
А там рядом с словом Таблица даже нет этого треугольника для раскрытия списка.
Че делать?

А вот через вкладку Обозреватель объектов SQL server все работает. И подключение к серверу там уже есть.
А через вкладку Обозреватель серверов не работает.
В чем разница между этими вкладками? И почему так?
Антоны, привет, я умею немного в питон и JS.
И вот вкатываюсь в SQL. Вкатываюсь так что АЖ ТРИСЕТ!
Не пойму общую логику запроса.
Вот допустим есть три таблицы: Таб1, Таб2, Таб3.
Как в SQL сделать допустим так:
Если в Таб1 в Столбец1 значение = 1 - то обновляется строка в Таб2, если же в Таб1 в Столбец1 значение = 2 - то обновляется строка в Таб3.
Я могу делать примитивные дискретные запросы к одной таблице. Пересечения JOIN разных таблиц. Подзапросы.
Но не понимаю как выполнить сразу несколько инструкций SELECT/UPDATE и т.д., что бы они выполнялись в условиях IF допустим, и как передавать между этими запросами переменные данной итерации.
Поможите.
И вот вкатываюсь в SQL. Вкатываюсь так что АЖ ТРИСЕТ!
Не пойму общую логику запроса.
Вот допустим есть три таблицы: Таб1, Таб2, Таб3.
Как в SQL сделать допустим так:
Если в Таб1 в Столбец1 значение = 1 - то обновляется строка в Таб2, если же в Таб1 в Столбец1 значение = 2 - то обновляется строка в Таб3.
Я могу делать примитивные дискретные запросы к одной таблице. Пересечения JOIN разных таблиц. Подзапросы.
Но не понимаю как выполнить сразу несколько инструкций SELECT/UPDATE и т.д., что бы они выполнялись в условиях IF допустим, и как передавать между этими запросами переменные данной итерации.
Поможите.
подозреваю, что тут необходима хранимая процедурка или питон+sqlalchemy чтобы добавить conditional логику.
На SQL так сделать нельзя.
Это не язык программирования, а язык запросов.
Т.е. надо или триггеры или процедуры, или программу на языке программирования. Лучше - программу.
Также, сама постановка задачи выглядит как-то подозрительно.
Скрипт или хранимая процедура + временные таблицы.
Спасибо
>>Также, сама постановка задачи выглядит как-то подозрительно.
Да я как то в русле программирования продолжал думать. От этого и мои вопросы.
Вероятно у тебя кривая схема данных.
Извини за выражение, но говно какое-то получается.

Трисет тебя потому, что ты свинособака и питоноблядок, но это ничего страшного и это лечится.
Тебе надо перестать думать обьектами и начать думать ОТНОШЕНИЯМИ и МАССИВАМИ ДАННЫХ.
Я, например, вообще не вижу никакого смысла изобретать тройной апдейт с ифами, грубо говоря.
Почему бы тебе не сделать три последовательных апдейта, если тебе важен результат прошлой операции?
Этого не слушай, тащить за собой данные можно. Например в курсоре.
Но это подход настоящей махровой свинособаки, а не достойного сэра.
Опиши более вменяемо структуру данных, и что ты хочешь добиться. А мы тебе придумаем что нибудь подходящее.
>Удивляемся, как за знания, приобретаемые за 4 месяца на sql-ex, могут платить по 100к
Это действительно так ?
О себе: Я раньше работал в бухгалтерии, а потом перекатился работать в банк. Перекат был из-за большей зп, но приходиться работать с клиентами (милд офис), что уже вызывает нервоз из-за тупости и наглости клиентов, если с тупостью я рад помочьНу типа пох как-то, то с наглостью БЛЯТЬ СУКА БЛЯТЬ КАК ВСЕ ЗАЕБАЛО БЛЯТЬ ИДИ НАХУЙ
Я уже просто мечтаю о работе с документами и залипании работы в Excel. На НН вижу вакансии с хорошей зп (работа с отчетностью или аналитик), где требуют знание Excel + SQL, если Excel я ещё дрочил в вузе + когда работал в бухгалтерии, то с SQL сейчас хочу посмотреть что и как тут.
Хотел спросить, у пня 27 левл при изучения sql-ex, на какую работу есть шансы претендовать, и какие именно обязанности придется выполнять ?
Это действительно так ?
О себе: Я раньше работал в бухгалтерии, а потом перекатился работать в банк. Перекат был из-за большей зп, но приходиться работать с клиентами (милд офис), что уже вызывает нервоз из-за тупости и наглости клиентов, если с тупостью я рад помочьНу типа пох как-то, то с наглостью БЛЯТЬ СУКА БЛЯТЬ КАК ВСЕ ЗАЕБАЛО БЛЯТЬ ИДИ НАХУЙ
Я уже просто мечтаю о работе с документами и залипании работы в Excel. На НН вижу вакансии с хорошей зп (работа с отчетностью или аналитик), где требуют знание Excel + SQL, если Excel я ещё дрочил в вузе + когда работал в бухгалтерии, то с SQL сейчас хочу посмотреть что и как тут.
Хотел спросить, у пня 27 левл при изучения sql-ex, на какую работу есть шансы претендовать, и какие именно обязанности придется выполнять ?
знание предметной области и экселя может скомпенсировать твои пробелы в sql. Знаю аналитиков которые не знали sql до текущей работы, а им точно за тридцать.
Единственное, я не понимаю откуда такое горячее желание убивать свой мозг дроча sql-ex вместо sqlzoo. Пожалуйста, начни с sqlzoo. Там на английском, но зато там очень плавно тебя ведут от самых простых селектов к более сложным вещам.
Что придётся делать - если речь идёт об отчетности, то на мой взгляд процесс будет такой: поступает просьба запилить отчёт. Просьба сформулирована скажем так "бизнес-языком", с использованием терминов предметной области. Вот тут ты можешь использовать знание предметной области, чтобы понять какие таблиы задействовать, какие фильтры логично наложить, где ссумировать, а где взять среднее и может даже предугадать и слегка додумать за "клиента" его требования. Дальше ты используешь технические навыки, проверяешь качество данных на всякий случай, и строишь отчетик - пишешь запрос, сохраняешь в эксельку результат. Если нужно, в эксельке добавляешь всякие няшные финтифлюшки. Отправляешь резалт клиенту.
Мой взгляд правда слегка со стороны. Меня иногда просят сделать ad-hoc запросы/отчеты, но я больше парюсь по инфраструктурным вопросам, бигдате всякой etc
>ЗОЧЕМ ЖИ НУЖИН ОЛАП, ЕСЛИ И ТАК ВСЕ РАБОТАЕТ ЗАЕБИСЯ
Пролистал тред, ответа не нашел
>Рассказываем, как работаем аналитиками и мечтаем стать разработчиками
На самом деле нет, аналитиком быть кайф. И в бизнес погружаешься, и поковырять всякие хадупы можно.
Но у меня вопрос - куда развиваться аналитику чисто в техническом плане, без привязки к конкретной области, и не уходя в разработку, архитектуру бд?
>куда развиваться аналитику
Поясню. Ну чтобы можно было придти в любую контору и сказать "вот я умею это и это, работал с этим и этим, прошел такие-сякие курсы". А то уже третий год работы идет, а из навыков программирование на уровне парсинга твиттера, бд на уровне СЕЛЕКТ АПДЕЙТ, математика на уровне линейной регрессии. Ну да, еще я умею выгружать все что угодно в excel, знаю что такое PowerPivot (и DAX соответственно), чем медиана отличается от моды, работал с ms sql, postgres, clickhouse, hadoop, teradata, sas и черт знает еще чем. Но это все как-то поверхностно что ли, а хочется какой-то ГЛУБОКОЙ аналитики, если вы понимаете о чем я.
>
>>>1293708
>>куда развиваться аналитику
>Поясню. Ну чтобы можно было придти в любую контору и сказать "вот я умею это и это, работал с этим и этим, прошел такие-сякие курсы". А то уже третий год работы идет, а из навыков программирование на уровне парсинга твиттера, бд на уровне СЕЛЕКТ АПДЕЙТ, математика на уровне линейной регрессии. Ну да, еще я умею выгружать все что угодно в excel, знаю что такое PowerPivot (и DAX соответственно), чем медиана отличается от моды, работал с ms sql, postgres, clickhouse, hadoop, teradata, sas и черт знает еще чем. Но это все как-то поверхностно что ли, а хочется какой-то ГЛУБОКОЙ аналитики, если вы понимаете о чем я.
>
Дата саенс это наверное и есть та самая глубокая аналитика. Если ты знаешь статистику то подучи её ещё немного, порубай на kaggle, выучи всякие питон либы вроде numpy,scipy,tensorflow, для визуализации что-то. Люди говорят этого недостатчно ну может недостаточно чтобы в их глазах быть труъ но вообще можно прийти с такими знаниями и уже работая реально вглубь развиться. Тут уже дело удачи и того факта что нужно очень много подавать заявок и активно искать везде, не просто открыть профиль на хедхантере и ждать.
Да.
Если ты ещё здесь,
Postgres
pandas забыл из либ. пандас оч важно
Если тебе нужно знать о возможности удаления до попытки удаления, то есть такие варианты:
1. Вычислять наличие дочерних записей в главном запросе - это будет медленно.
2. Проверять наличие дочерних записей в момент выбора строчки - дополнительным обращением к базе (можно селектом, а можно и удалением с отловом исключения и если его нет, то делать rollback и показывать кнопку реального удаления. Если есть исключение - кнопку не показывать)
3. Проставлять в родительской таблице флаг наличия дочерних записей при вставке или удалении в подчиненные таблицы - триггерами или через хранимые процедуры, но и внешний ключ не отключать.
Но я особого смысла в этом не вижу, блокирование кнопки не очень понятно для пользователя (почему не горит кнопка? Нет прав? Где именно находятся дочерние записи и сколько их?), а если написать вменяемое сообщение на исключение (с указанием в каких таблицах есть подчиненные данные и их количество), то все будет нормально.
К тому же если у тебя будет работать больше одного человека, то предварительная проверка может быть неактуальной к моменту реального удаления.
top
Так, с тобой всё понятно.
Даю неочевидный совет. Делай свои ебаные проверки ДО наступления "страхового случая".
Буквально, веди таблицу зависимостей отдельно.
Когда пользователь встает на твою ебаную запись, ты дергаешь ченить типа
TryDeleteProc которая чекнет есть ли зависимые записи опираясь на ЗАРАНЕЕ
ПОДГОТОВЛЕННЫЙ
ДАТАСЕТ
Сейчас делаю удаление с лиловом исключения, но мне кажется, это плохая практика. Про флаг не совсем понял, но на ум пришла идея завести столбец-счётчик зависимостей в родительской таблице - при удалении/добавлении в дочерней таблице декрементировать/инкрементировать соответствующее значение. Или я хуету несу?)
Твой способ тоже вроде бы классный.
Жаль только, что мне для крайне нежелательно редачить

Что тебе крайне нежелательно?
Вот тебе, кстати, пример.
Хуячишь иерахический справочник
ObjectID OwnerObjectID
Соответственно, на добавлении связываемых вещей срёшь в этот справочник.
Дальше вообще изейше.
Пользователь встает на ЛЮБУЮ запись у тебя в системе, жмет делет, ты лезшь в справочник, SELECT TOP (1) FROM MyHierarchy WHERE ID =@ID AND OwnerID IS NOT NULL => водишь пользователю вялым по лицу
Редачить бд*
Не ну а как ты хотел? Нихуя не делая все иметь?
Я не шибко в курсе, в постгре есть такой же богатый доступ к метаданным как скульсервере?
Можно селектом поднять зависимости?
Бля кекнул с вялого. А это не будет считаться говняным костылем?
Хотел запросами это сделать.
> Можно селектом поднять зависимости?
Этого я как раз не ебу. Нуфаг-вкатывальщик
>Бля кекнул с вялого. А это не будет считаться говняным костылем?А почему будет? Раз у тебя появились сомнения, остуановись и ПОДУМОЙ какие минусы у такого подхода, какие плюсы.
>Этого я как раз не ебу. Нуфаг-вкатывальщик
Ну так прочитай доки, мудила, няш!
Двач посоветуй что-нибудь почитать о бд пожалуйста. Только не талмуды по 2к страниц они вообще нечитаемы. Что-нибудь доходчивое, но не справочники по sql а именно про бд. Где и теория есть и примеры из реальной жизни.
Отлов эксцепшона - единственная нормальная практика.
Любые проверки до удаления могут стать неактуальными в момент фактического удаления - Вася встал на запись, которую вроде можно удалить и пошел пописать, Петя в другом городе в это время добавил к записи дочерние записи. Вася поссал и жмет УДОЛИТЬ - твои действия? Поэтому только форинкеи, только хардкор.
>Только не талмуды по 2к страниц
Лол. Тогда советую не тебе, советую другим.
https://www.ozon.ru/context/detail/id/139953550/
https://www.ozon.ru/context/detail/id/136880774/
Спасибо, конечно. Первая выглядит прям как по заказу, о блядь, как такие талмуды читать. Да я ее пол года в лучшем случае буду читать. Времени не так уж много. Ну, буду пытаться по главам смотреть.
Спасибо
Не знаю куда вопрос задать - задам тут. 0 в бд, хочу вкатиться, что читать первым?
Освой sql за 10 минут. Дальше читай реалиционную теорию бд. Потом уже по конкретным бд книги/доки.

Для новичка?! Ты совсем ебобо?!
Если открыть первую главу, то там как раз для новичка.

анончики, если прошел двухнедельный оффлайновый интенсив по sql, куда его в hh лучше вписывать, чтоб повиднее было? просто в пройденные курсы как то затеряется среди всех, может в стаж, так сказать? или типо тесты/экзамены?
Пиздежь! SELECT это DQL!
нам кстати препод это отметил, типо хз почему оракл решили его к этой категории отнести
А по nosql нету что ли треда? совсем уже...
Есть javascript-тред, хуярь туда.
Зачем мне туда? MongoDB != JS.
Ну а на этой доске с nosql только петушки-хипстеры и знакомы.
День добрый, аноны.
Может кто то сможет подсказапо по повод составления SQL запроса.
Есть SQLite3 база, содержащая временные ряды формата :
sqlite> SELECT timestamp, ask_open, bid_open FROM EUR_USD_M1 LIMIT 5;
timestamp ask_open bid_open
------------ ---------- ----------
1420149600.0 1.21109 1.21005
1420149660.0 1.21084 1.21014
1420149720.0 1.21092 1.21022
1420149780.0 1.21083 1.21022
1420149840.0 1.211 1.21035
sqlite>
Для баловства с нейроночками и прочим ML, мне нужно данные приводить к виду
скользящего окна, к примеру по ask_open для окна размером 3
1.21109 1.21084 1.21092
1.21084 1.21092 1.21083
1.21092 1.21083 1.211
Сейчас я то дела через python и кучу запросов в цикле вида :
SELECT ask_open FROM EUR_USD_M1 WHERE timestamp in (SELECT timestamp from EUR_USD_M1 WHERE timestamp >= 1420149600.0 AND timestamp < 1420149600.0 + 3*60;
В общем вложеные циклы, двумерные списки и прочие радости, убиващие производительность + почти 300 строк лишнего кода.
Реально ли сделать таку подготовку данных силами СУБД?
Может кто то сможет подсказапо по повод составления SQL запроса.
Есть SQLite3 база, содержащая временные ряды формата :
sqlite> SELECT timestamp, ask_open, bid_open FROM EUR_USD_M1 LIMIT 5;
timestamp ask_open bid_open
------------ ---------- ----------
1420149600.0 1.21109 1.21005
1420149660.0 1.21084 1.21014
1420149720.0 1.21092 1.21022
1420149780.0 1.21083 1.21022
1420149840.0 1.211 1.21035
sqlite>
Для баловства с нейроночками и прочим ML, мне нужно данные приводить к виду
скользящего окна, к примеру по ask_open для окна размером 3
1.21109 1.21084 1.21092
1.21084 1.21092 1.21083
1.21092 1.21083 1.211
Сейчас я то дела через python и кучу запросов в цикле вида :
SELECT ask_open FROM EUR_USD_M1 WHERE timestamp in (SELECT timestamp from EUR_USD_M1 WHERE timestamp >= 1420149600.0 AND timestamp < 1420149600.0 + 3*60;
В общем вложеные циклы, двумерные списки и прочие радости, убиващие производительность + почти 300 строк лишнего кода.
Реально ли сделать таку подготовку данных силами СУБД?
Чому в шапке нет книжек на почитать?
- добавь колонку с порядковым номером записи (или генерируй его на лету, если sqlite это поддерживает).
- делай два джойна с самим собой по a1.row_number = a2.row_number + 1, a2.row_number = a3.row_number + 1
На работе сказали, что на новом проекте придётся вместо постгреса юзать MS SQL. Там много различий? Создать новую бд, а в ней таблицы и смотреть что там да как через аналог pgAdmin возможно или такого нет?
> Там много различий?
Даже с ораклом меньше. Ну ты понял. Хотя судя по твоему вопросу, сомневаюсь.
> Создать новую бд, а в ней таблицы и смотреть что там да как через аналог pgAdmin возможно или такого нет?
Это можно с почти любой из ныне живых СУБД через какой-нибудь dbeaver.
>Даже с ораклом меньше.
Эх, так не хотелось вникать особо, надеялся что обычными SQL командами обойдусь и ладно. Придётся тогда ознакомиться.

Решение громоздкое конечно (окно нужжно куда шире, 20-25 размером, столько же примерно и дойнов надо), но это хотя бы что то. А как индекс - таймштамп годится, и уникальный и интервал равномерный. Попробую.
Нефти тебе анон.
da
>(окно нужжно куда шире, 20-25
ну напиши +20 в джойне блядь
B получу не 20 последовательных значений, а только 1е и 20е ?
Или я тебя не так понял ?
Пока получил то, что надо способом, как советовал анон выше.
sqlite> SELECT t1.timestamp, t1.ask_open, t2.ask_open, t3.ask_open FROM EUR_USD_M1 t1, EUR_USD_M1 t2, EUR_USD_M1 t3 WHERE t1.timestamp = t2.timestamp+60 AND t2.timestamp = t3.timestamp+60 LIMIT 6;
timestamp ask_open ask_open ask_open
------------ ---------- ---------- ----------
1420149720.0 1.21092 1.21084 1.21109
1420149780.0 1.21083 1.21092 1.21084
1420149840.0 1.211 1.21083 1.21092
1420149900.0 1.21062 1.211 1.21083
1420149960.0 1.21057 1.21062 1.211
1420150020.0 1.21057 1.21057 1.21062
sqlite> SELECT t1.timestamp, t1.ask_open, t2.ask_open FROM EUR_USD_M1 t1, EUR_USD_M1 t2 WHERE t1.timestamp = t2.timestamp+2*60 LIMIT 6;
timestamp ask_open ask_open
------------ ---------- ----------
1420149720.0 1.21092 1.21109
1420149780.0 1.21083 1.21084
1420149840.0 1.211 1.21092
1420149900.0 1.21062 1.21083
1420149960.0 1.21057 1.211
1420150020.0 1.21057 1.21062
sqlite> SELECT timestamp,ask_open FROM EUR_USD_M1 LIMIT 10;
timestamp ask_open
------------ ----------
1420149600.0 1.21109
1420149660.0 1.21084
1420149720.0 1.21092
1420149780.0 1.21083
1420149840.0 1.211
1420149900.0 1.21062
1420149960.0 1.21057
1420150020.0 1.21057
1420150080.0 1.21057
1420150140.0 1.21051
sqlite>
В последнем sqlite недавно windows функции ввели как в постгре. То что тебе нужно. https://www.sqlite.org/windowfunctions.html
Я тебя сам не понимаю.
Уесли ты джойнишь по условию
left.numeruc_id =< right.numeric_id+N то твое N задает ширину окна.
При N = 3 для left.numeric_id = 1 дадут 4 записи из right 1,2,3,4
и так далее
>https://www.sqlite.org/windowfunctions.html
О, Спасибо, гляну !
Возможно дело во мне, я в жизни с SQL имел дело только в виде простых select запросов.
sqlite> SELECT t1.timestamp, t1.ask_open, t2.ask_open FROM EUR_USD_M1 t1, EUR_USD_M1 t2 WHERE t1.timestamp <= t2.timestamp+20*60 LIMIT 6;
1420149600.0|1.21109|1.21109
1420149600.0|1.21109|1.21084
1420149600.0|1.21109|1.21092
1420149600.0|1.21109|1.21083
1420149600.0|1.21109|1.211
1420149600.0|1.21109|1.21062
>>Трисет тебя потому
Уже меньше трисет, вкатываюсь по тихоньку. Чуть перестроил мышление с програмиссткого подхода в базоданновый.
>>Этого не слушай, тащить за собой данные можно. Например в курсоре.
О курсорах, представлениях и виртуальных таблицах уже имею некое понятие. И они и правда далеко не всегда нужны.
У меня такой вопрос - какие фильтры выполняются первыми при объединении таблиц - те что в инструкции
INNER JOIN tab1 ON ... = ... AND....
Или те что после
WHERE ....
установлены?
Ну вообще, если уж присмотреться, то DML не является подмножеством DDL и никто сомневается, что это разные вещи
А вот селект (ну ладно, DQL) - это как раз подмножество DML.
Ну и при выполнении DML тебе необходимо читать данные с диска - оперировать данными - а селект тоже делает именно это. Вот тебе и DML.
да что с этой капчей
При внутреннем джойне - однохуйственно.
При внешних - для основной таблицы правила как при обычном джойне, а для присоединяемой - сначала on, потом where.
В базе есть столб с датой рождения, как выбрать всех кому исполнилось 18 на момент запроса?
Мимокрокодил и наткнулся на https://habr.com/company/mailru/blog/266811/
К БД отношения почти не имею, так что не обосцывайте.
1.
"
Например, нам нужно в таблице объединить две колонки: «фамилия» и «имя». Благодаря статистике БД знает, что в ней содержится 1 000 уникальных значений «имя» и 1 000 000 — «фамилия». Поэтому база объединит данные именно в таком порядке — «фамилия, имя», а не «имя, фамилия»: это требует гораздо меньше операций сравнения, поскольку вероятность совпадения фамилий гораздо ниже, и в большинстве случаев для сравнения достаточно брать 2-3 первые буквы фамилии. "
Вопрос - почему и о каких операциях сравнения идет речь?
2. Еще где-то видел(ну или я дебил так подумал), что писать:
SELECT FROM TABLE1 JOIN
(SELECT FROM TABLE2 WHERE CONDITION)
ON TABLE1.ID = TABLE2.REF_ID1
Нету смысла, и эквивалентно по скорости работы
SELECT * FROM TABLE1, TABLE
WHERE ID=REF_ID AND CONDITION
Хотя для меня это не очевидно. Казалось бы, вначале отфитровал вторую таблицу, откинул часть данных, и потом сделал join - должно быть быстрее, чем сначала сджойнить кучу данных и потом фильтровать
>https://habr.com/company/mailru/blog/266811/
>Вопрос - почему и о каких операциях сравнения идет речь?
Мимо с 2005 кодирую на скуле. Я так понимаю, он говорит про создание Cartesian product.
(Вася, Петя) * (Иванов, Петров, Сидоров) => (Вася Иванов, Вася Петров, Вася Сидоров, Петя Иванов, Петя Петров, Петя Сидоров)
Если у тебя в таблице слева (Вася, Вася, Вася, Петя) а в таблице справа (Сидоров, Сидоров, ........ Сидоров) то статистика подсказывает какой физический вид джойна выбрать, и какую таблицу брать "входной" если выбран nested loop , а при такой разнице размеров будет выбран скорее всего он.
> Еще где-то видел(ну или я дебил так подумал), что писать:
Гуглируй последовательность выполнения инструкций СЕЛЕКТА, если мы говорим о MS SQL
> какую таблицу брать "входной" если выбран nested loop
Какая разница, что брать в качестве внешнего, а что в качестве внутреннего цикла, в обоих же случаях O(n*m) (я про наивную реализацию, само собой)
Все равно, не понимаю о каких операциях сравнения идет речь.
Если о сравнении таплов в целом
(Вася, Иванов), (Вася, Петров) сравнить стоит дороже чем
(Петров, Вася) (Иванов, Вася) - то это ясно, нок чему это все сказано - не понятно
Потому, что когда ты делаешь деКартево произведенее, тебе надо умножитьб всё на всё. Логично ОДНО из этого всего сжать до
distinct значений, чтоб лишний раз в булочкную не бегатью.
Когда ты делаешь этот дистинкт, надо сравнивать.
Посоветуйте книгу, чтоб основательно и все разжеванно. А не вот таблички, вот связи, вот запросы пишем, конец. На таком уровне SQL я знаю, интересуют именно подробности, чтоб с джоайнами, ордерами и оптимальными запросами. На чистом SQL не пишу, но Рейлс запросы транслируются в него, и получается ужас, не ожидал такой огромной разницы между pluck и select.

ВНИМАНИЕ ВОПРОС
Самая быстрая бд для поиска по 100 млн записям с сортировкой по 20 параметрам?
Самая быстрая бд для поиска по 100 млн записям с сортировкой по 20 параметрам?
Воооот. Теперь понятно что откуда и почему.
Спасибо
Хотя можно без сортировки, просто селект 100 записей из 100 млн
Для скорости есть индексы. Все от них и зависит.
Без индексов, самая быстрая бд - это файловая система.
Для файловой системы надо движок писать, если бы я этим хотел заниматься, то так и сделал бы
Нет. Скорость доступа прямопропорционально затратам по памяти. Если в СУБД ты используешь индексы, и чем больше индексов, тем выше и скорость и оверзед, то же самое и с ФС. Отображай свои структуры на структуры фс и никакой движок кроме чтения списков файлов\самих файлов и записи файлов\создвния тебе не нужен. Но и затраты по памяти будут очевидно выше.
ФС это тоже БД. Иерархическая БД. У нее уже есть движок. Без движка и нет никакой ФС.
>тем выше и скорость и оверхед,
тем выше скорость доступа и оверхед по памяти*
Чем может обернуться создание индексов для всех возможных комбинаций столбцов, кроме увеличения потребляемого дискового пространства?
огромными потерями быстродействия потому, чтоперестройка индексов это как процессорное время так и ИО с твоих хардов
Но перестройка будет производиться только при изменении данных?
Изменении и добавлении, да.
Сап програмач, помоги. Пишу сайтик с MSSQL. Есть таблица, в которой нужно хранить две JSON строки, притом что одна из них может быть около 5-10 тысяч символов. Что-то мне подсказывает что просто хранить их в столбцах не вариант ( размер может быть и ещё больше). Подскажите как всё сделать хорошо.
Почему 4 и 5 нормальные формы почти нигде не рассматривают?
Они оторваны от БТ.
От чего?
>От чего?
От требований бизнеса.
От БТ.
От Бугурт-Треда
Посоны, помогите с запросом PostgreSQL:
Есть одна база, ЕОБ, в ней одна таблица а в ней 100 миллионов строк-фраз. Мне нужно делать выборку по длииииинному списку тысяч на 10-20-30 из неё. То есть мне нужно делать выборку по данным из другой таблицы единоразово. Я сделаю индексацию, но не шарю в синтаксисе. Я чета делал JOIN - он мне выдает полные совпадения - типа apple - apple, а мне нужно apple -> green apple, karasique appletini и т.д. (нужен только итоговую выборку сохранить в файл).
Короче, выручайте - скину на мороженку. А то я с grep'ом буду ждать до морковкиного заговенья. Знающие люди пишут, что нужно колдовать с функциями - т.е. я так понял, циклом пробегаться по второй таблице и чекать первую.
Есть одна база, ЕОБ, в ней одна таблица а в ней 100 миллионов строк-фраз. Мне нужно делать выборку по длииииинному списку тысяч на 10-20-30 из неё. То есть мне нужно делать выборку по данным из другой таблицы единоразово. Я сделаю индексацию, но не шарю в синтаксисе. Я чета делал JOIN - он мне выдает полные совпадения - типа apple - apple, а мне нужно apple -> green apple, karasique appletini и т.д. (нужен только итоговую выборку сохранить в файл).
Короче, выручайте - скину на мороженку. А то я с grep'ом буду ждать до морковкиного заговенья. Знающие люди пишут, что нужно колдовать с функциями - т.е. я так понял, циклом пробегаться по второй таблице и чекать первую.
Если я тебя правильно понял, попробуй:
select
a.yoba_name,
b.yoba_name
from yoba1 a
join yoba2 b lower(b.yoba_name) like '%'||lower(a.yoba_name)||'%'
where a.yoba_name in ('apple', 'double', 'triple')
Lower нужен если у тебя в разном регистре данные, если это так, то индекс по yoba2.yoba_name нужно строить по lower(a.yoba_name) и в запросе к полю обращаться с функцией, указанной в индексе.
Для yoba1 тоже строишь индекс по yoba_name, если необходимо - с lower.
Если значения гарантировано уникальные - делай уникальные индексы, будет быстрее.
>join yoba2 b lower(b.yoba_name) like '%'||lower(a.yoba_name)||'%'
join yoba2 b on lower(b.yoba_name) like '%'||lower(a.yoba_name)||'%'
Братишка, спасибо. Но мне нужно не по apple - это я для примера же привел. Мне нужно вообще по всем значениям из второй таблицы. Во второй таблице искомые слова, а в первой большой многомиллионный список, откуда выбираем. Вот так.
Ну так тебе анон и написал.
В одной таблице у тебя данные, во второй - справочник с нужными значениями.
И по его запросу ты получишь все строки из первой таблицы, которые так или иначе содержат в себе какое-либо слово из второй таблицы.
Только учти, что в итоге ты для строки "Вася и Петя" и наличия во второй таблице строк "Вася" и "Петя" получишь дубли.
Потому тебе нужно что-то вроде SELECT DISTINCT a.yoba_name FROM ...
> Потому тебе нужно что-то вроде SELECT DISTINCT a.yoba_name FROM ...
b.yoba_name, фикс
А чтобы у тебя был не по яблоку поиск, просто убери фильтр - сотри строку с where ...
Спасибо, сейчас протестирую
Не особо шарю в сукиэле и базах данных так что помогите пожалусто. Тип есть 2 бд, в одной список стульев в другой список хуёв, хуи разные все кароч, и допустим у каждого стула свой набор хуёв, собсна их нада записать в бд, а как блять? У меня в голове только к полю id и name добавить поле dicks_id где через запятую указать id хуёв.
Перекот себе делайте, я не буду
как хранить оценки, например, по шкале от 1 до 10? на ум приходит создать таблицу с возможными оценками, но это как будто костыль какой-то ебучий. как сделать шобы нельзя было ввести число больше 10, меньше 1? postgresql
На самом деле справочник оценок в отдельной таблице - нормальное решение.
Можно сделать историчность оценок - например, оценка "1" действовала с 01.01.1900 по 12.12.2017, а оценка "3+" - с 01.01.2005 по 02.02.2013.
Можешь сделать так, чтобы по физкультуре, к примеру, были 10-балльные оценки, а по музыке - 3 балльные.
А можешь просто check_constraint сделать типа yoba_mark between 0 and 10.
Но в этом случае будь готов к всяким граблям, которые неизбежно вылезут если систему оценок нужно будет хоть немного модифицировать/расширить.
понял-принял, спасибо.
хочу скопировать чужую бд, для этого мне нужно запустить дамп этой бд (не уверен, что правильно называю, короче .sql файл, который создает таблицы и инсертит данные в ниХ) , а там везде вместо одинарных кавычек ' стоят ` . как быть? postgres
Оп ?, шапка заебись, но ящетаю в ней не хватает учебников для вкатывальщиков меня.
Есть какие нибудь идеи на этот счет?
Тред перечитай.
короче похуй, написал скриптфиксящий это говно
Сильно ли SSD увеличит скорость чтения из базы? Прямо пропорционально увеличению скорости диска?
Оперативка играет роль?
Оперативка играет роль?
Я думаю, что оба ответа - "да".
Первый: это логично, черт возьми. Чтение с диска - всегда боттлнек для базы, потому тот же оракл выделяет у себя в SGA горячие блоки, чтобы не читать лишний раз с диска.
Второе: определенно. Сервер же должен считать данные и как-то их сохранить, чтобы показать тебеу меня так коллега случайно съел 340 гигов оперативы. Или же сохранить промежуточные данные для выполнения запроса.я, почти случайно, таким образом съел 304 гига оперативы
У меня база предполагается 60 гигабутов, самый максимальный запрос по индексам сможет выбрать 6 млн строк для обработки, это 6 гб примерно, так что оперативка вряд ли забьется, если хоть 8 гб будет
Кстати раз уж на то пошло, где можно облачный хостинг купить в оплатой по потребляемым ресурсам?
и чтоб ссдшки быстрые были. Или тут только дедик?
Привет, анон. Вопрос о противостоянии производительности и поддержки кода в oracle pl/sql.
Есть цикл, на каждом шаге которого вызываются процедуры, которые создают записи в определенных таблицах, каждая процедура работает со своей таблицей. Ключи, по которым можно найти созданные записи определяются на каждой итерации.
В конце итерации нужно проверить, создалась ли хотя бы одна запись хотя бы в одной таблице. Можно тупо делать select count(1) from t where rownum = 1 and key_val = :0 для каждой таблицы.
Но я реализовал процедуры таким образом, что одним из исходящих параметров является флаг, который каждой процедурой переводится в true, если была создана хотя бы одна запись своей таблицы.
В каждый вызов процедуры передается одна и та же bool-переменная, назовем ее b. Т.е. в начале итерации b=false, любая процедура может сделать b=true. В конце итерации проверяем значение b.
Насколько мой подход оправдан? С одной стороны не нужно делать лишние селекты на каждой итерации, хоть и быстрые, с другой приходится вводить "глобальную" по отношению к процедурам переменную.
Есть цикл, на каждом шаге которого вызываются процедуры, которые создают записи в определенных таблицах, каждая процедура работает со своей таблицей. Ключи, по которым можно найти созданные записи определяются на каждой итерации.
В конце итерации нужно проверить, создалась ли хотя бы одна запись хотя бы в одной таблице. Можно тупо делать select count(1) from t where rownum = 1 and key_val = :0 для каждой таблицы.
Но я реализовал процедуры таким образом, что одним из исходящих параметров является флаг, который каждой процедурой переводится в true, если была создана хотя бы одна запись своей таблицы.
В каждый вызов процедуры передается одна и та же bool-переменная, назовем ее b. Т.е. в начале итерации b=false, любая процедура может сделать b=true. В конце итерации проверяем значение b.
Насколько мой подход оправдан? С одной стороны не нужно делать лишние селекты на каждой итерации, хоть и быстрые, с другой приходится вводить "глобальную" по отношению к процедурам переменную.
Оправдан, нормальный подход.
Ты же переменную при вызове передаешь, значит, она не глобальная.
Есть ли смысл большую таблицу (несколько млн) в мускуле разбить на две, условно говоря в 1 мужчины, в 2 женщины или просто индекса достаточно?
Две таблицы - это трэш.
Если поле неселективное (мужчины/женщины ~50/50) то индекс не нужен.
Спокойно все складывай в одну таблицу.
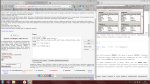
Всем добрый вечер я сегодня завалил экз по бд в своей шараге и решил быренько догнать программу, прошёл курс на sololearn, почитал лекции и решил поделать задания, на которые весь семестр забивал болт. И вот собсна одно из заданий, если кто-нибудь сможет мне объяснить почему нихрена не работает, буду сверхблагодарен
Ну, во-первых, в последнем подселекте у тебя фром склеился с ауткамом.
А во-вторых - в первом селекте у тебя два поля, а в последующих - по одному. Как ты собираешься сделать юнион? Список полей и их типы должны соответствовать/быть приводимы друг к другу.
В-третьих - у тебя в третьей строчке стоит точка с запятой, которая не даст захватить кусок с запросами ниже.
В-четвертых - select point, date, from.
Не хочешь после даты указать ещё одно поле или убрать запятую? Вот у тебя и парсер с ума сходит.
Спасибо за ответ, а каким способом мне тогда лучше объединить эти таблицы если не юнионом? по заданию, если я не ошибаюсь нужно вывести inc и out вдобавок к point и date
А что ты будешь делать, если у тебя был приход и расход в один день?
Это full join, тут по-другому никак. Тебе нужны все даты и суммы из таблицы приходов, а вместе с ними - и все даты и суммы и таблицы расходов. Здесь тебе поможет nvl.
Честно говоря, я до sql-ex с SQL общался только в универе (не ходил на пары и списал на экзамене). Решил нужное количество задач + дополнительные (не с сайта) и работаю разработчиком, лул.
Аноны, есть два дампа одной и той же базы данных, с разнице в 3 недели.
Структура таблиц не изменялась за это время, только добавлялись новые данные.
Но с первым дампом всё работает отлично, а со вторым приложение крашится т.к. отсутствуют какие-то данные.
Вопрос:
Будет ли иметь смысл накатываение старого дампа потом нового(с дописыванием новых данных)? Если да, то как такое провернуть(какой командой ну или хотя бы как правильно спросить у гугла)?
Ну и накатить просто старый дамп и расслабиться я не могу т.к. за 3 недели появилось много новых данных.
p.s. PostgreSQL 9.6, Debian 9
Структура таблиц не изменялась за это время, только добавлялись новые данные.
Но с первым дампом всё работает отлично, а со вторым приложение крашится т.к. отсутствуют какие-то данные.
Вопрос:
Будет ли иметь смысл накатываение старого дампа потом нового(с дописыванием новых данных)? Если да, то как такое провернуть(какой командой ну или хотя бы как правильно спросить у гугла)?
Ну и накатить просто старый дамп и расслабиться я не могу т.к. за 3 недели появилось много новых данных.
p.s. PostgreSQL 9.6, Debian 9
Накати параллельно со старой работающей новую и просто напиши миграции из всех таблиц, в которых появились данные, из новой неработающей бд в старую работающую.
Дело в том, что таблиц там 610, и данные обночвились в 99% из них, поэтому ищу +/- готовый инструмент.
И, да, я не спец в БД и редко пишу что-то сложнее обычных селектов/инсертов и прочего.
Но я готов изучать литературу/документацию, главное знать бы какую и как искать
>Приложение крашится.
Ну так вопросы к приложению, а не к бд. Значит, какие-то говноданные там, или приложение как-то не умеет с новыми данными работать.
Дело в том, что приложение одно и тоже(CRM система).
На продакшен-сервере оно отрабатывает корректно с той базой данных, которая есть.
А вот это же приложение на дампе - падает, что на новом, что на старом(как оказалось, я просто тестил хуйово, и оно всё же падает, просто без глобальной ошибки, а вылазит небольшое окно с инфомрацией, после долгой загрузки), в одном и том же месте.
К БД продакшен-сервера мне не дали подключиться и протестить с ней.
А я и хуй забил.




Тут мы решаем ультраважные вопросы о том, как правильно хранить динамические атрибуты сущностей: в полях или в строках,
Рассказываем, как работаем аналитиками и мечтаем стать разработчиками,
Строим АНАЛИТИЧЕСКИЕ отчеты в экселе, выгружая по миллиону строк, а потом фильтруя,
Дружно не понимаем, ЗОЧЕМ ЖИ НУЖИН ОЛАП, ЕСЛИ И ТАК ВСЕ РАБОТАЕТ ЗАЕБИСЯ,
Ищем ошибки в аббривиатурах MDX DMX XMLA,
Доебываемся до эс - ку - элей наших же потенциальных конкурентов
>Select id from tbl_table_with_id where id = (select max(id) from tbl_table_with_id)
>ЧТО НЕ ТАК-ТО У МЕНЯ?
Удивляемся, как за знания, приобретаемые за 4 месяца на sql-ex, могут платить по 100к, и бугуртим, что ниасилили и 100к не получаем.
А так же:
Постгре или постгрес?
Май эс ку эль или мускуль?
Эс ку эль или сиквел?
В общем, это очередной баз данных тред, поехали!
Награда светит не посмертною медалью, отнюдь
Это храм старого формата, так предали огню
И скоптили небо старики, что слышны с Невской реки
Мы видим дым от костра - "Да здравствуют базовики!"
ПРЕДЫДУЩИЙ:
#sql #бд #базы данных